Downloaded 58 times


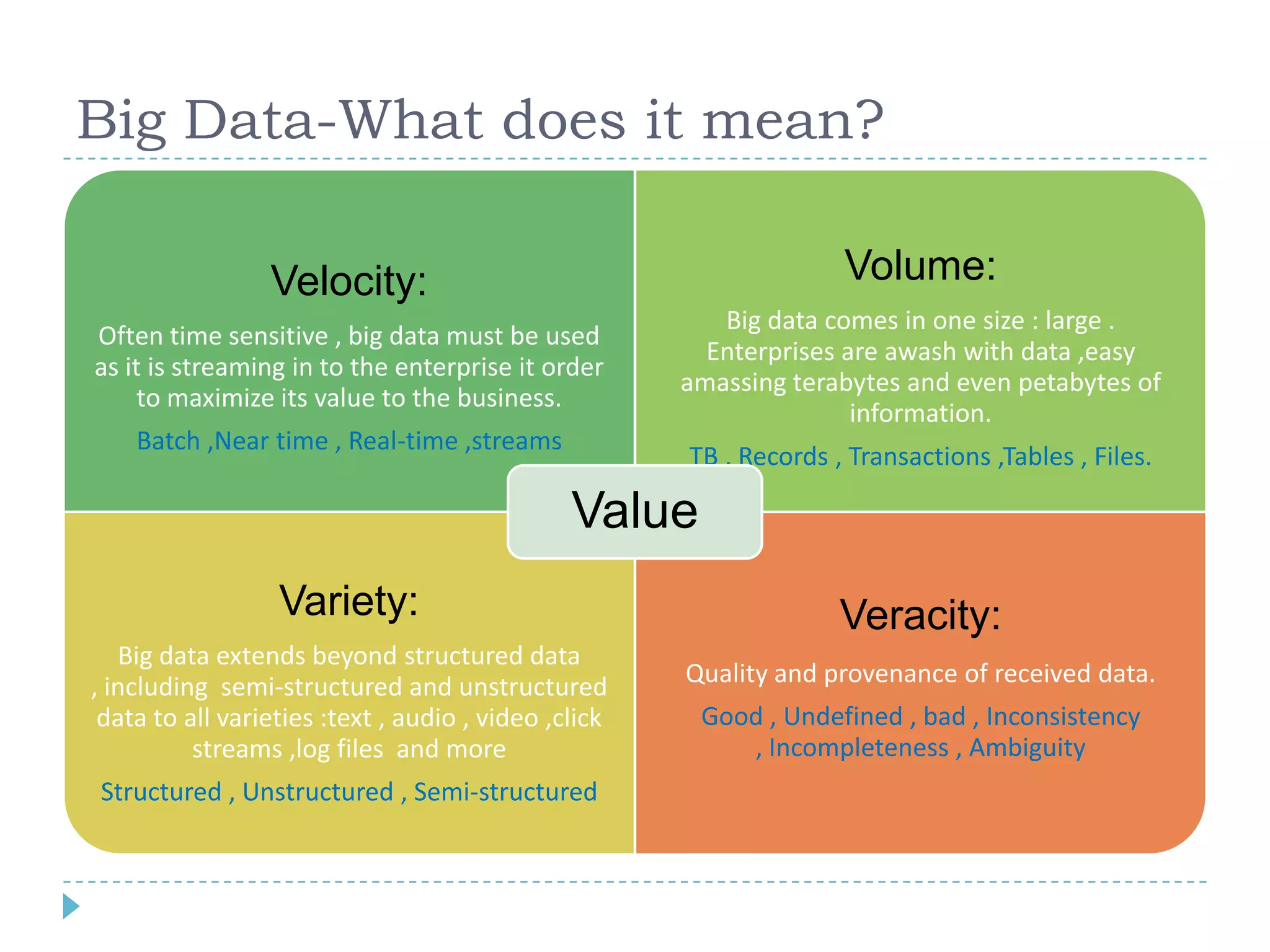
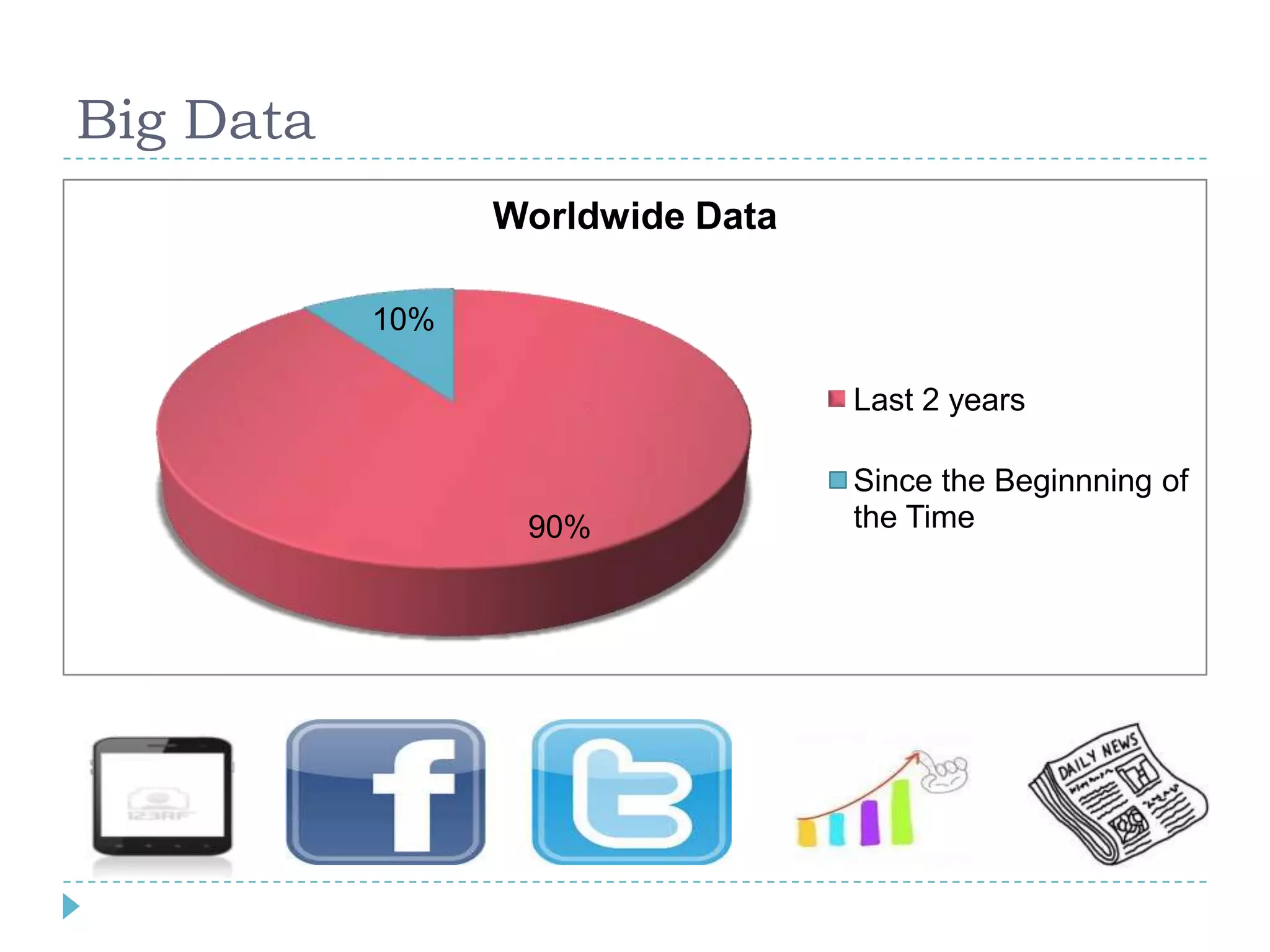

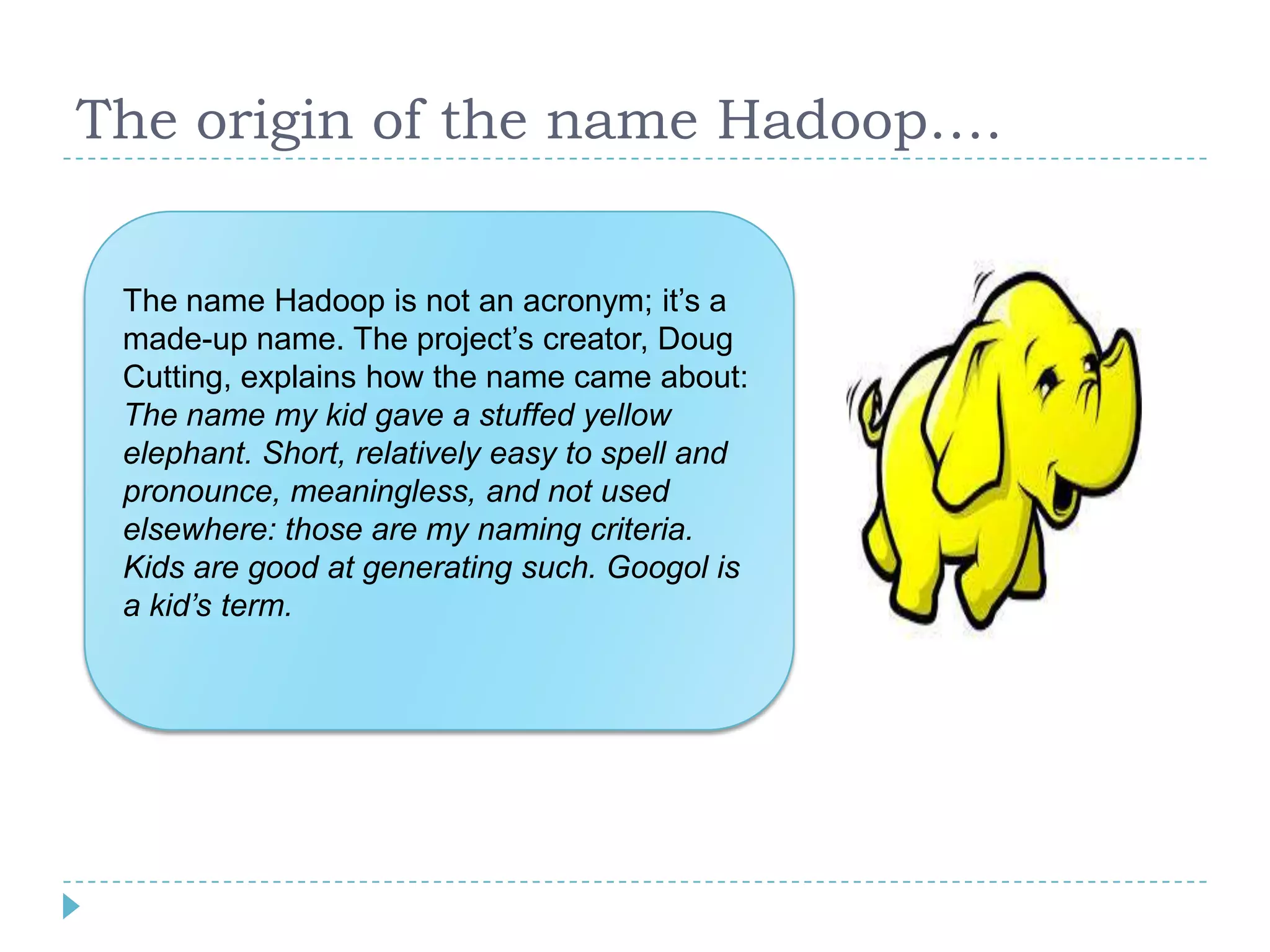
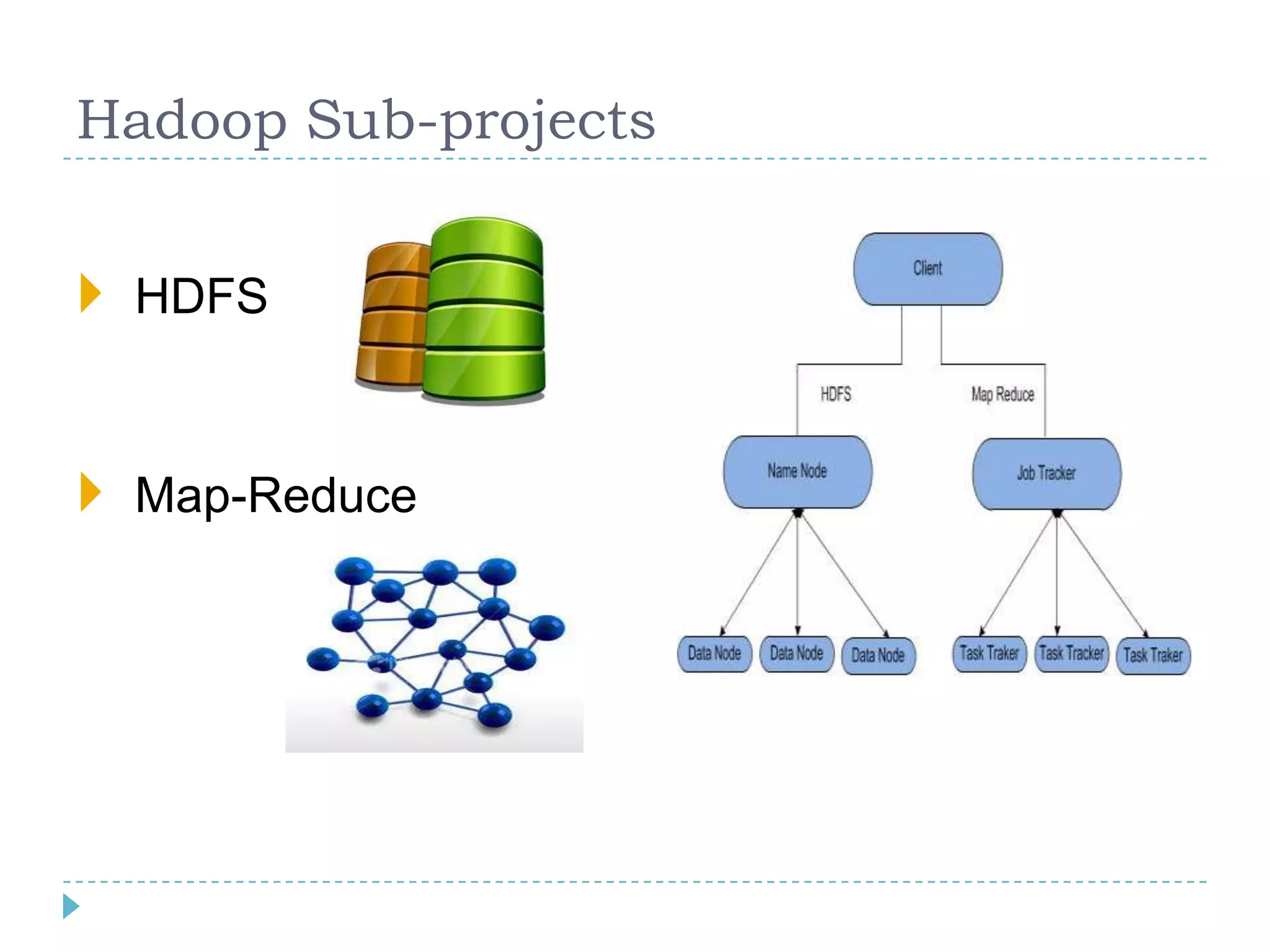
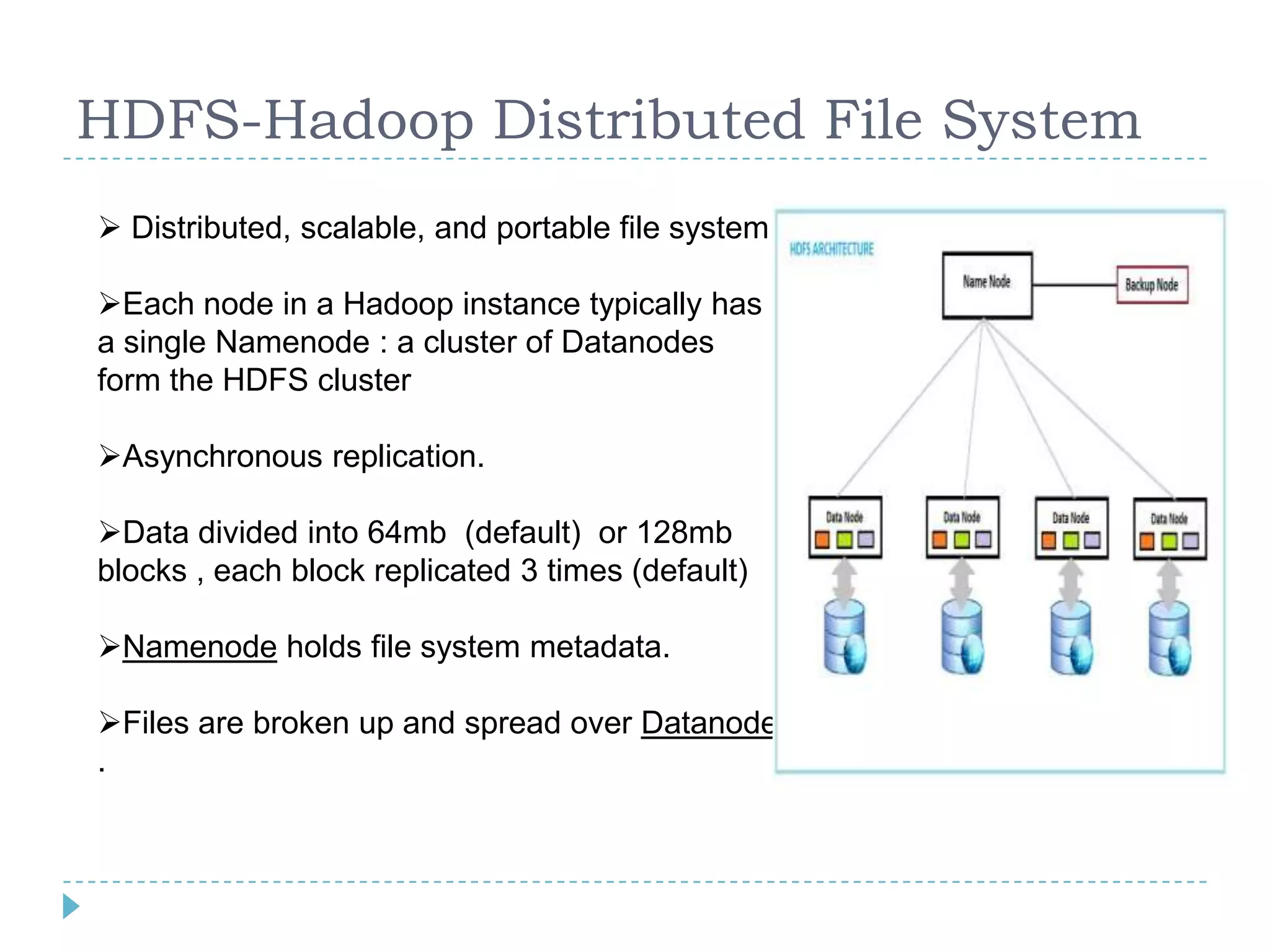
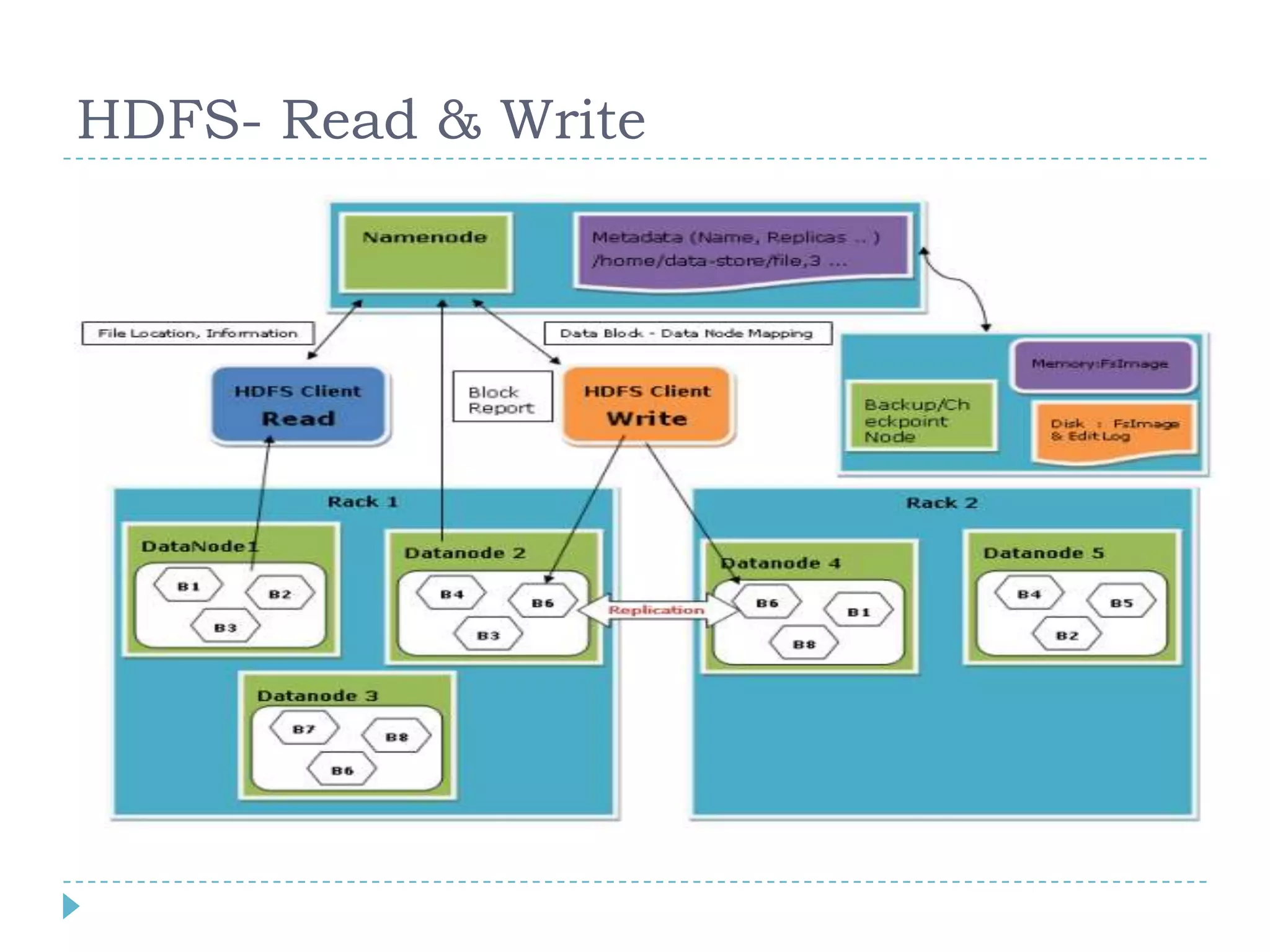
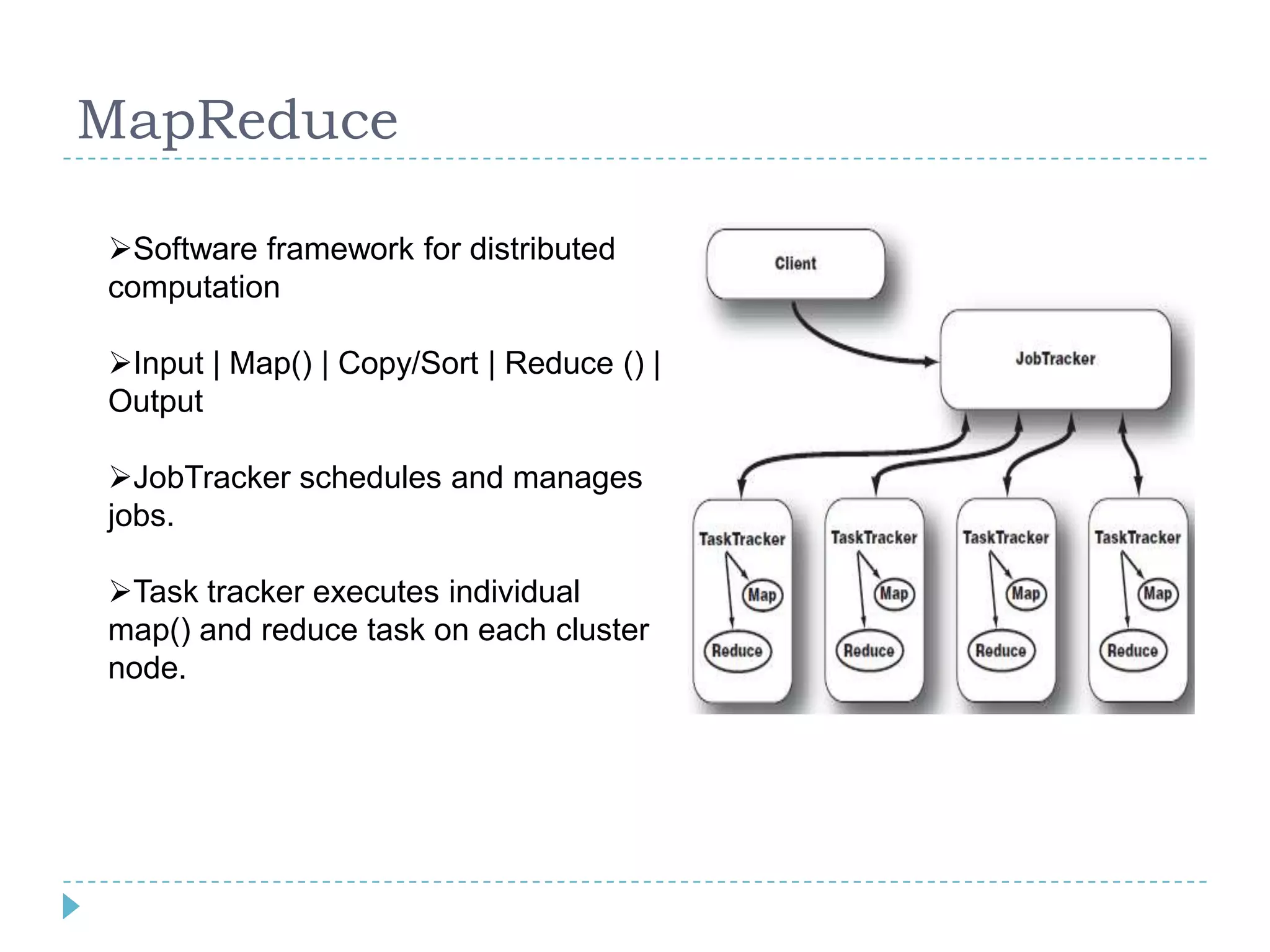
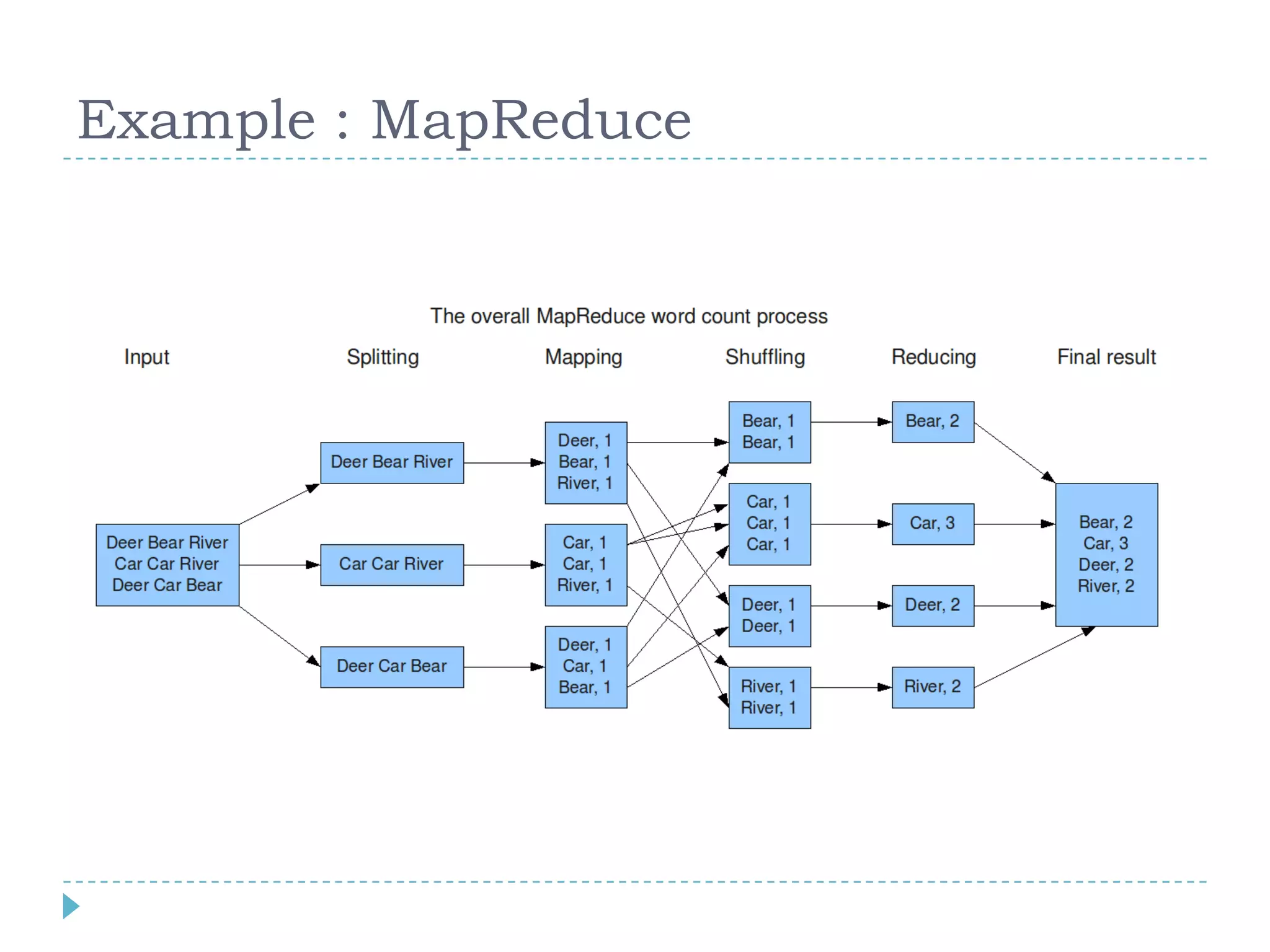
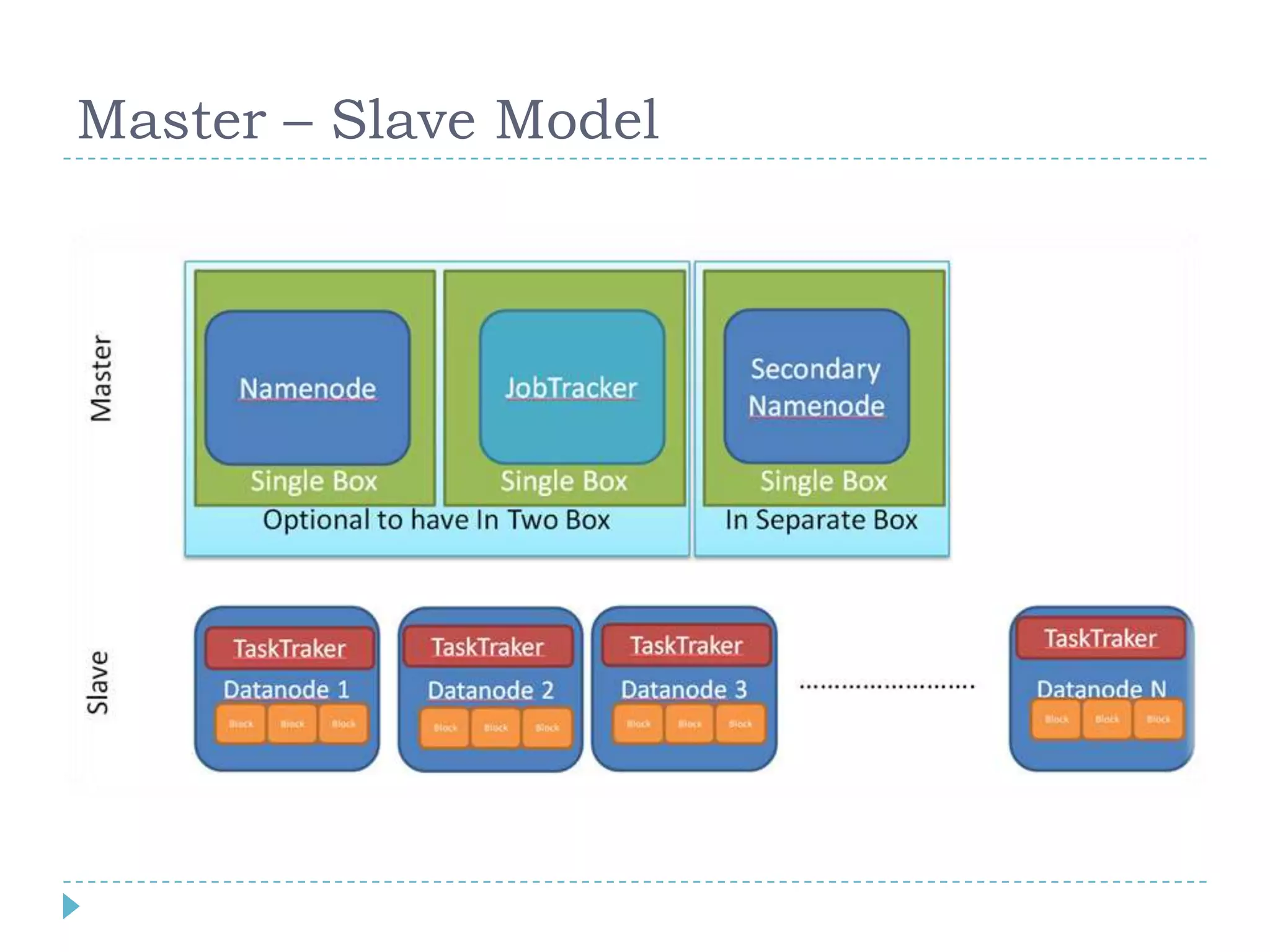
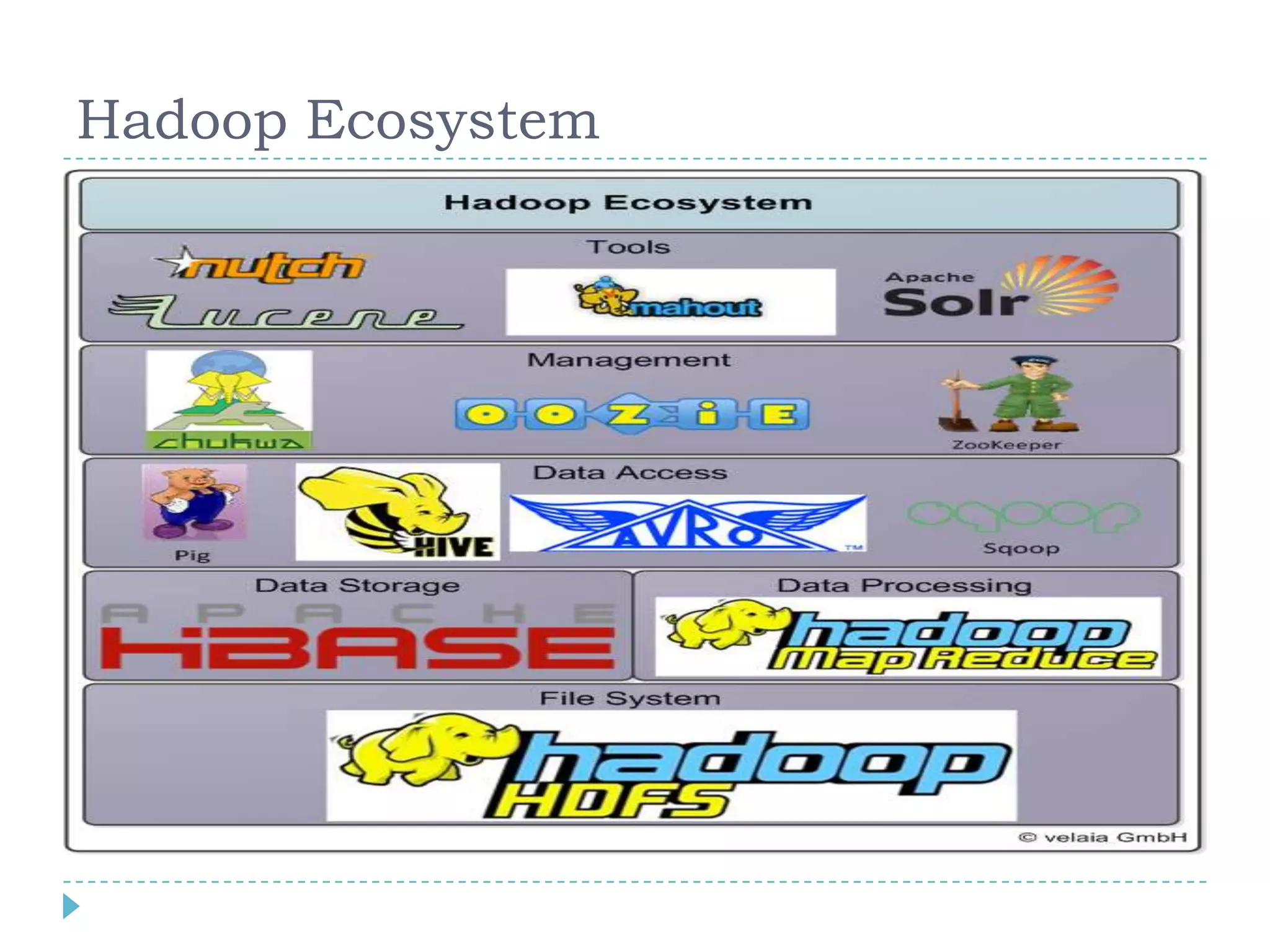

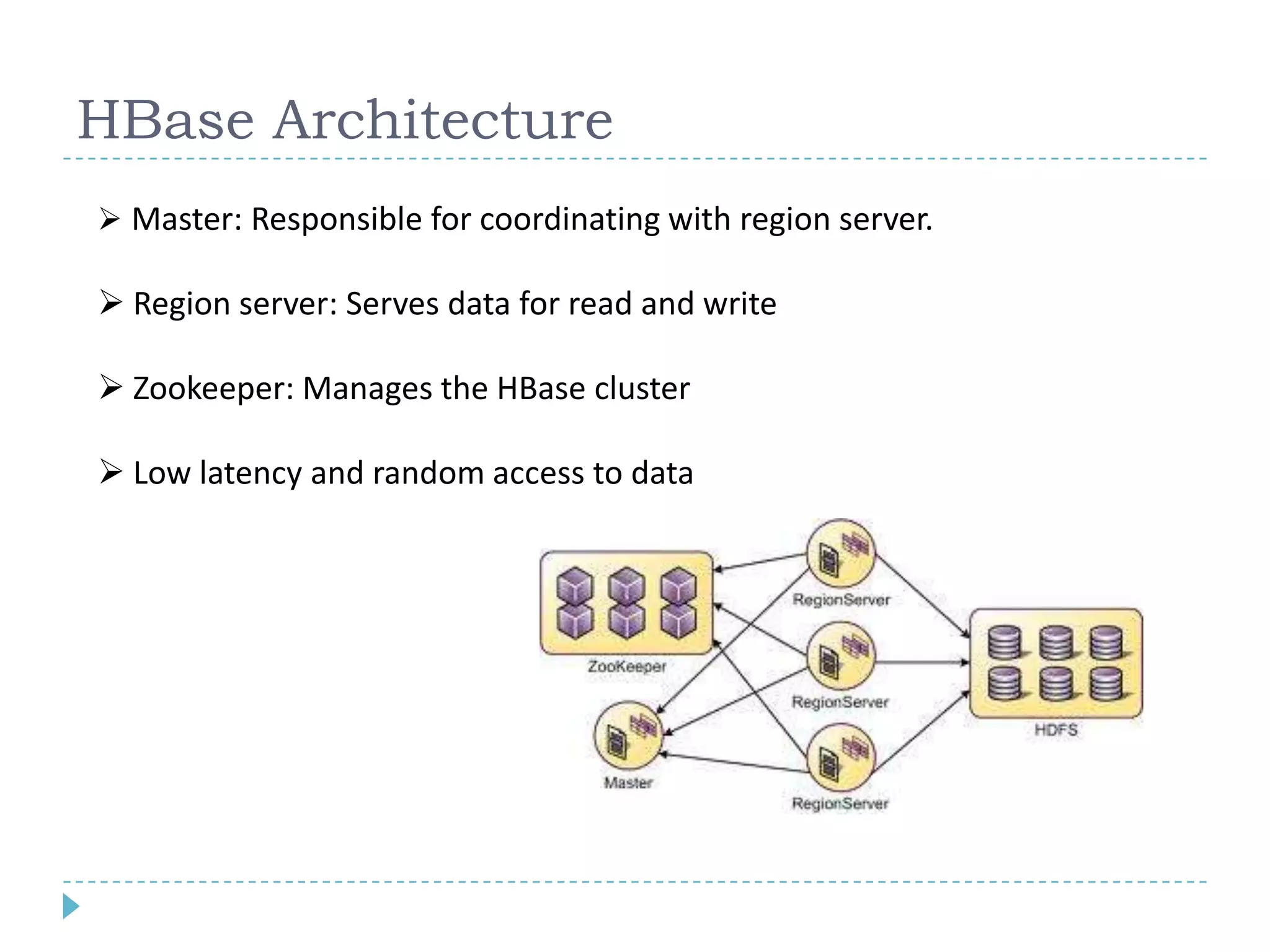

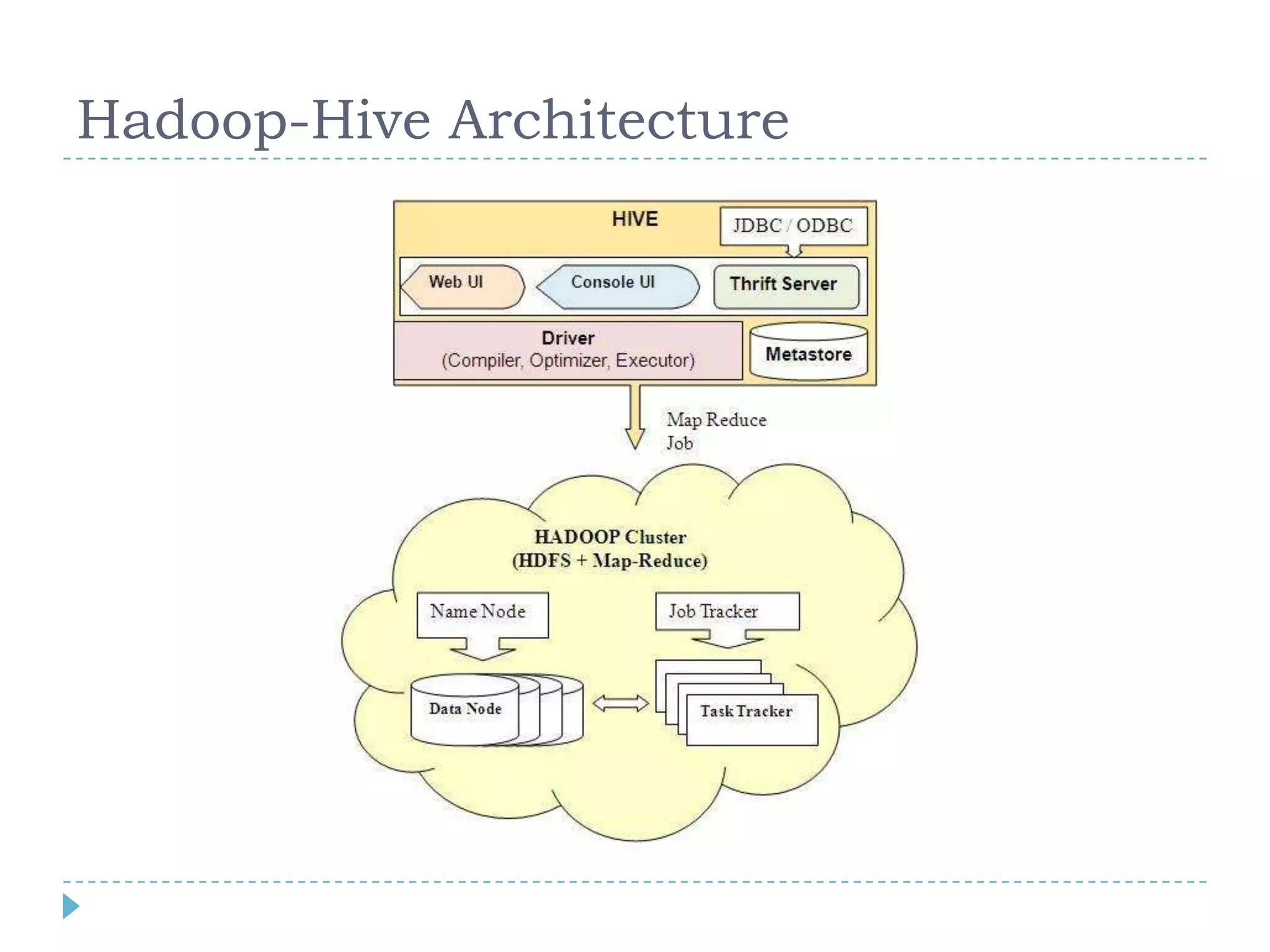
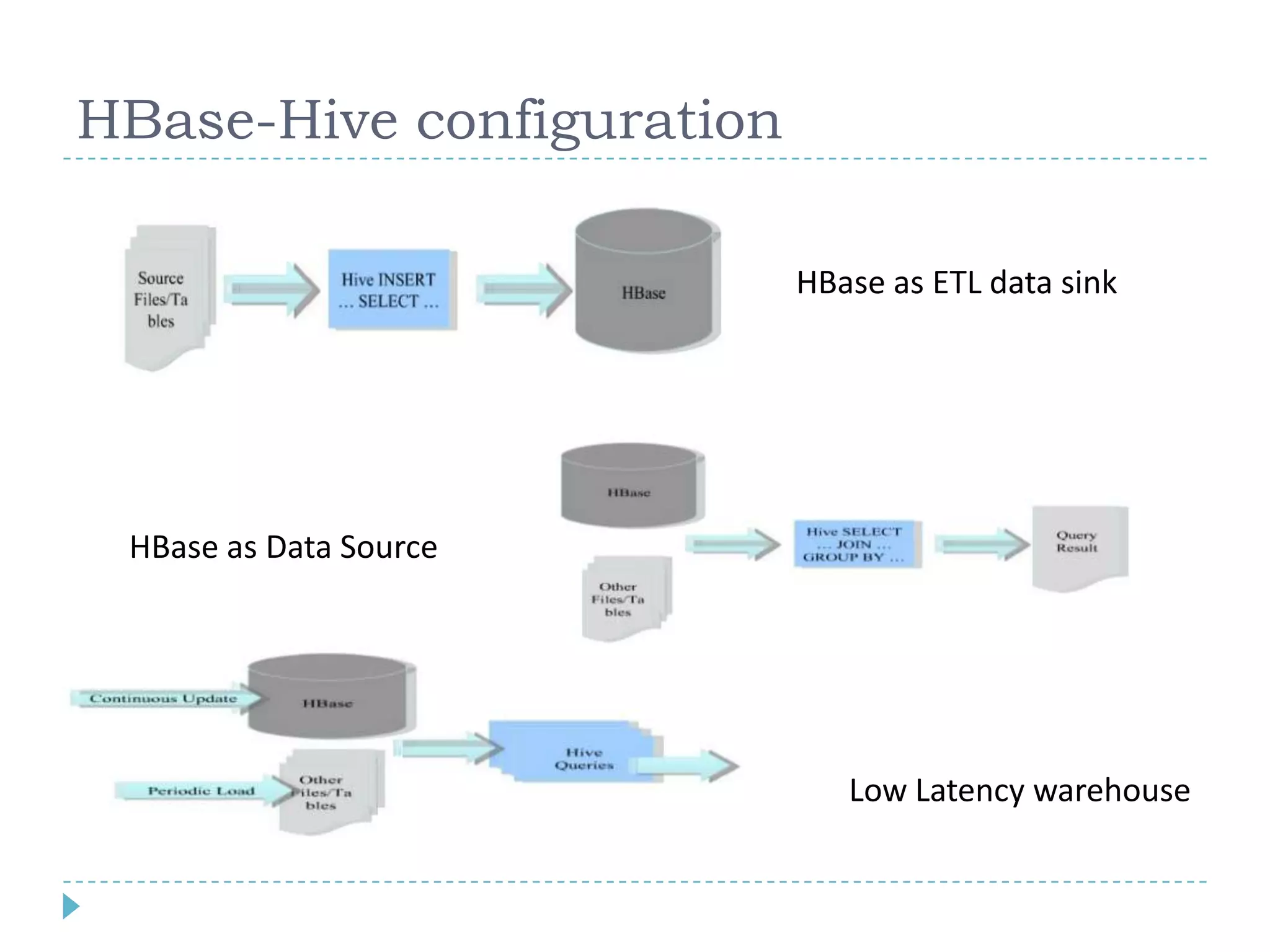
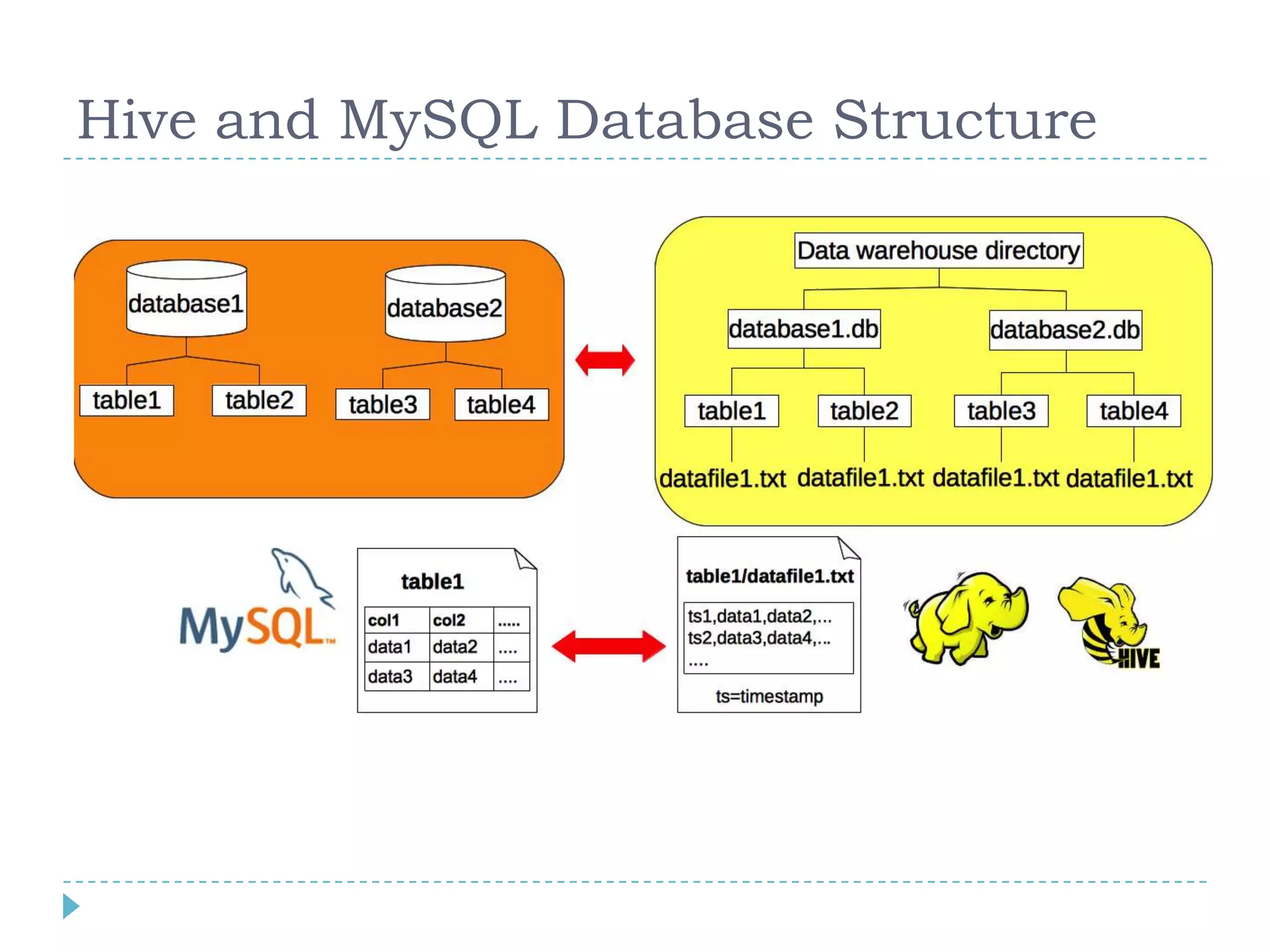






Big data refers to large volumes of data that are diverse in type and are produced rapidly. It is characterized by the V's: volume, velocity, variety, veracity, and value. Hadoop is an open-source software framework for distributed storage and processing of big data across clusters of commodity servers. It has two main components: HDFS for storage and MapReduce for processing. Hadoop allows for the distributed processing of large data sets across clusters in a reliable, fault-tolerant manner. The Hadoop ecosystem includes additional tools like HBase, Hive, Pig and Zookeeper that help access and manage data. Understanding Hadoop is a valuable skill as many companies now rely on big data and Hadoop technologies.



































































