Downloaded 96 times


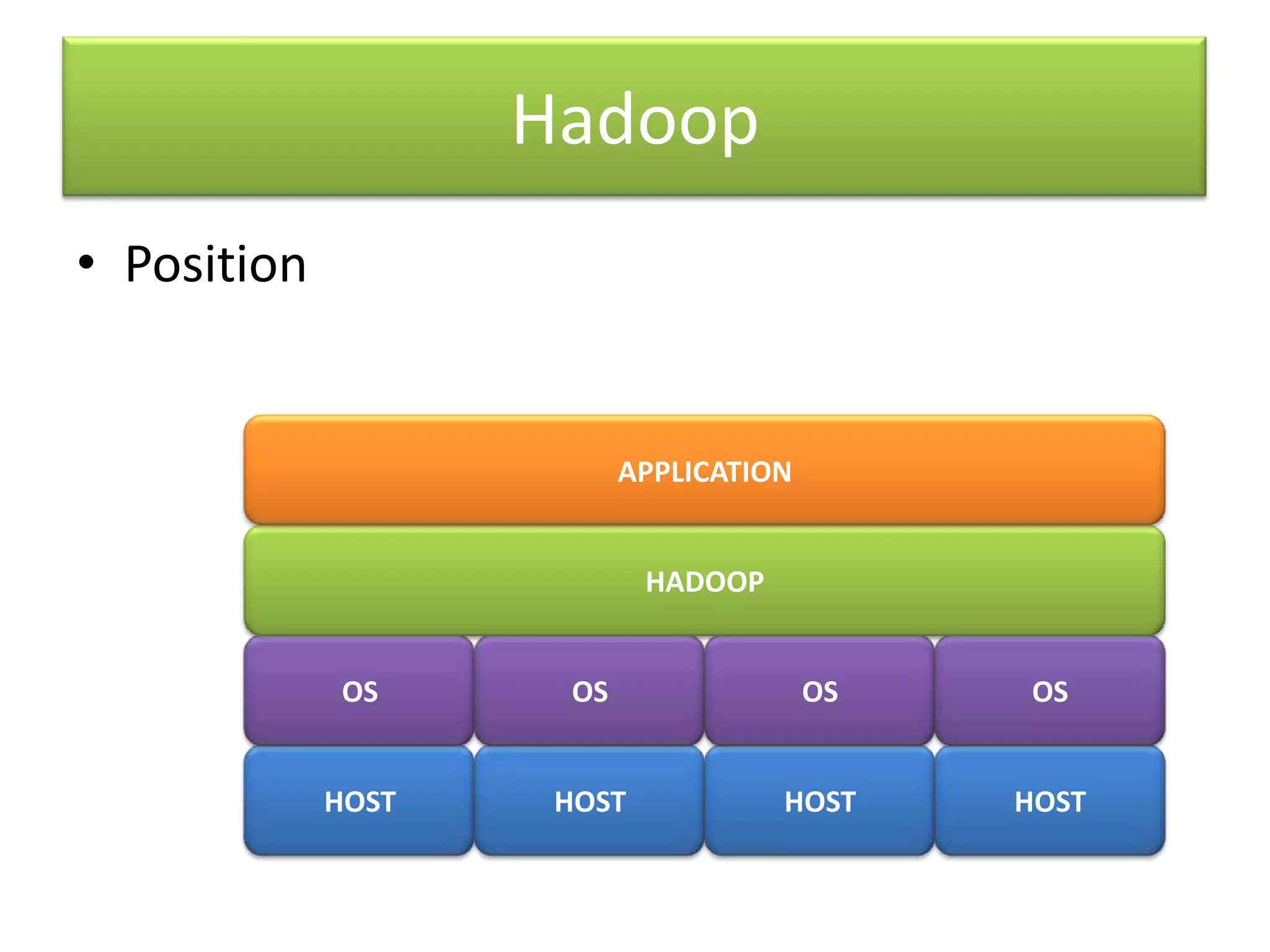





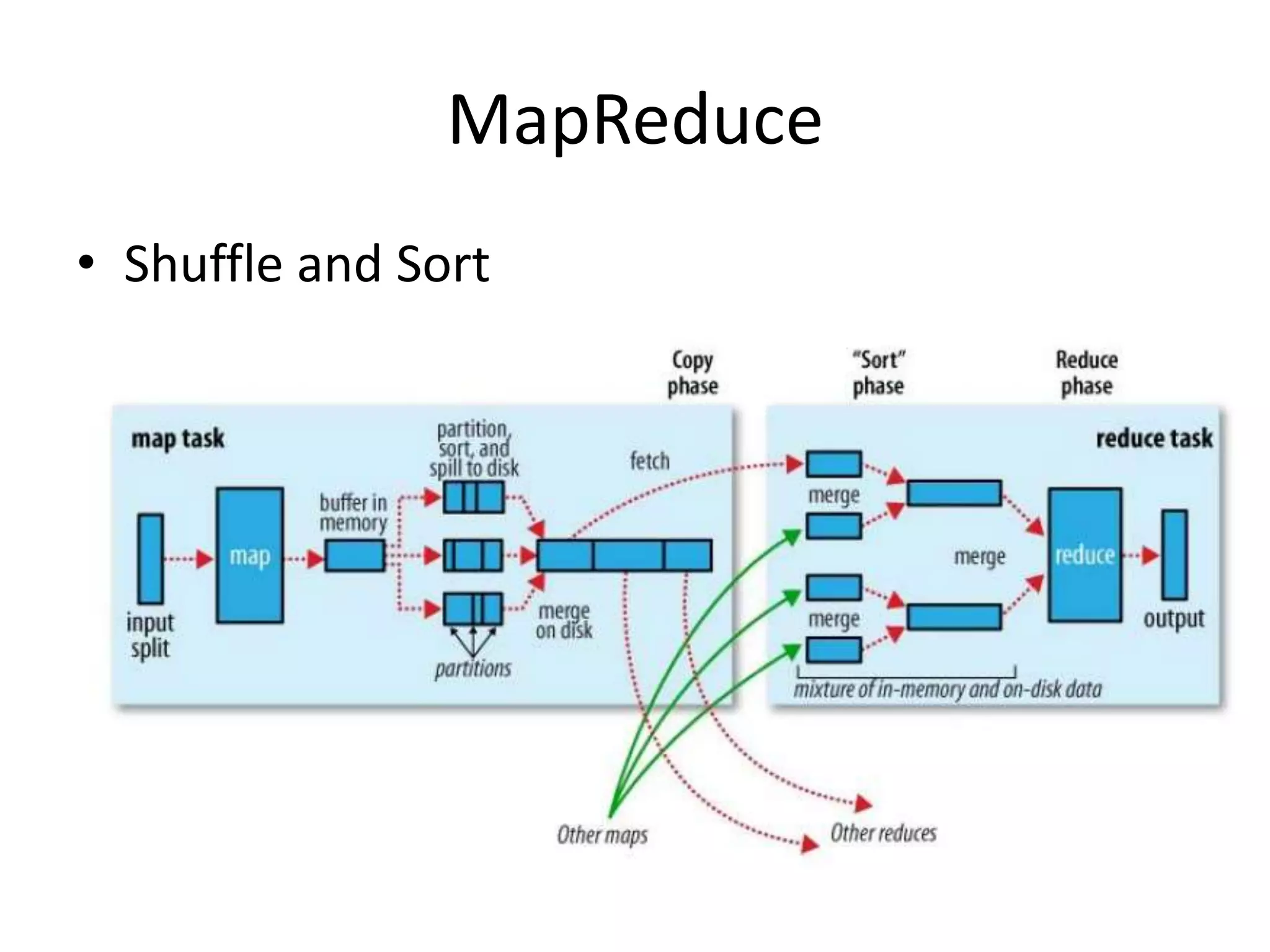



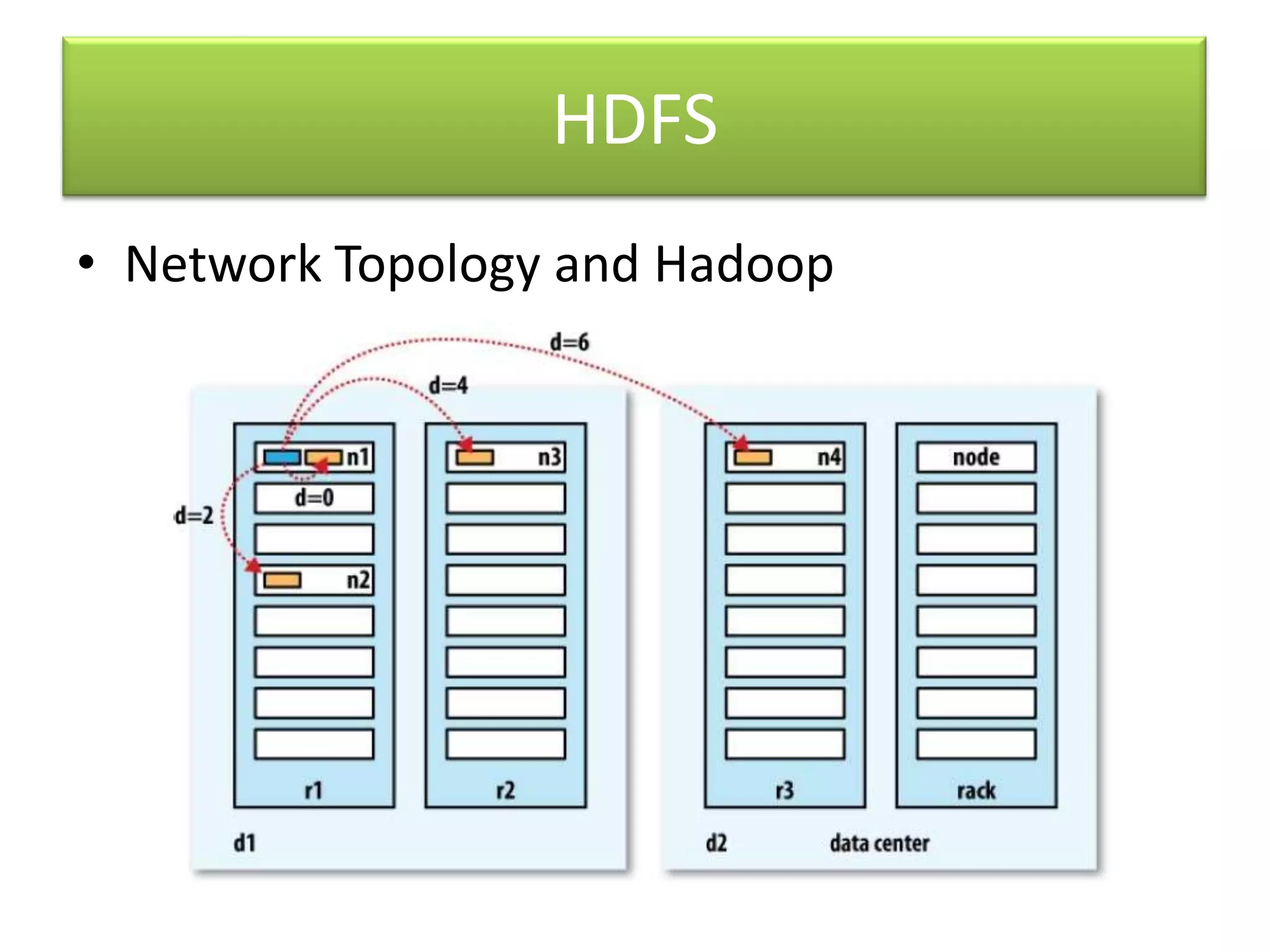
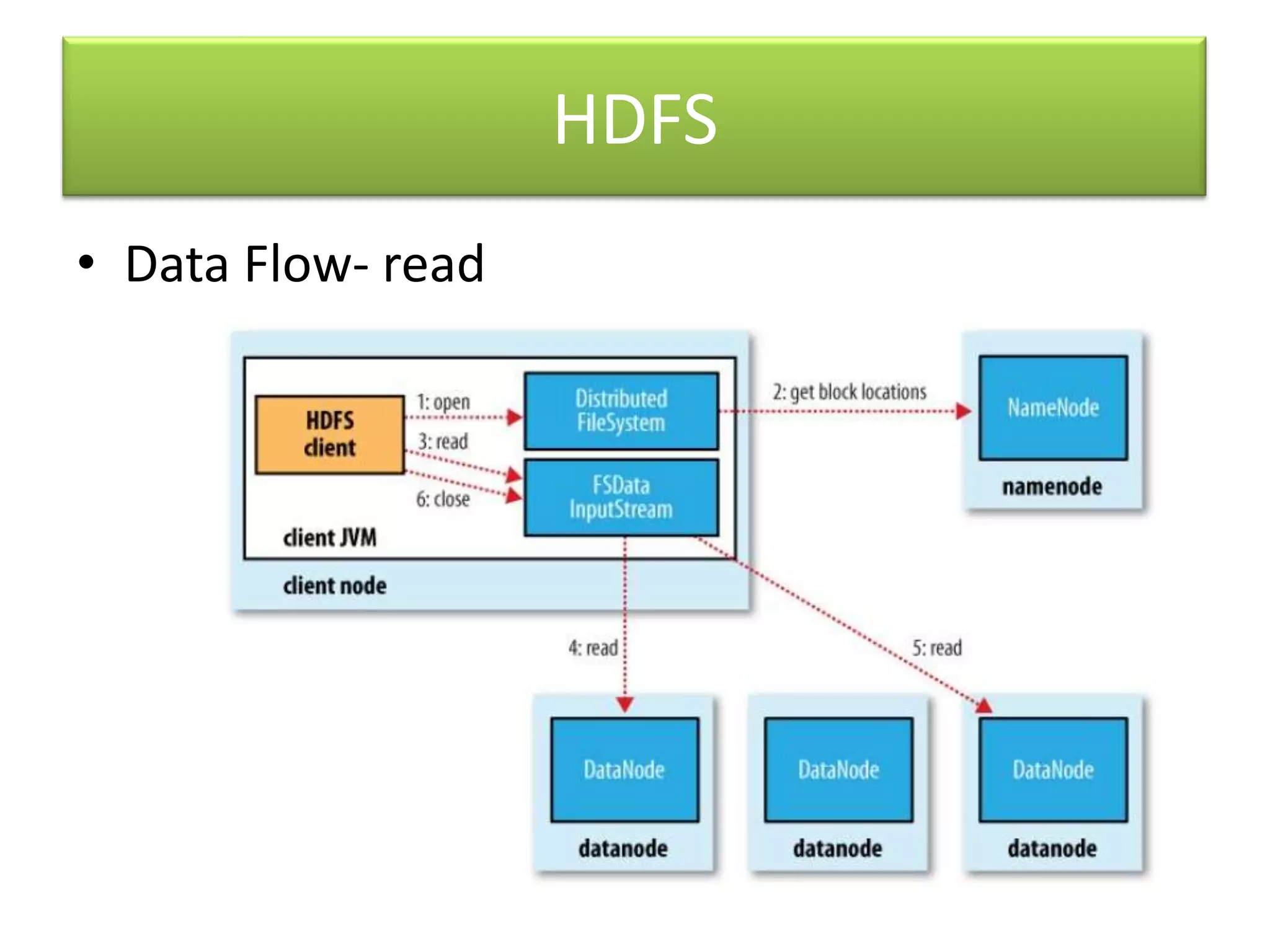
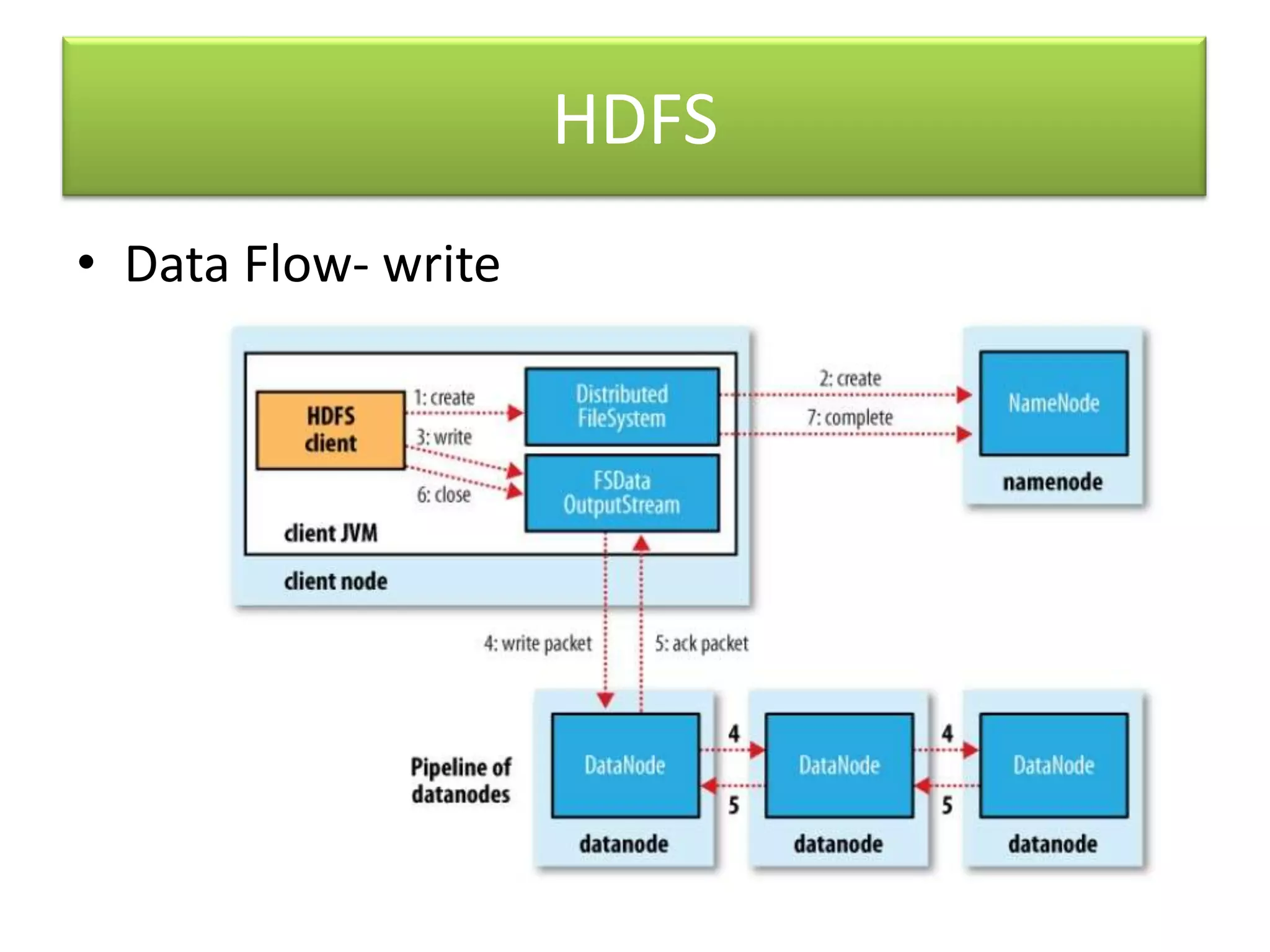




Hadoop is an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It uses MapReduce as a programming model and HDFS for storage. MapReduce allows for massively parallel processing of large datasets by breaking jobs into smaller tasks that can be run in parallel on multiple machines. HDFS stores very large files across machines in a distributed file system for fault tolerance.





































![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













