Downloaded 155 times



![Uniprocessor Allocators on Multiprocessors Fragmentation: Excellent Very low for most programs [Wilson & Johnstone] Speed & Scalability: Poor Heap contention a single lock protects the heap Can exacerbate false sharing different processors can share cache lines](https://image.slidesharecdn.com/hoard-a-scalable-memory-allocator-for-multithreaded-applications-13641/85/Hoard-A-Scalable-Memory-Allocator-for-Multithreaded-Applications-4-320.jpg)




![Multiprocessor Allocator II: Private Heaps with Ownership Private heaps with ownership: free puts memory back on the originating processor 's heap. Avoids unbounded memory consumption Examples: ptmalloc [Gloger], LKmalloc [Larson & Krishnan] x1= malloc(s) free(x1) free(x2) x2= malloc(s) processor 1 processor 2](https://image.slidesharecdn.com/hoard-a-scalable-memory-allocator-for-multithreaded-applications-13641/85/Hoard-A-Scalable-Memory-Allocator-for-Multithreaded-Applications-9-320.jpg)




![Summary of Analytical Results Worst-case memory consumption: O(n log M/m + P ) [instead of O( P n log M/m)] n = memory required M = biggest object size m = smallest object size P = number of processors Best possible: O(n log M/m) [Robson] Provably low synchronization in most cases](https://image.slidesharecdn.com/hoard-a-scalable-memory-allocator-for-multithreaded-applications-13641/85/Hoard-A-Scalable-Memory-Allocator-for-Multithreaded-Applications-14-320.jpg)



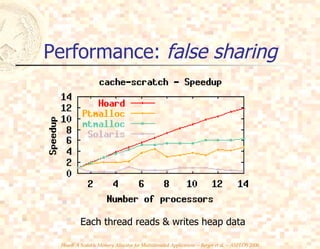




Hoard is a scalable memory allocator designed for multithreaded applications, aimed at addressing bottlenecks in parallel memory allocation. It utilizes a unique approach with local heaps and a global heap to manage memory efficiently while minimizing fragmentation and avoiding false sharing. Experimental results demonstrate that Hoard's performance is on par with uniprocessor allocators, exhibiting excellent speed, scalability, and low memory consumption across various benchmarks.















































































