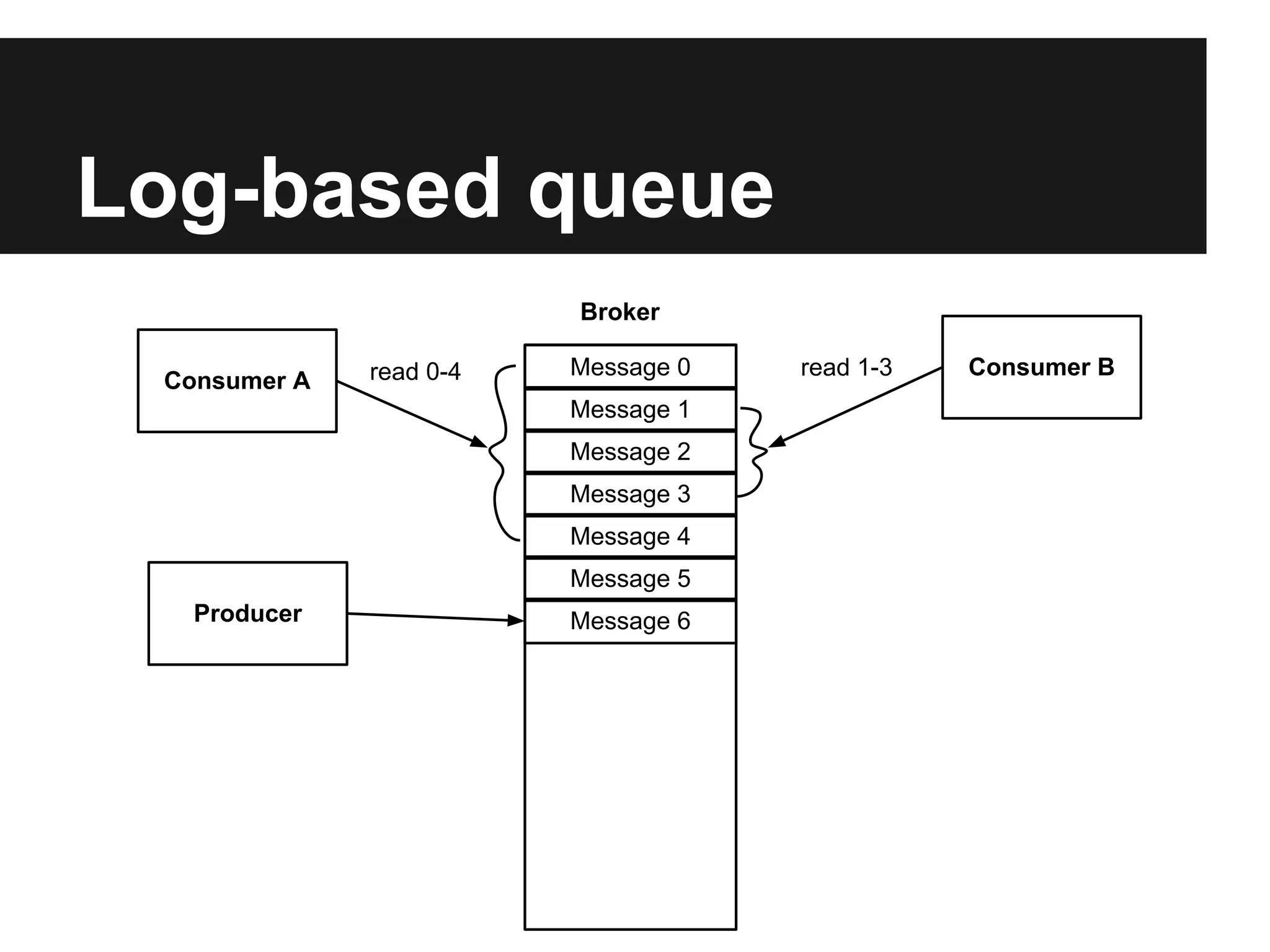
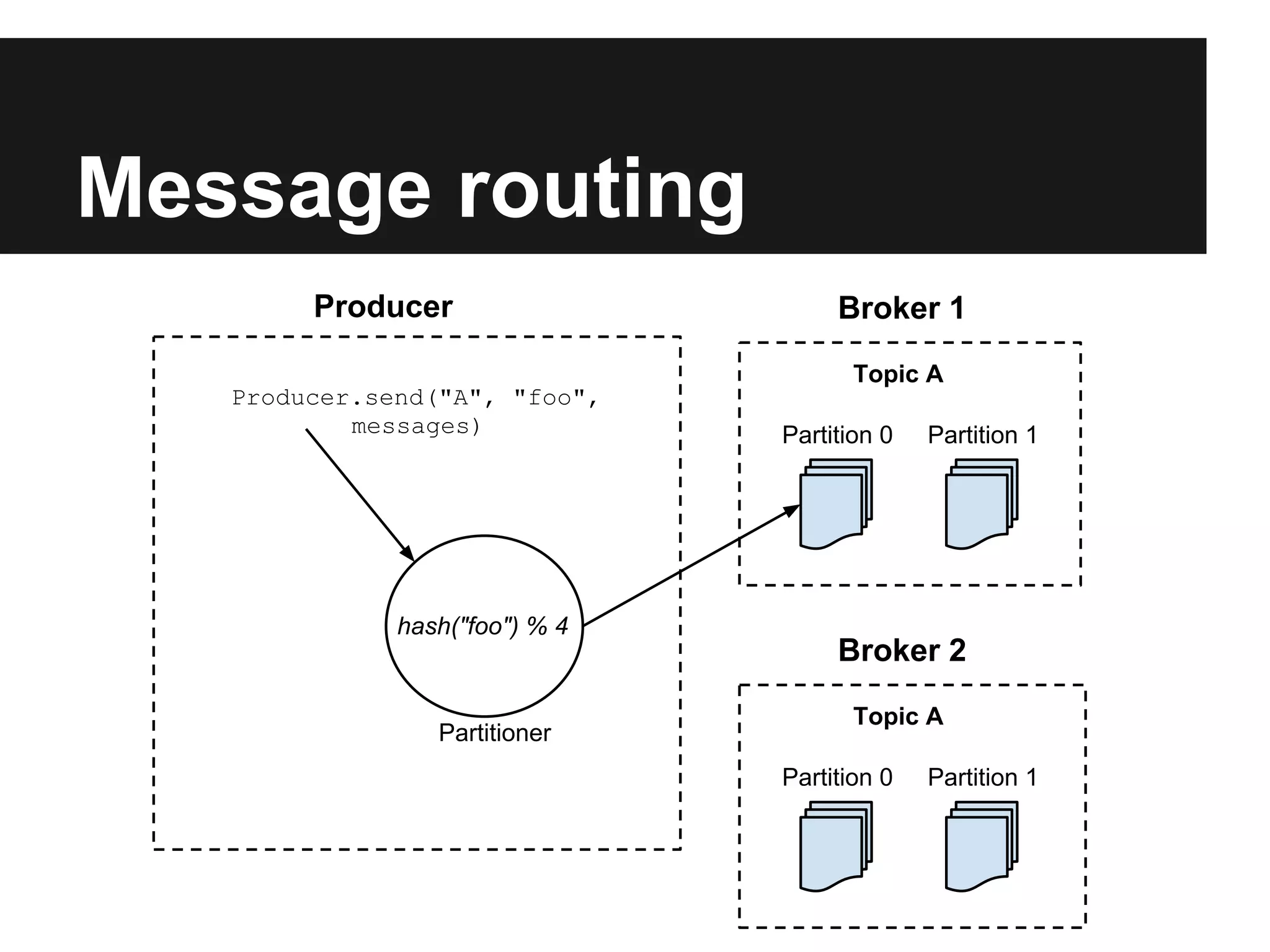
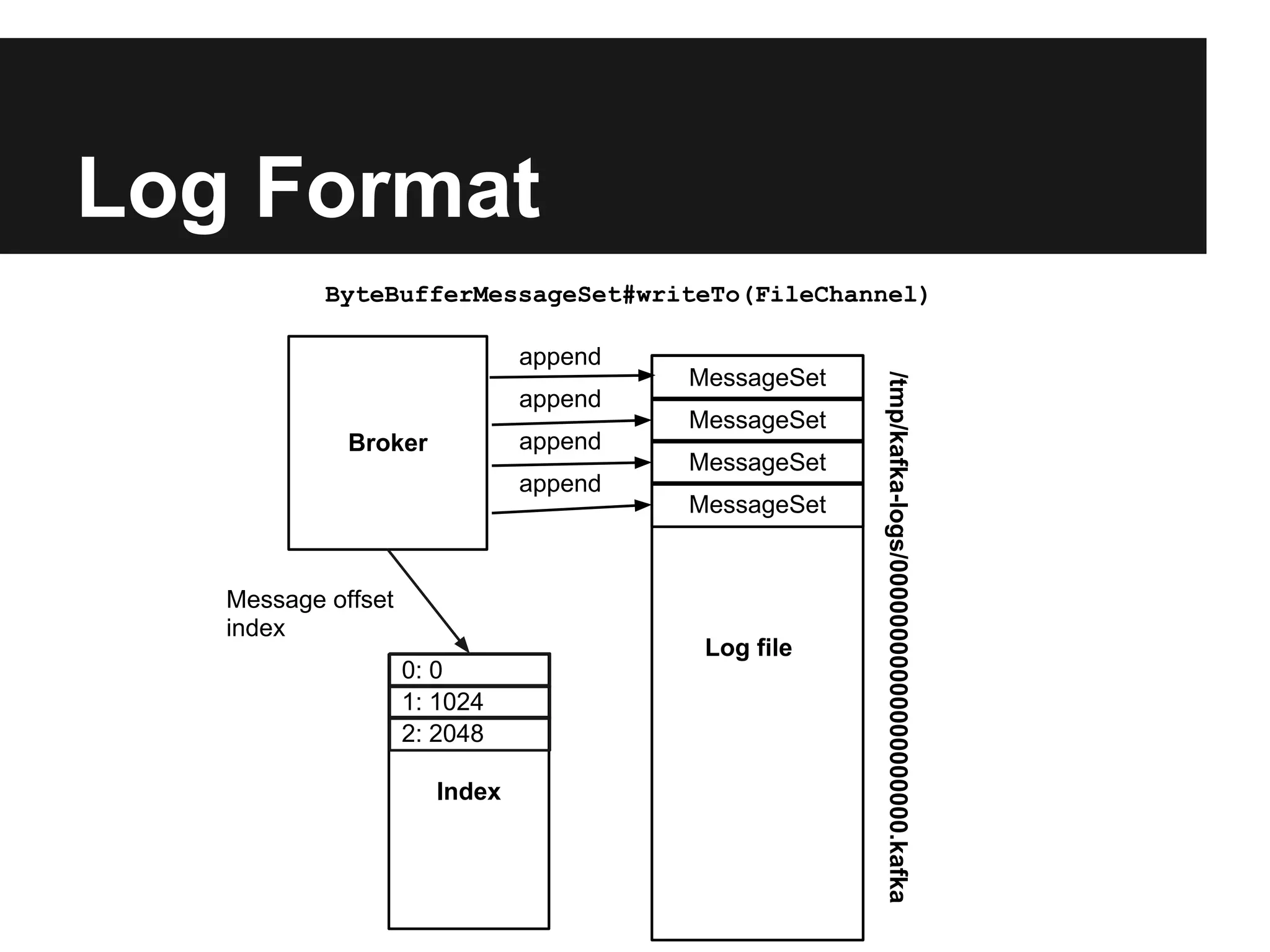
Apache Kafka is a distributed publish-subscribe messaging system that allows both publishing and subscribing to streams of records. It uses a distributed commit log that provides low latency and high throughput for handling real-time data feeds. Key features include persistence, replication, partitioning, and clustering.



















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















