Downloaded 47 times

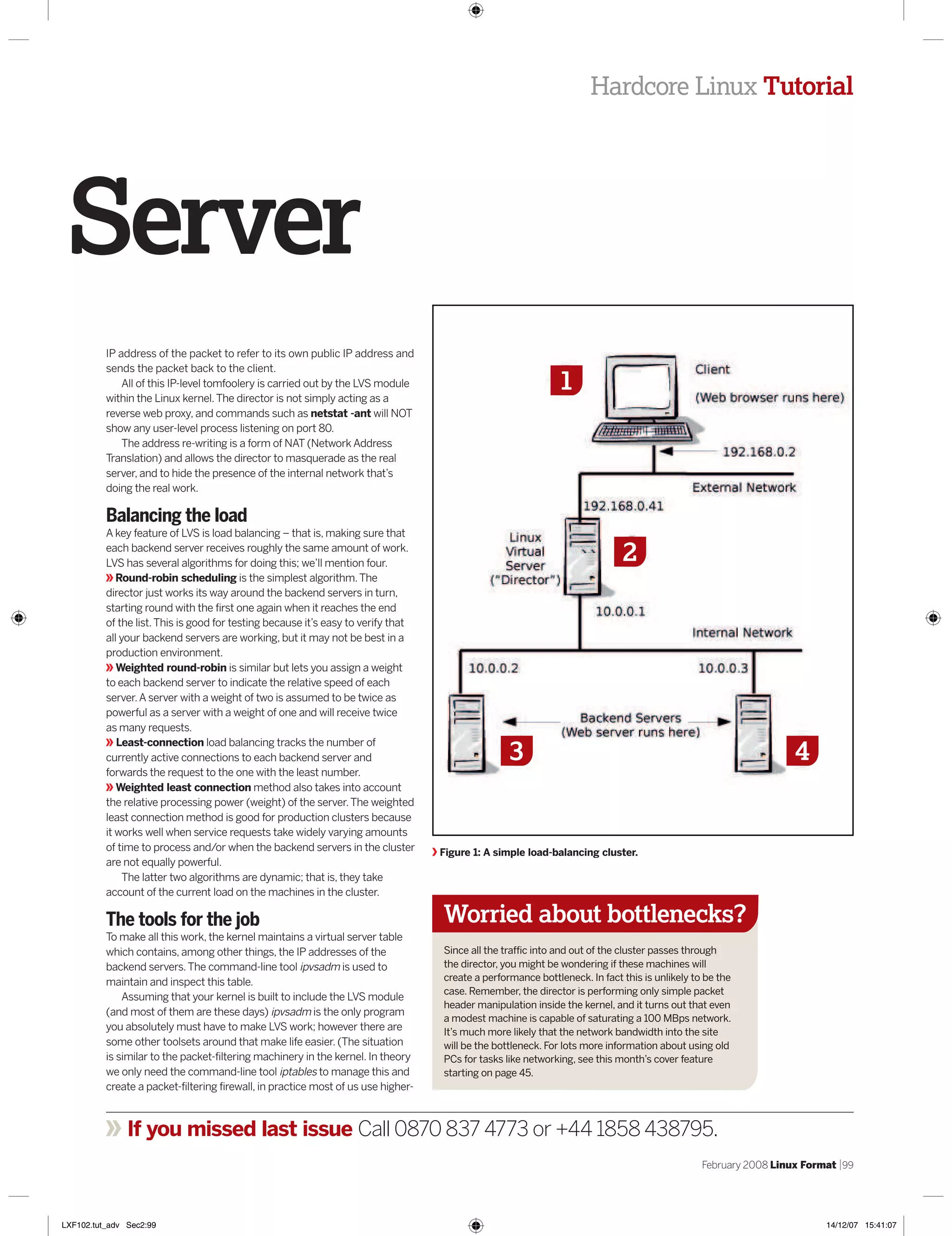


This document discusses setting up a load balancing cluster with Linux virtual server (LVS). It describes using four computers - one as a client, one as the director to perform load balancing and routing, and two as backend servers. The director uses LVS and network address translation to distribute client requests to the backend servers to balance the load. It discusses four load balancing algorithms available in LVS, including round-robin, weighted round-robin, least-connection, and weighted least-connection.


































![Lync Server 2010: High Availability [I3004]](https://cdn.slidesharecdn.com/ss_thumbnails/i3004slide-120625163449-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























