Downloaded 1,312 times








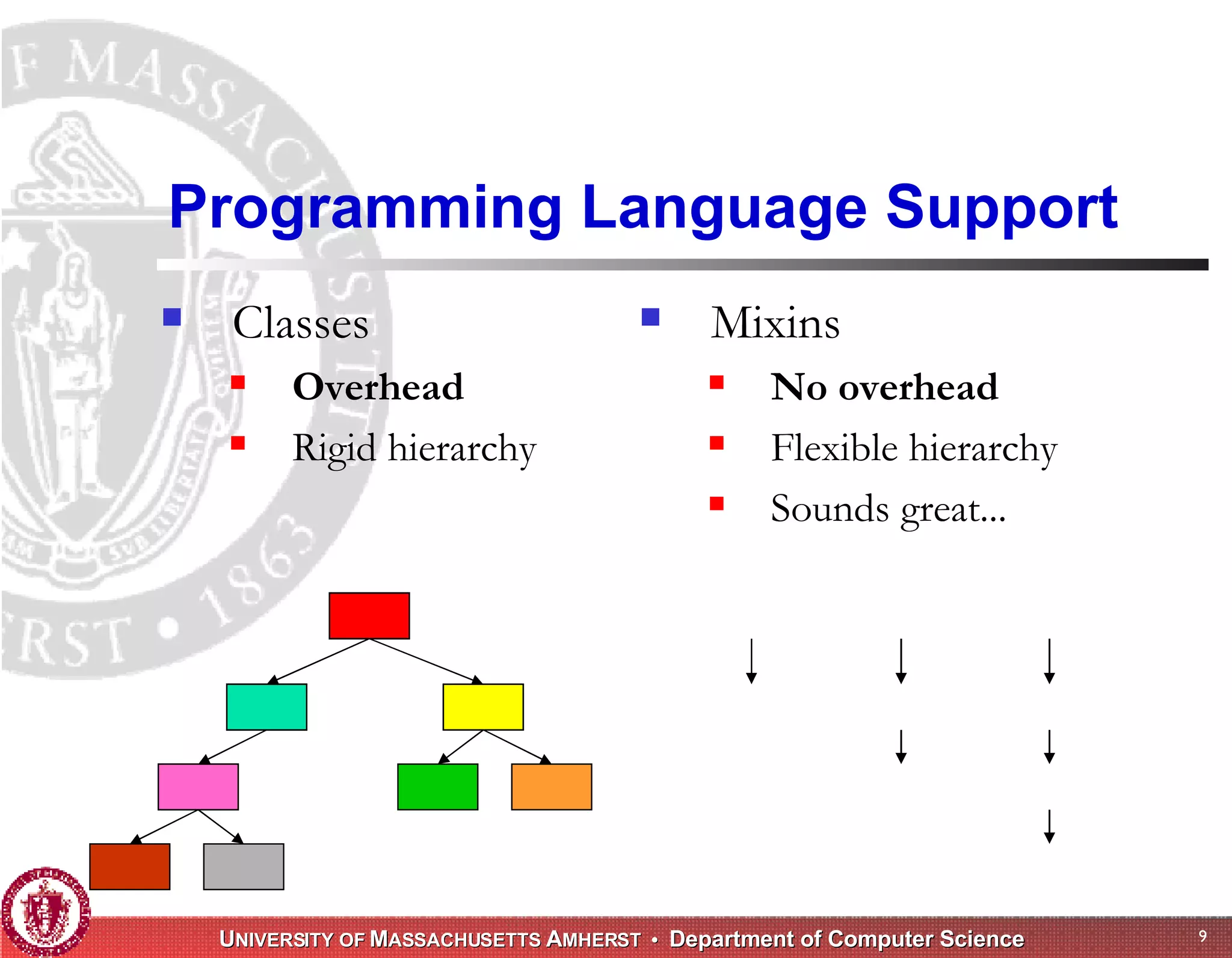
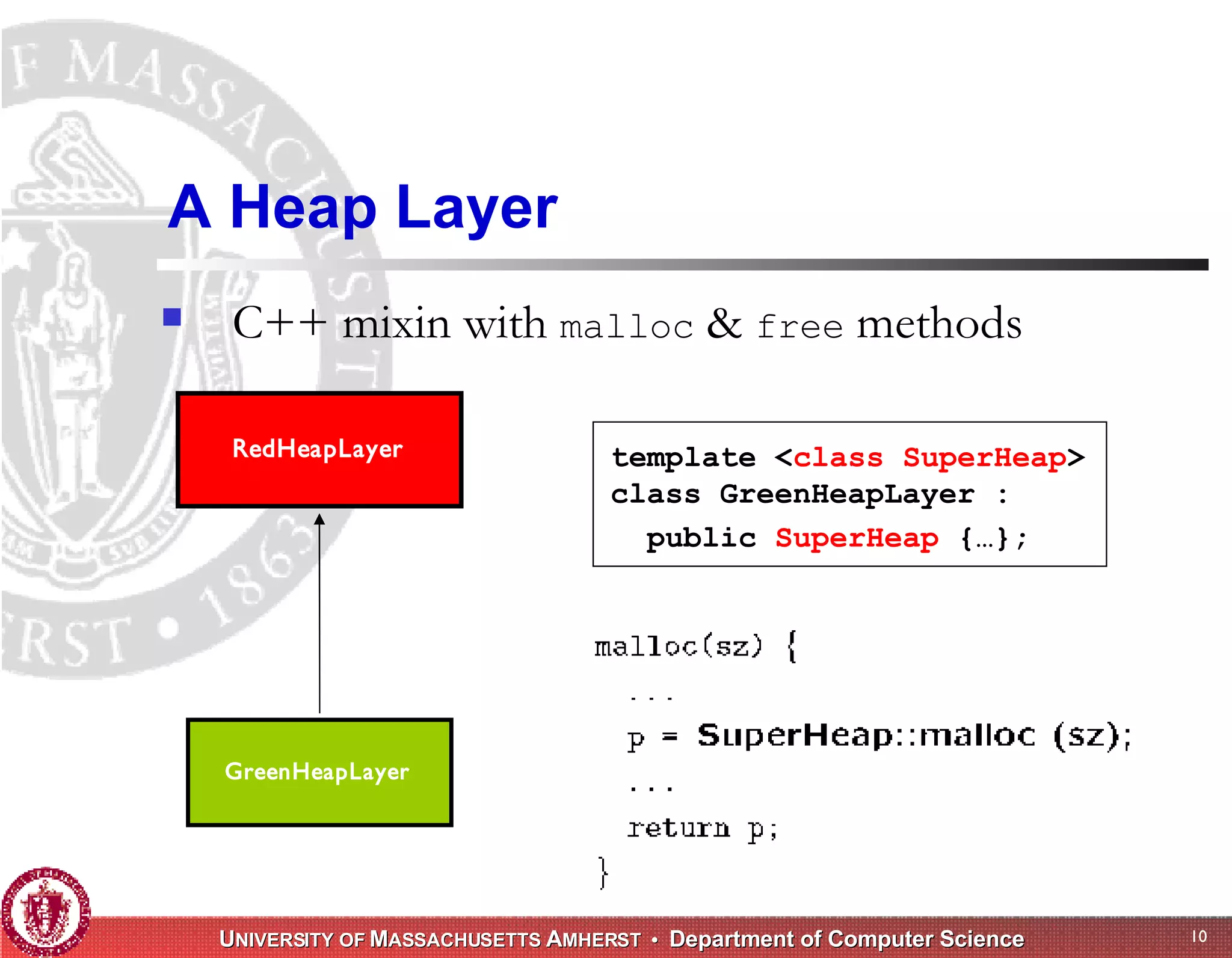

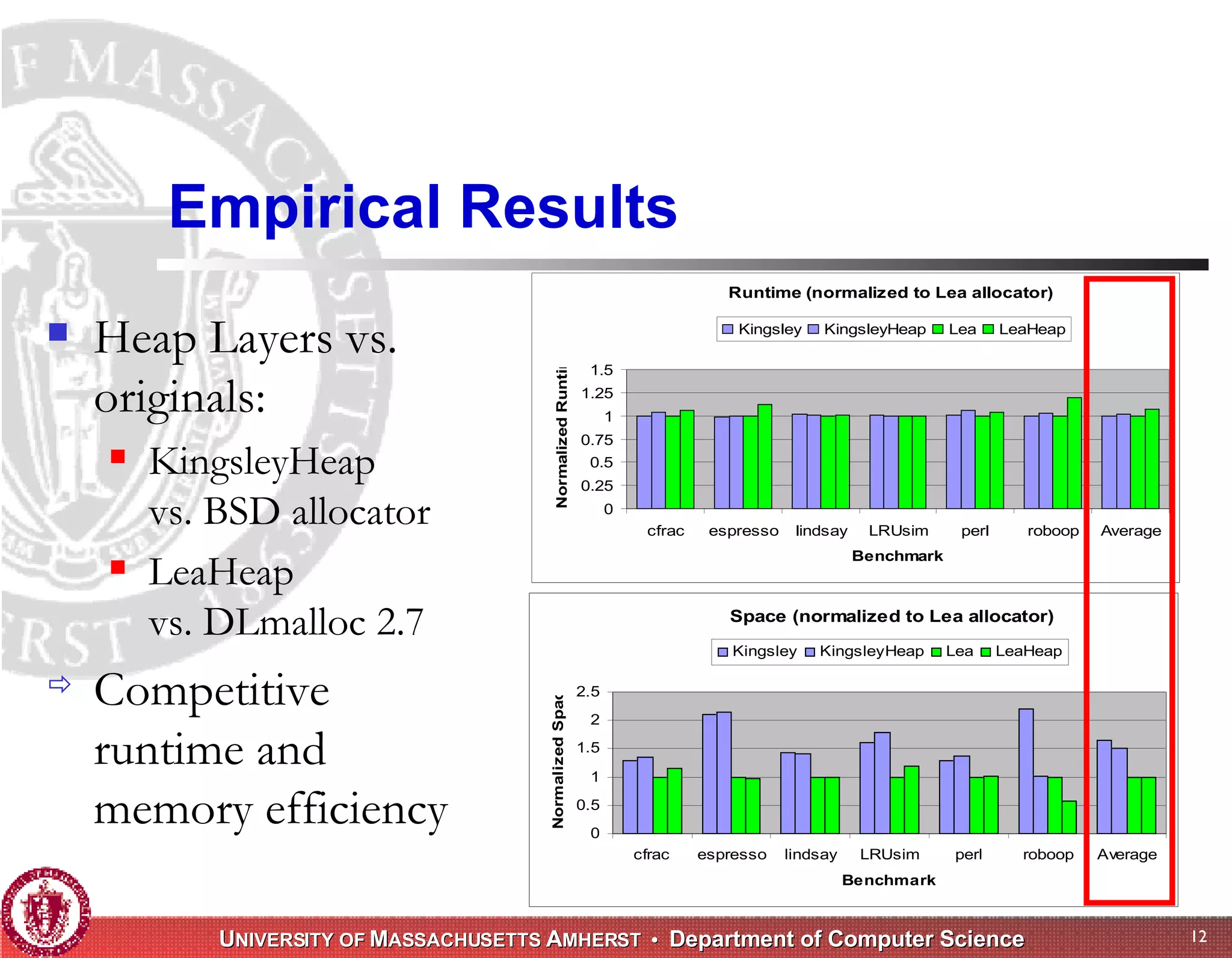



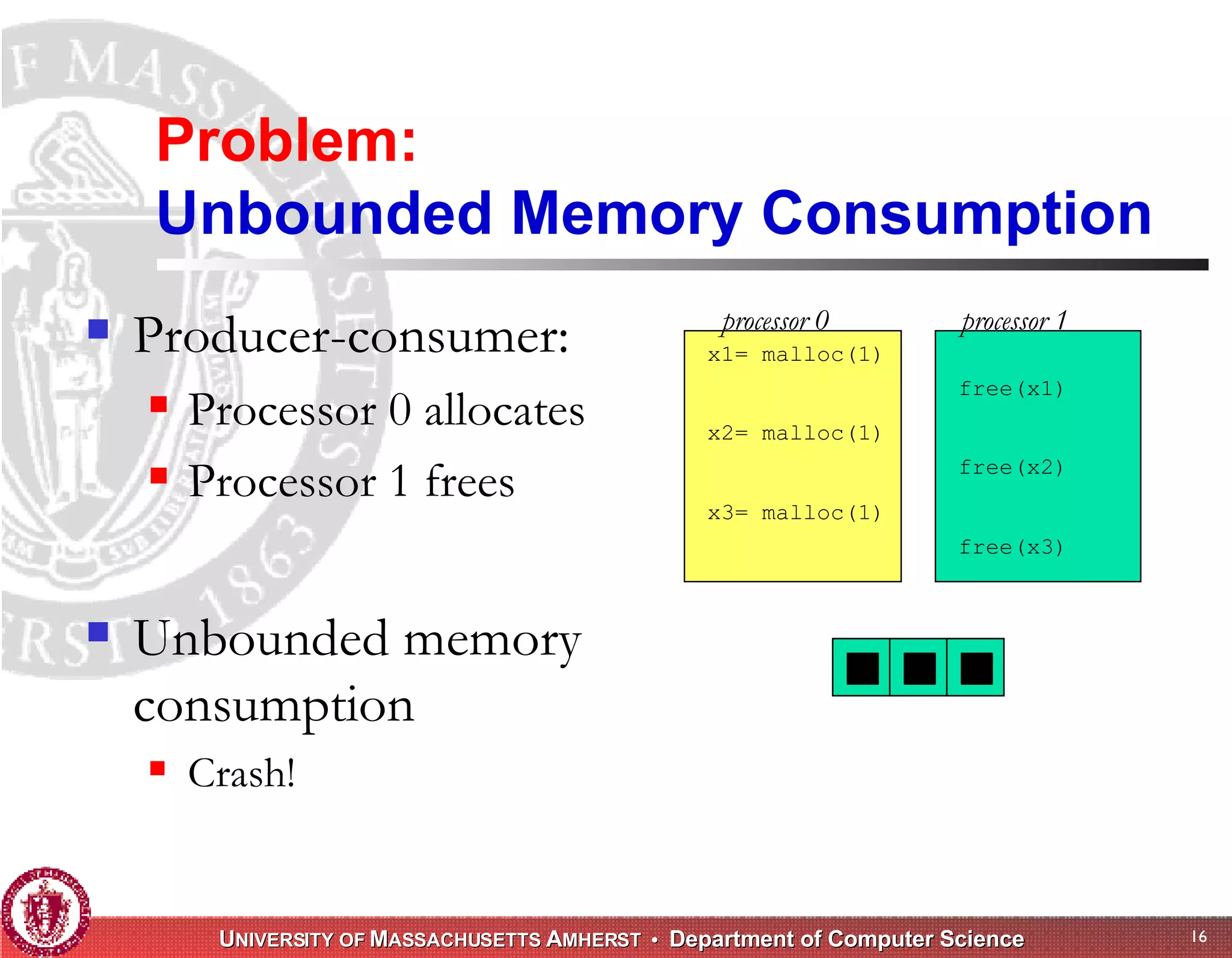


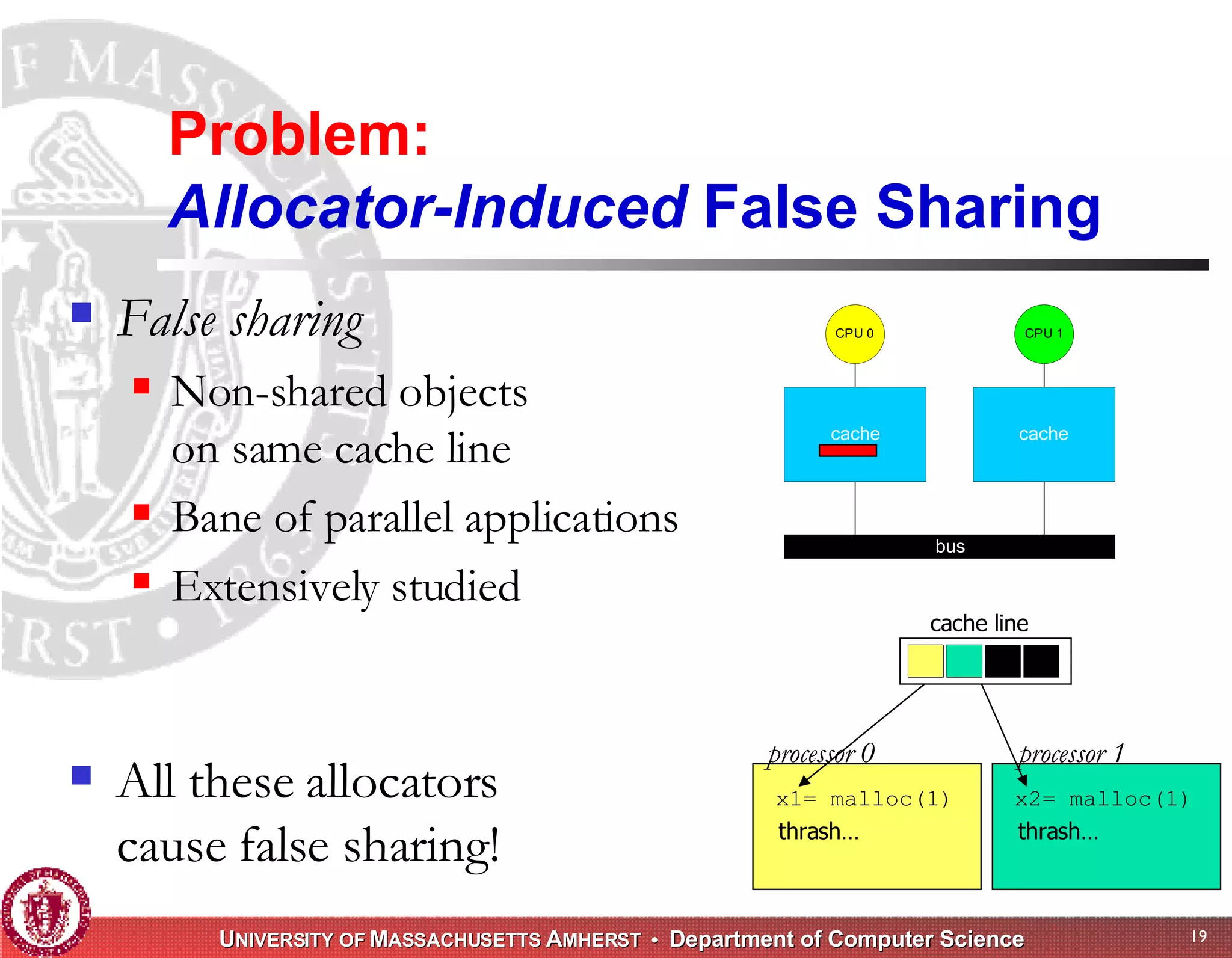






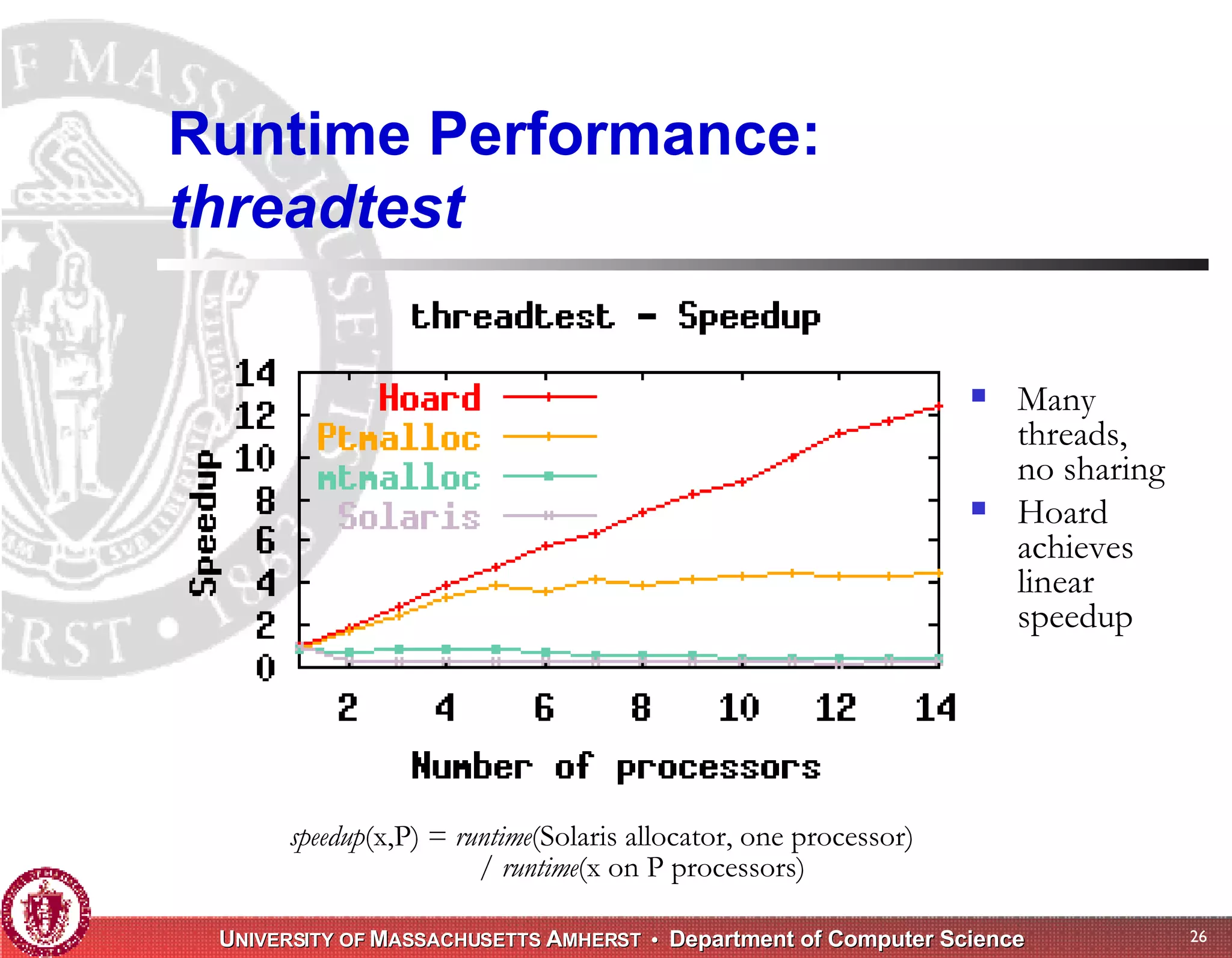
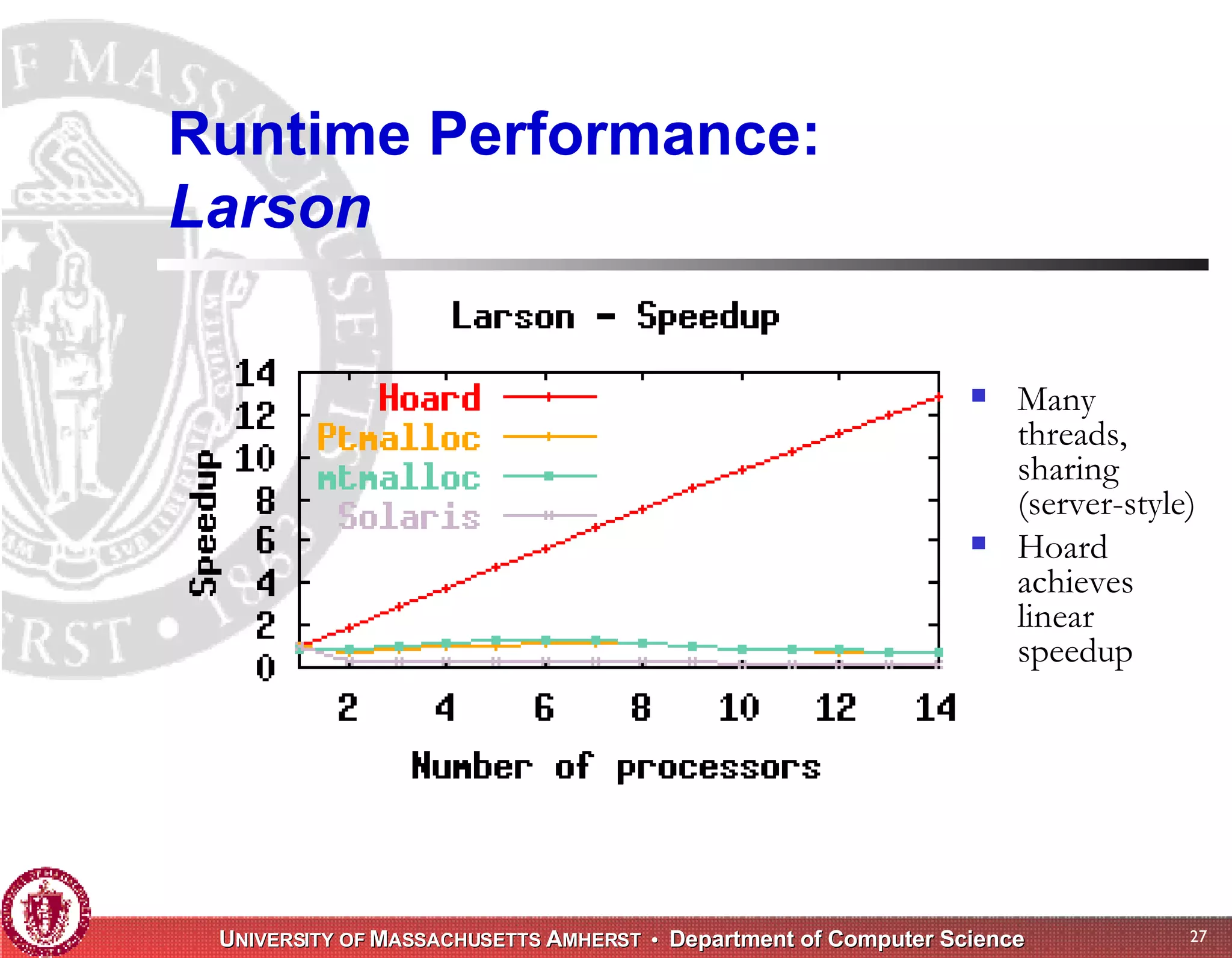
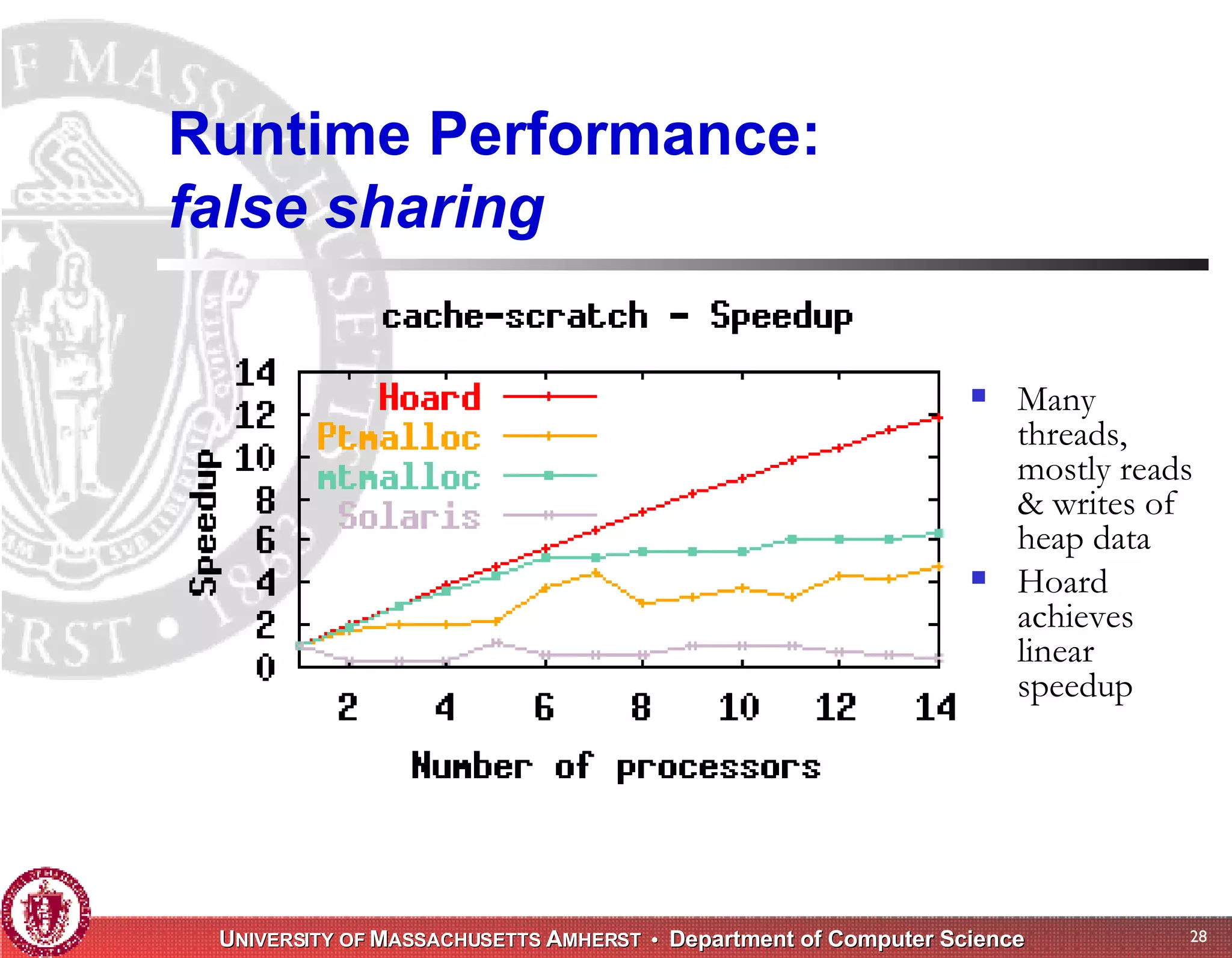



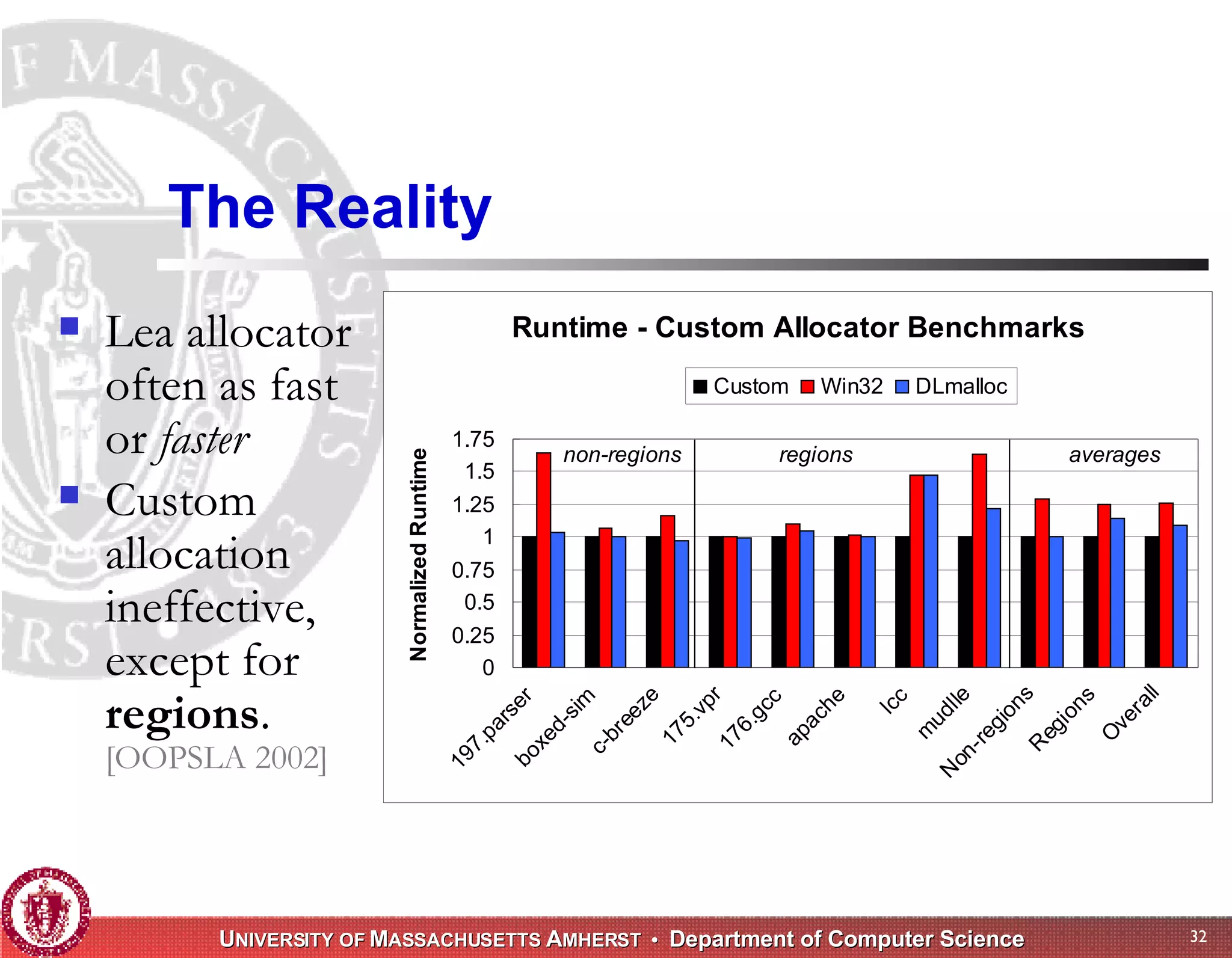




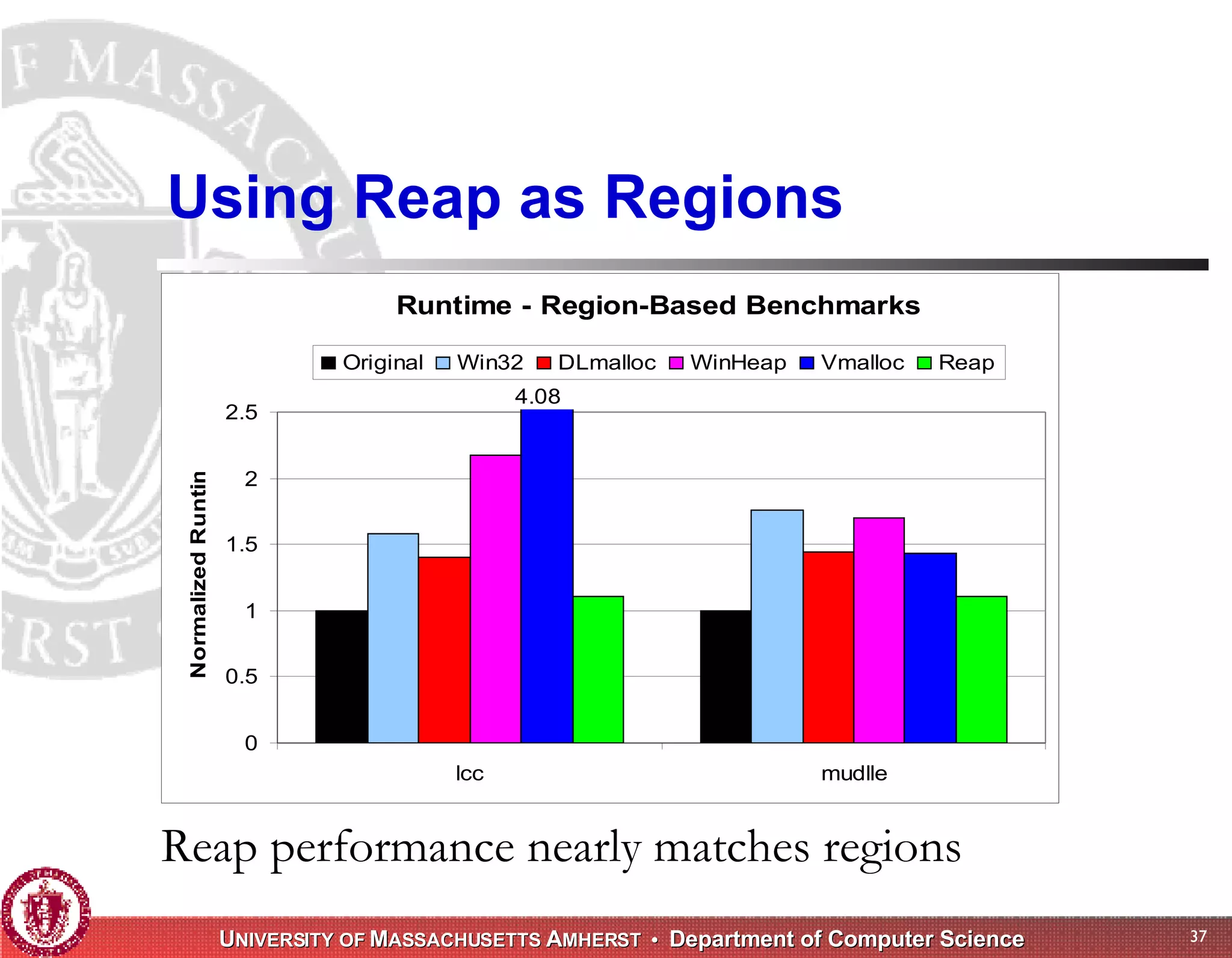







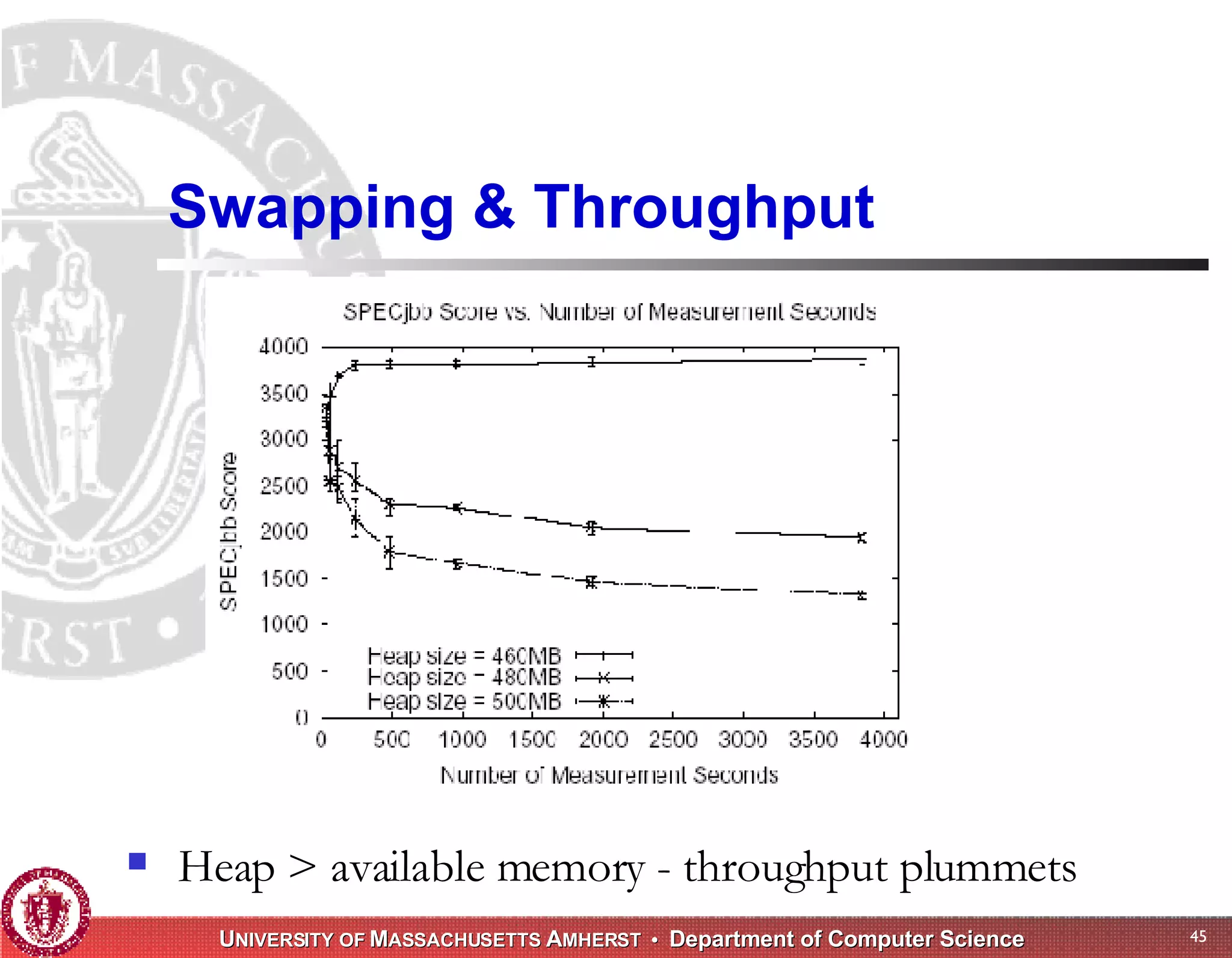

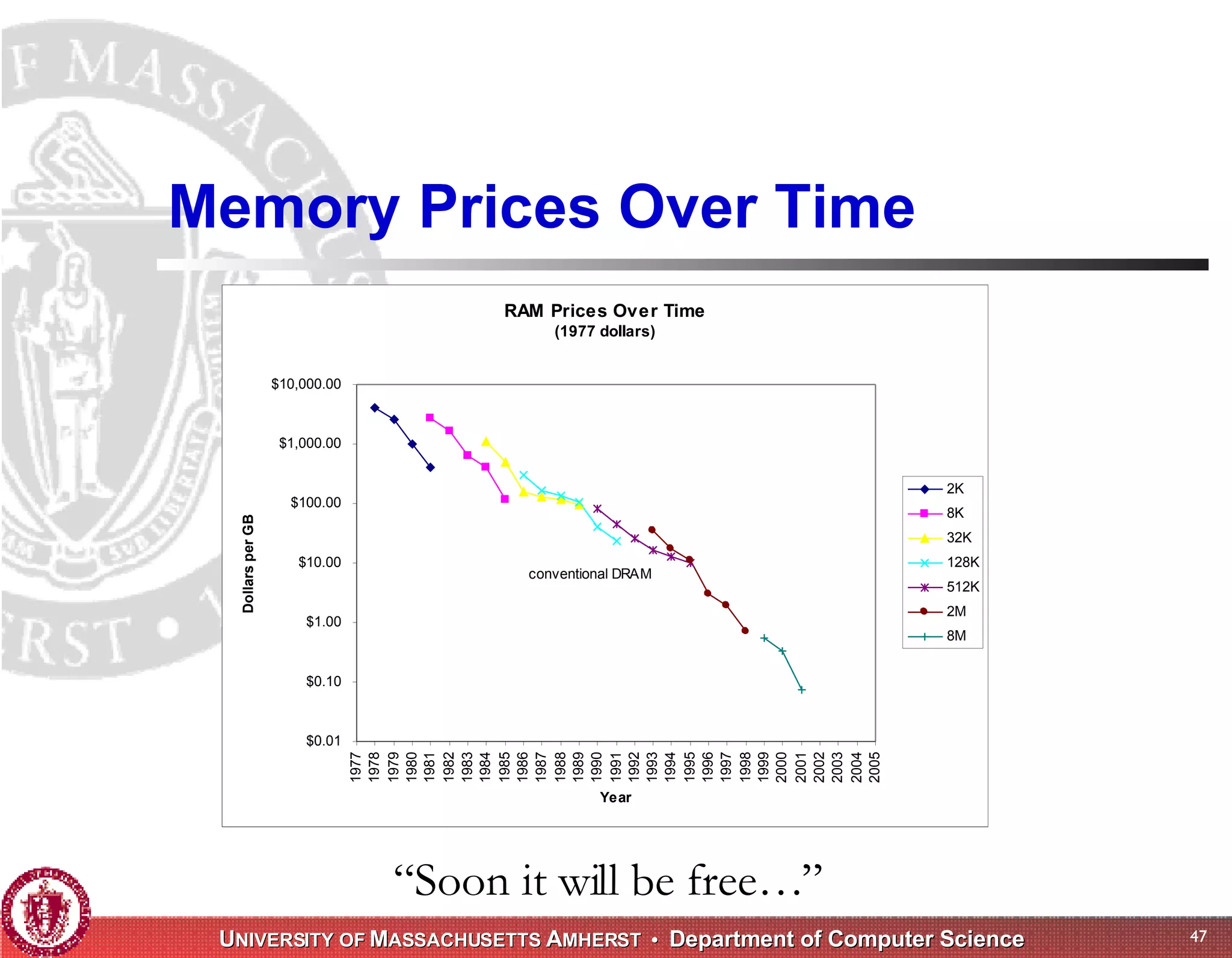
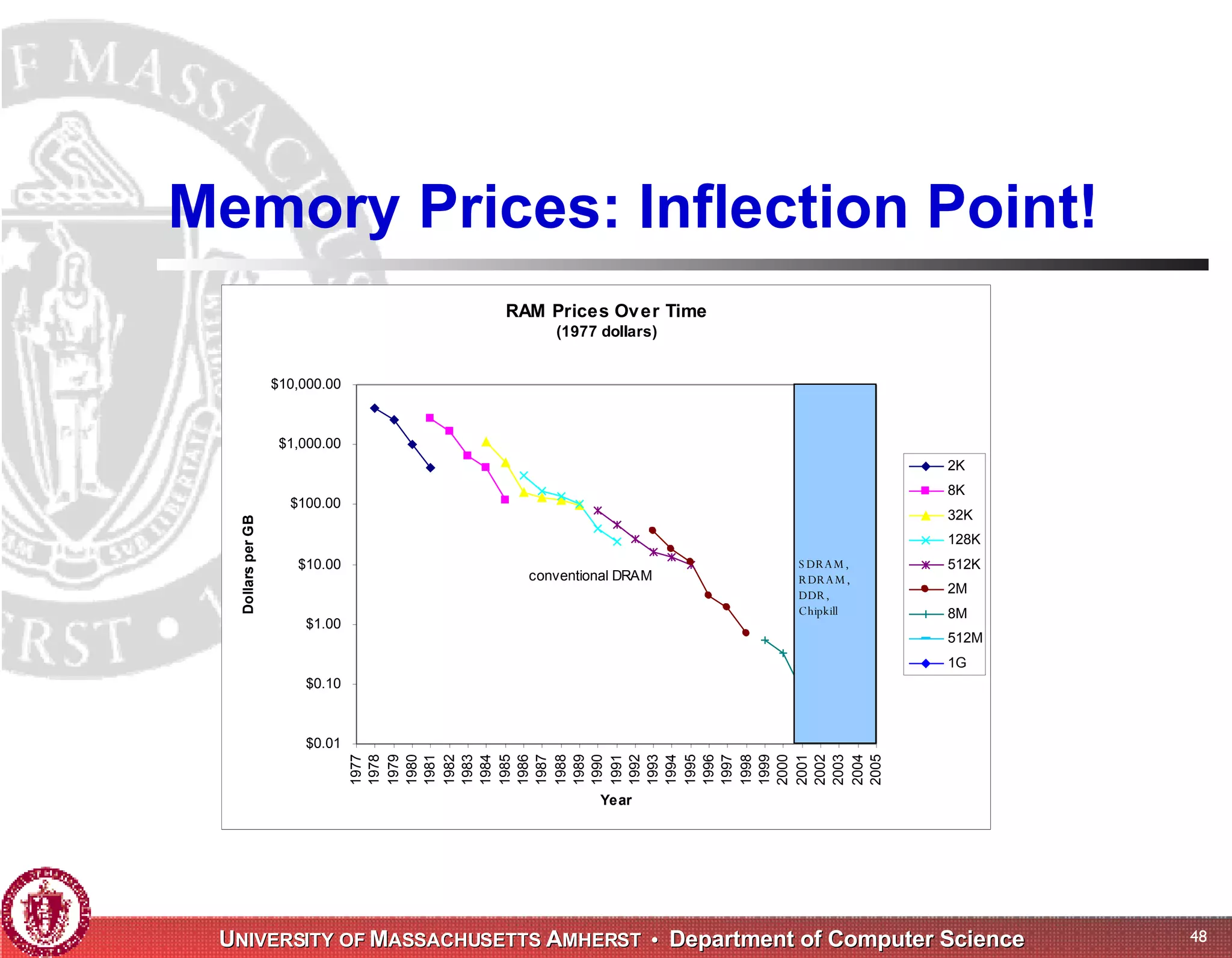


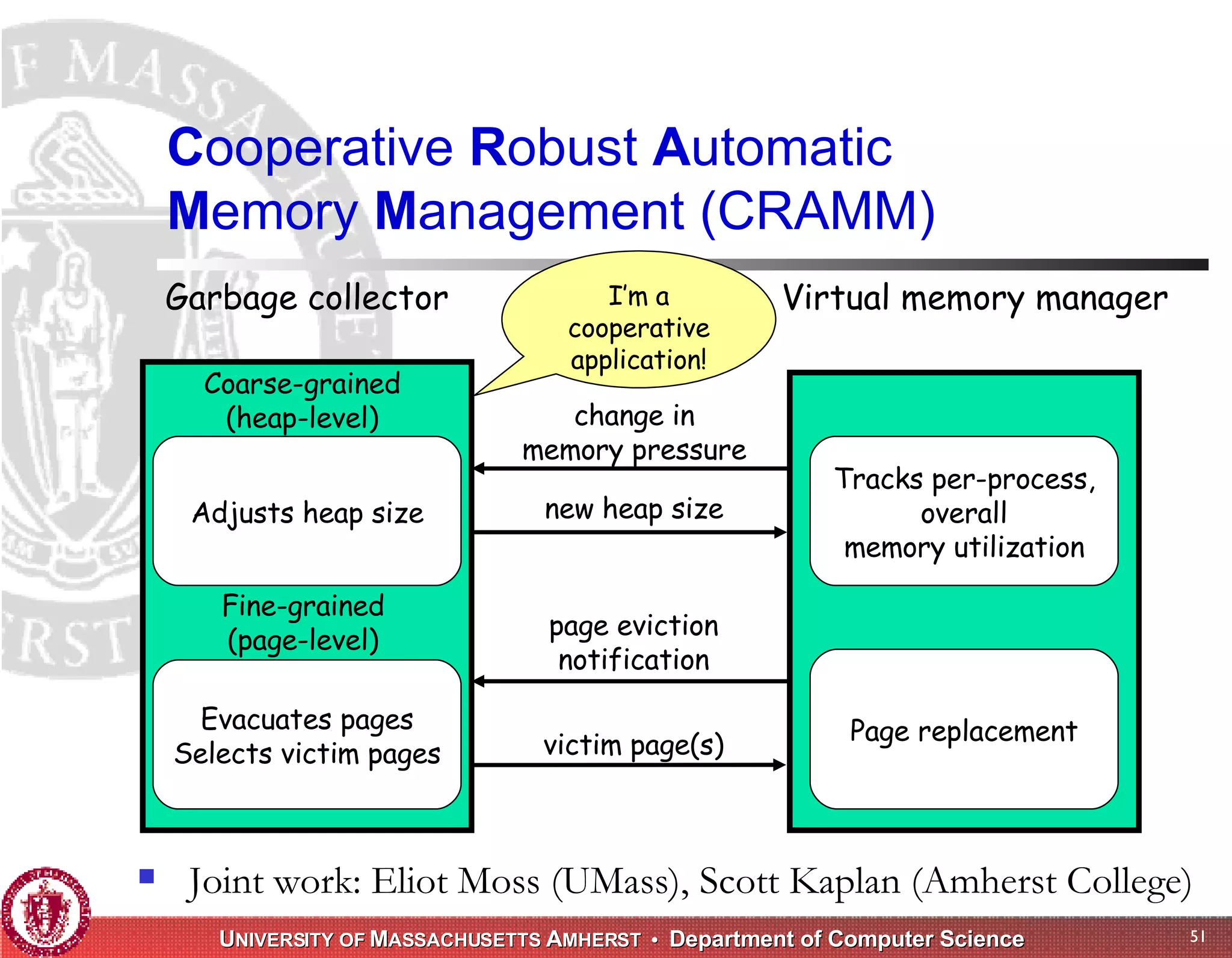
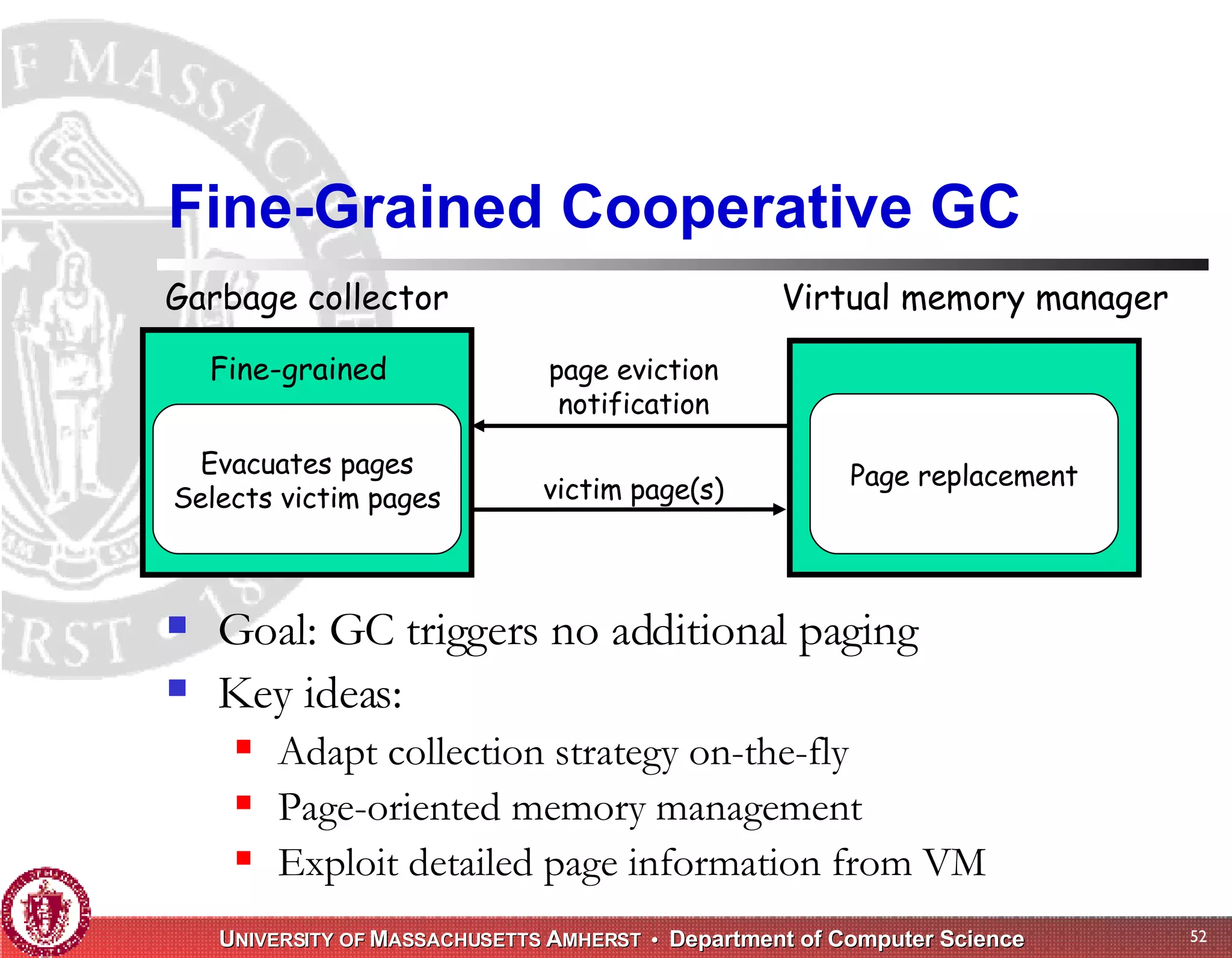










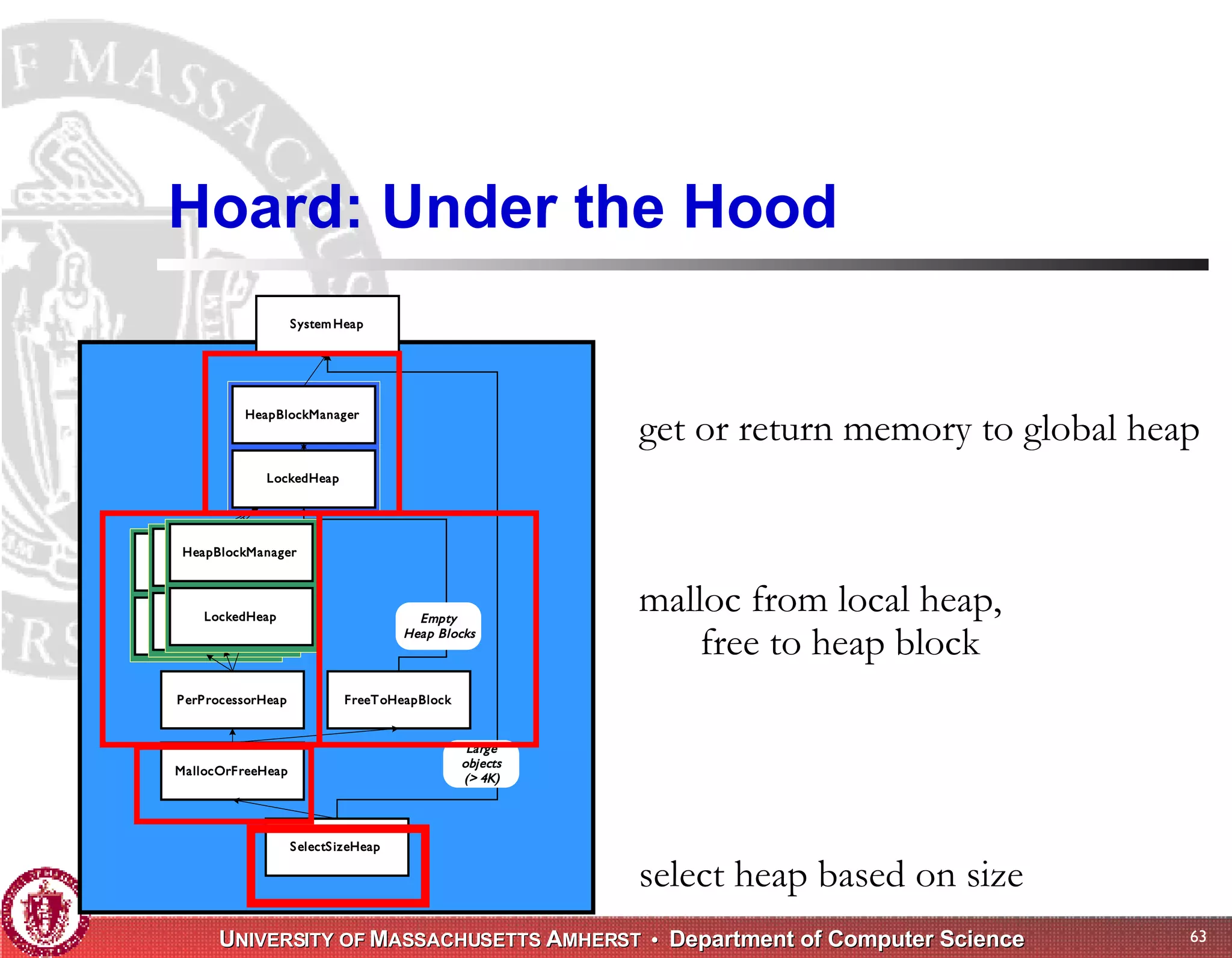







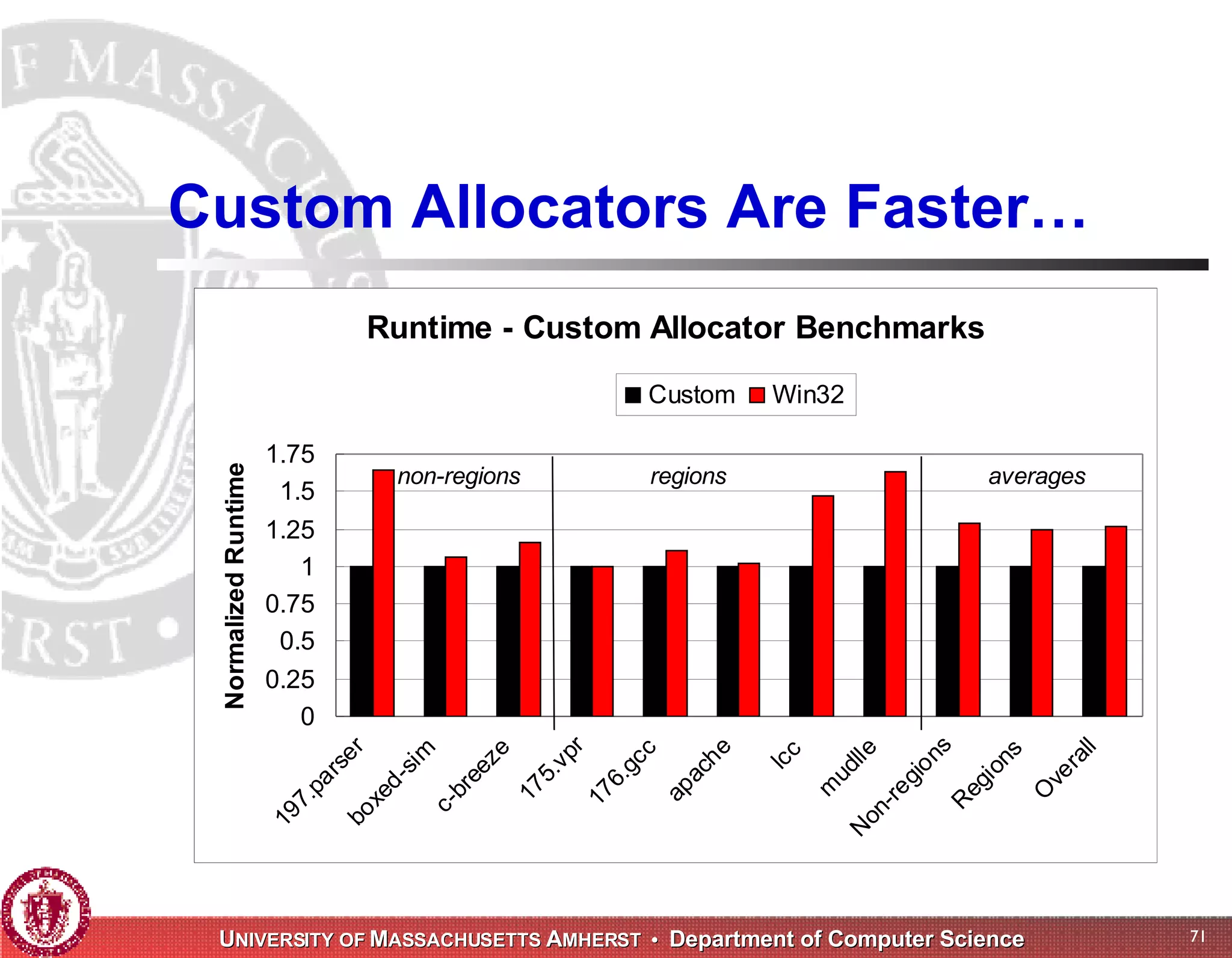
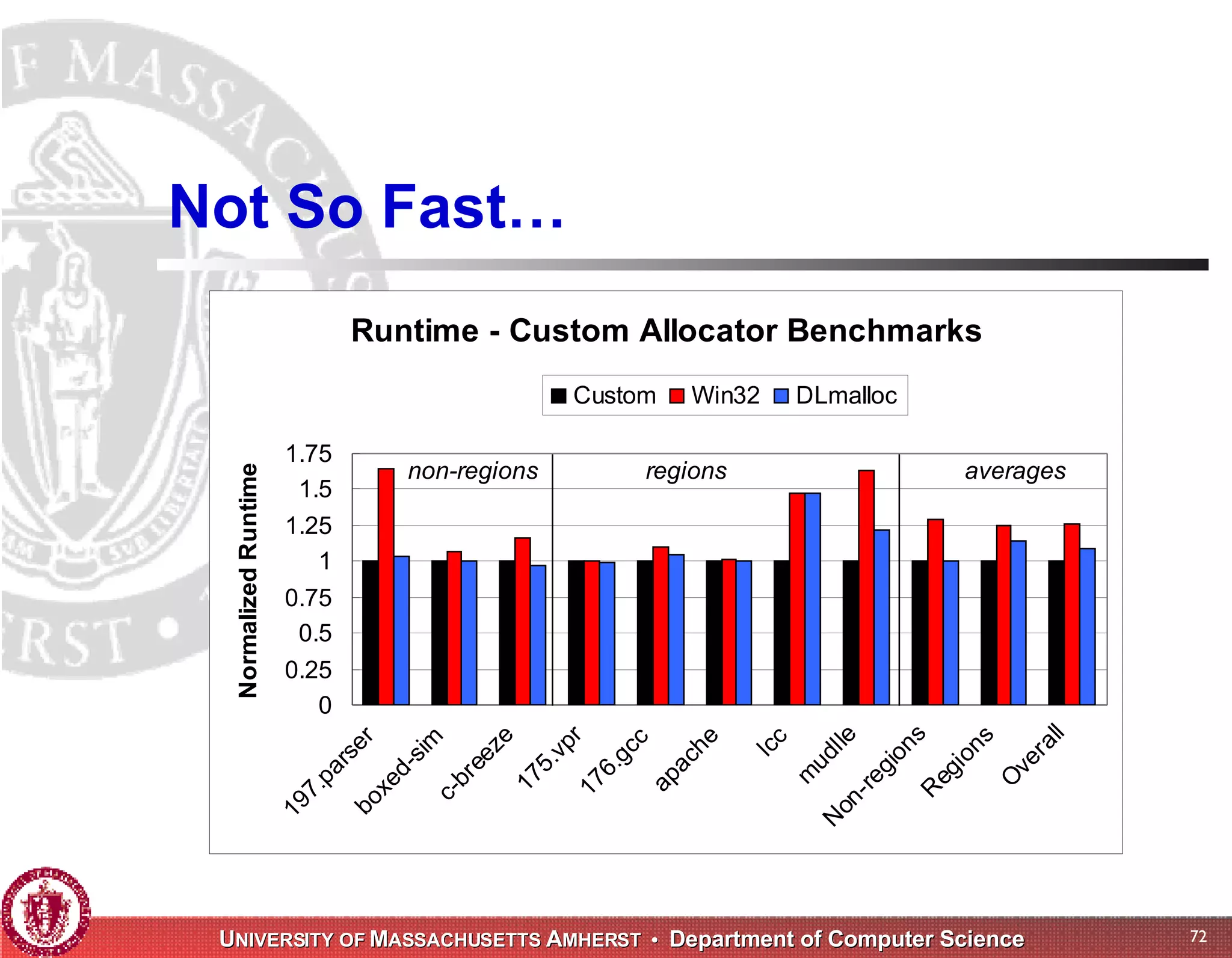

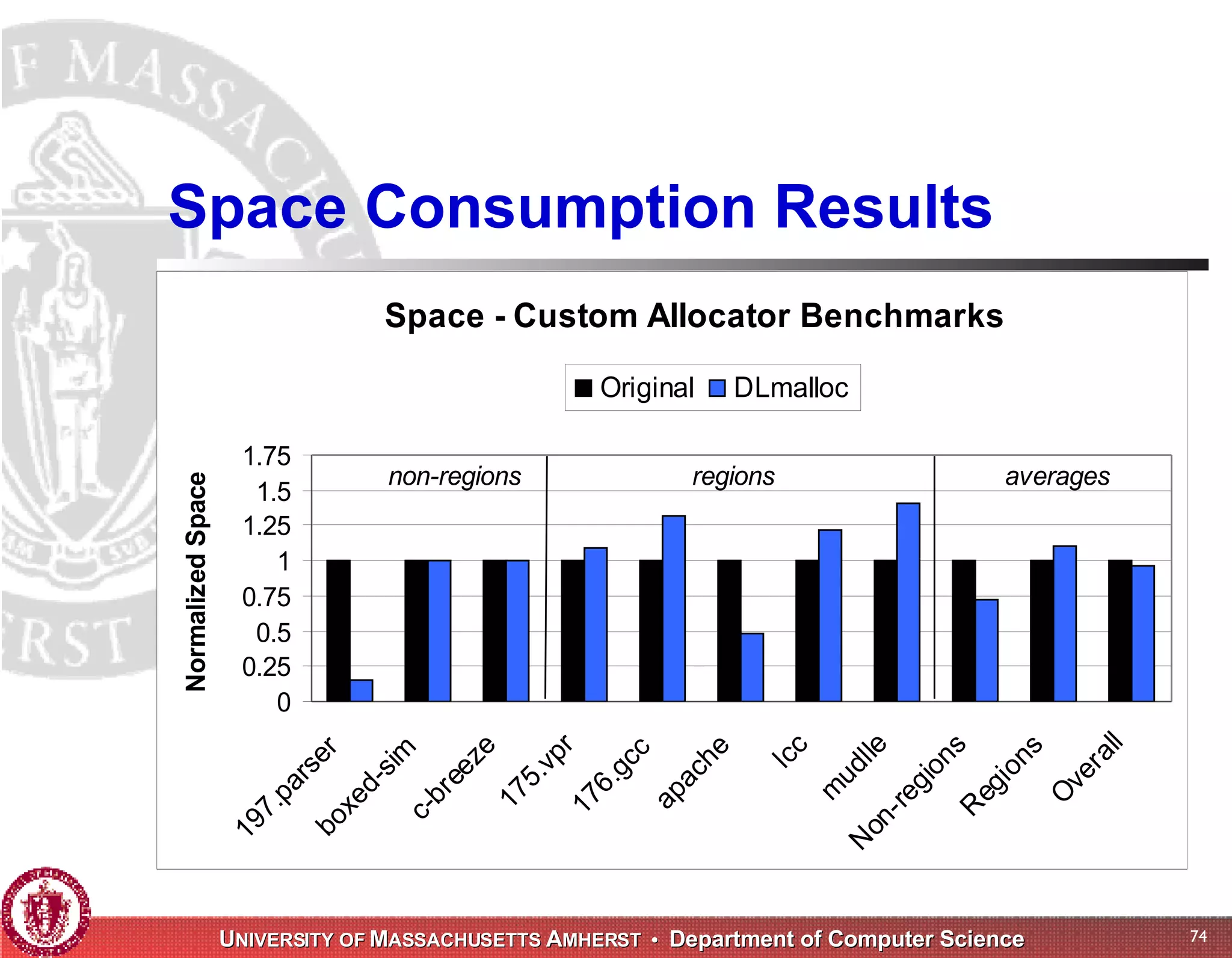




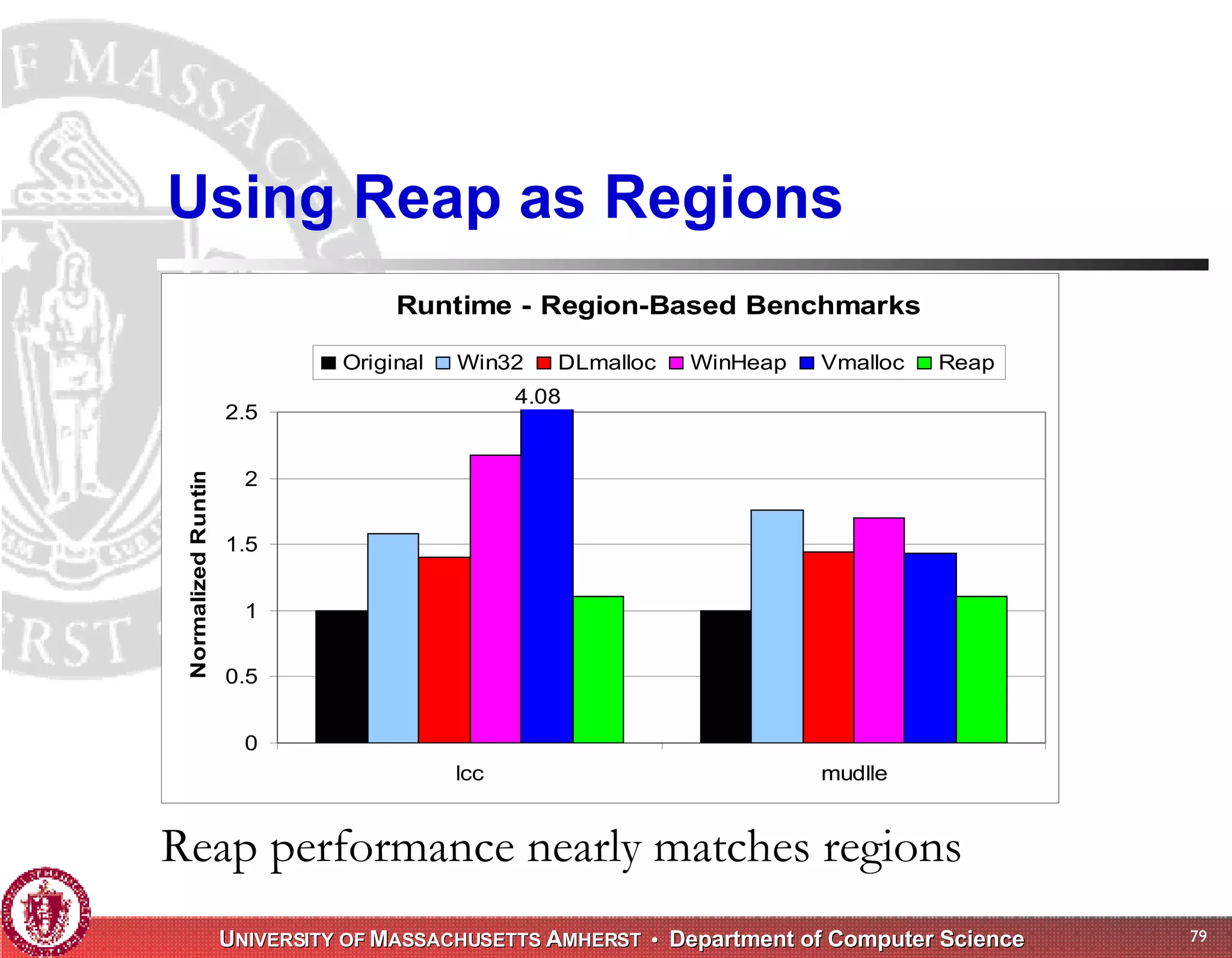














The document discusses challenges with existing memory managers and proposes solutions. Current memory managers are inadequate for high-performance applications on modern multicore architectures as they limit scalability and performance. The talk introduces the Heap Layers framework for building customizable memory managers. It also describes Hoard, a provably scalable memory manager that bounds local memory consumption by explicitly tracking utilization and moving free memory to a global heap. Finally, an extended memory manager called Reap is proposed for server applications.



































































