Downloaded 40 times

















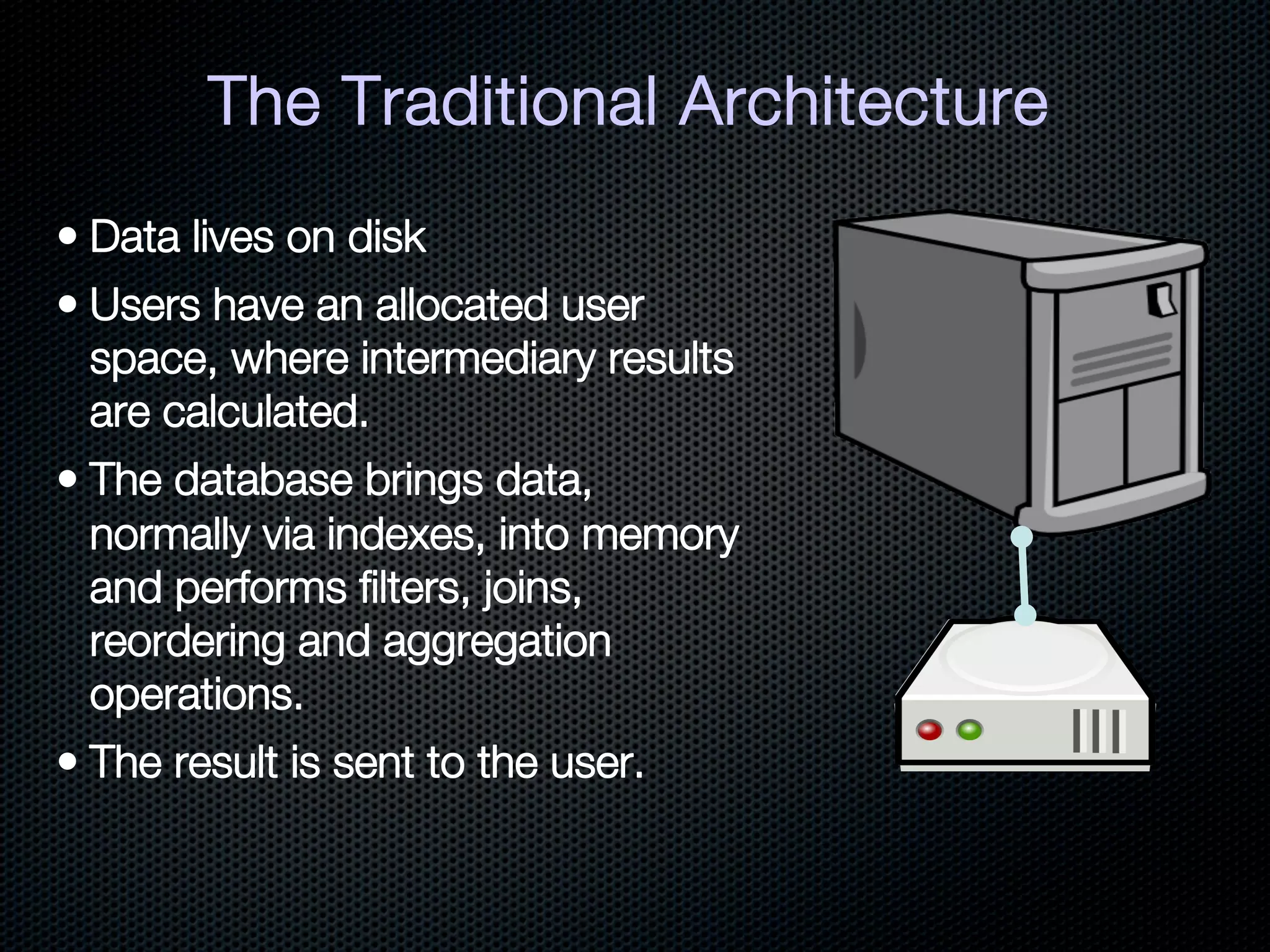
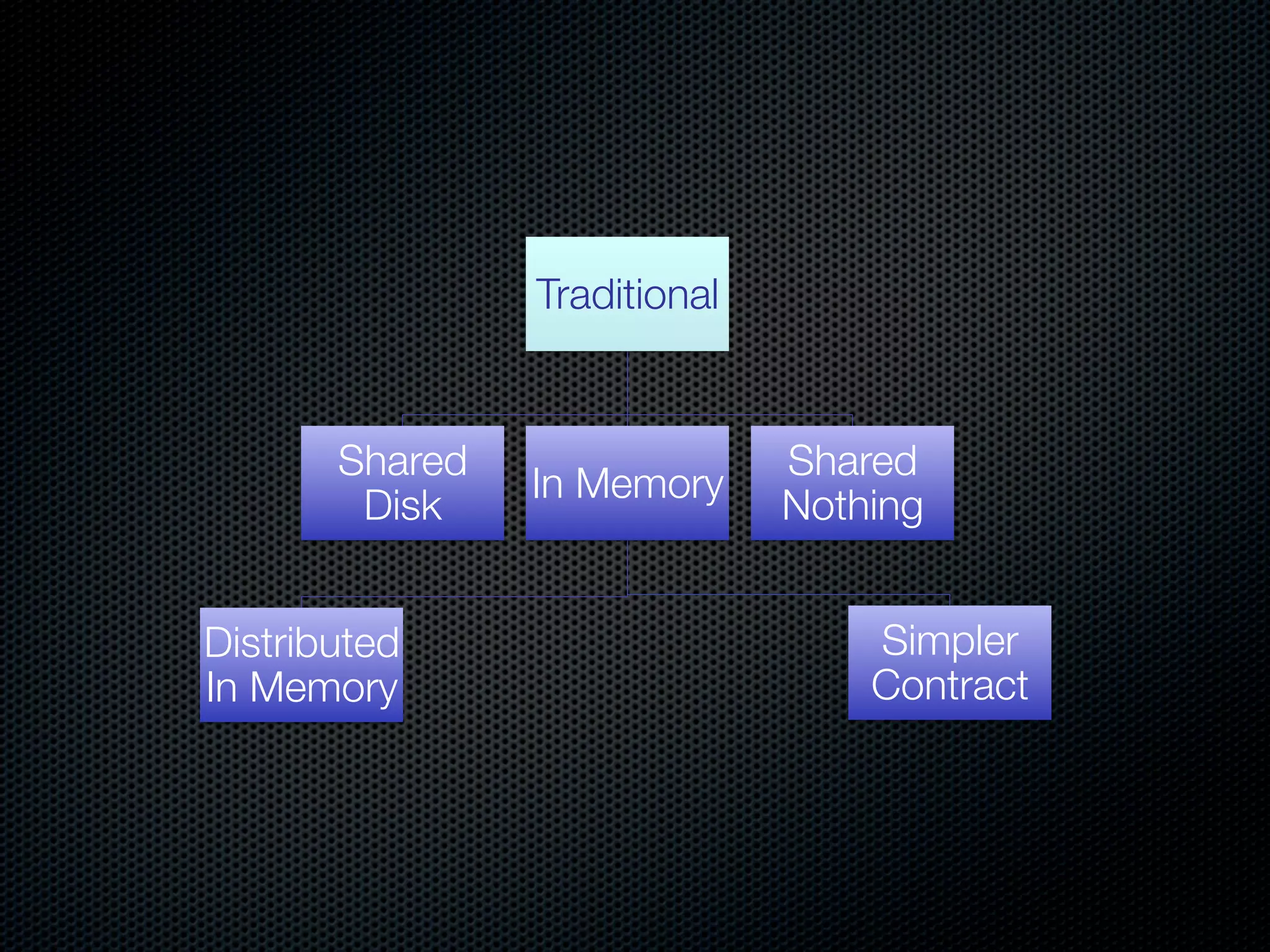





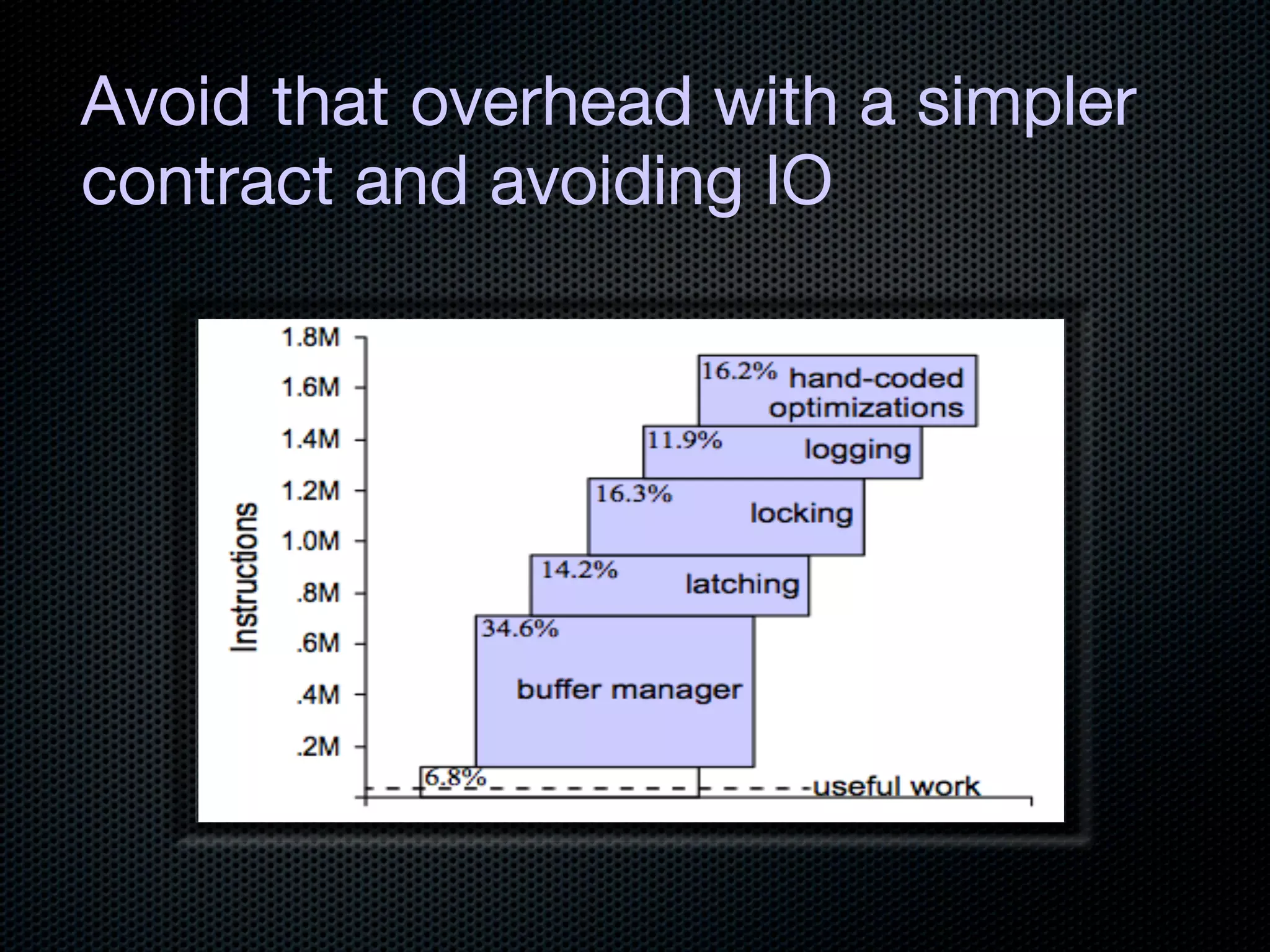
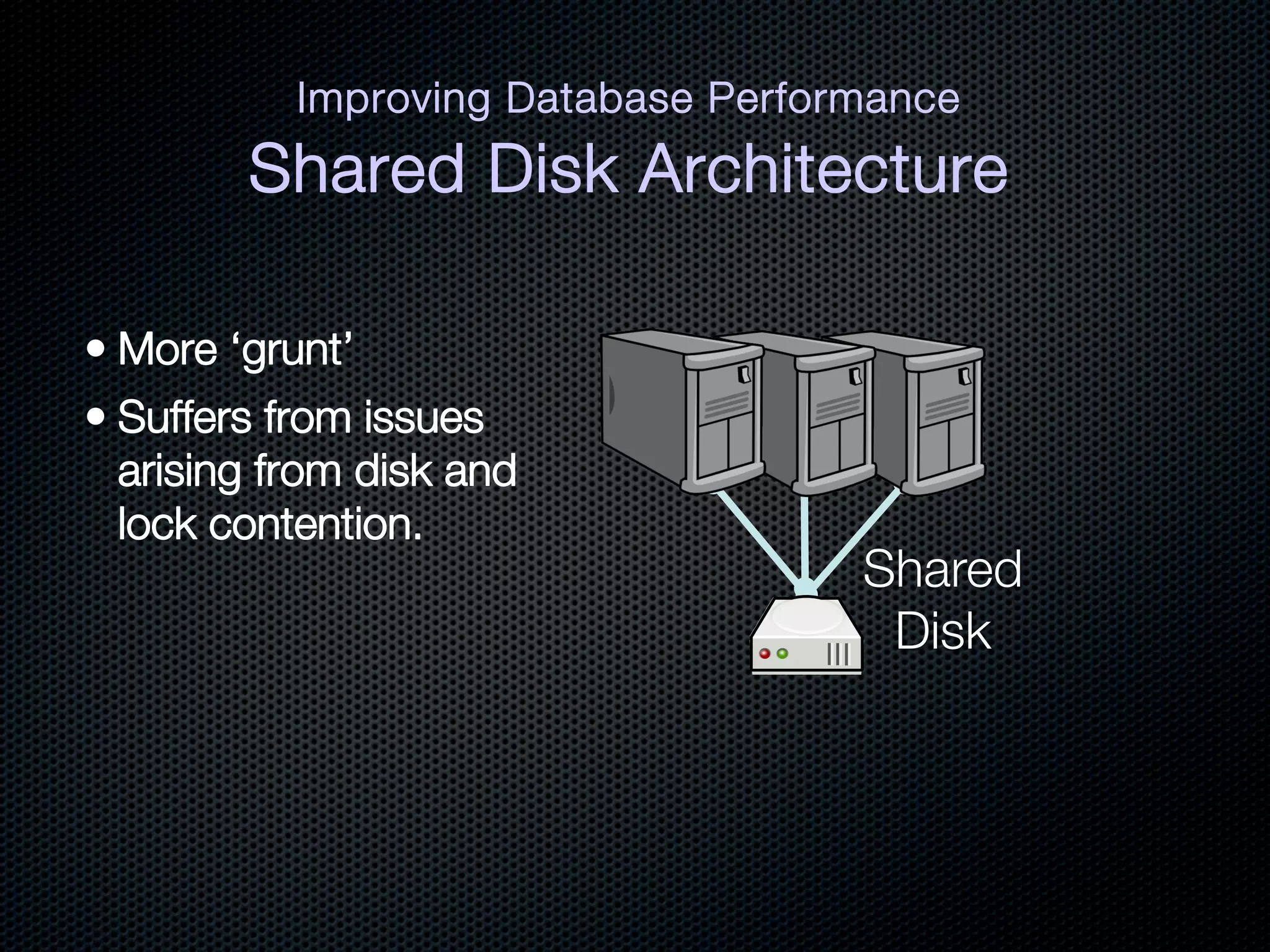















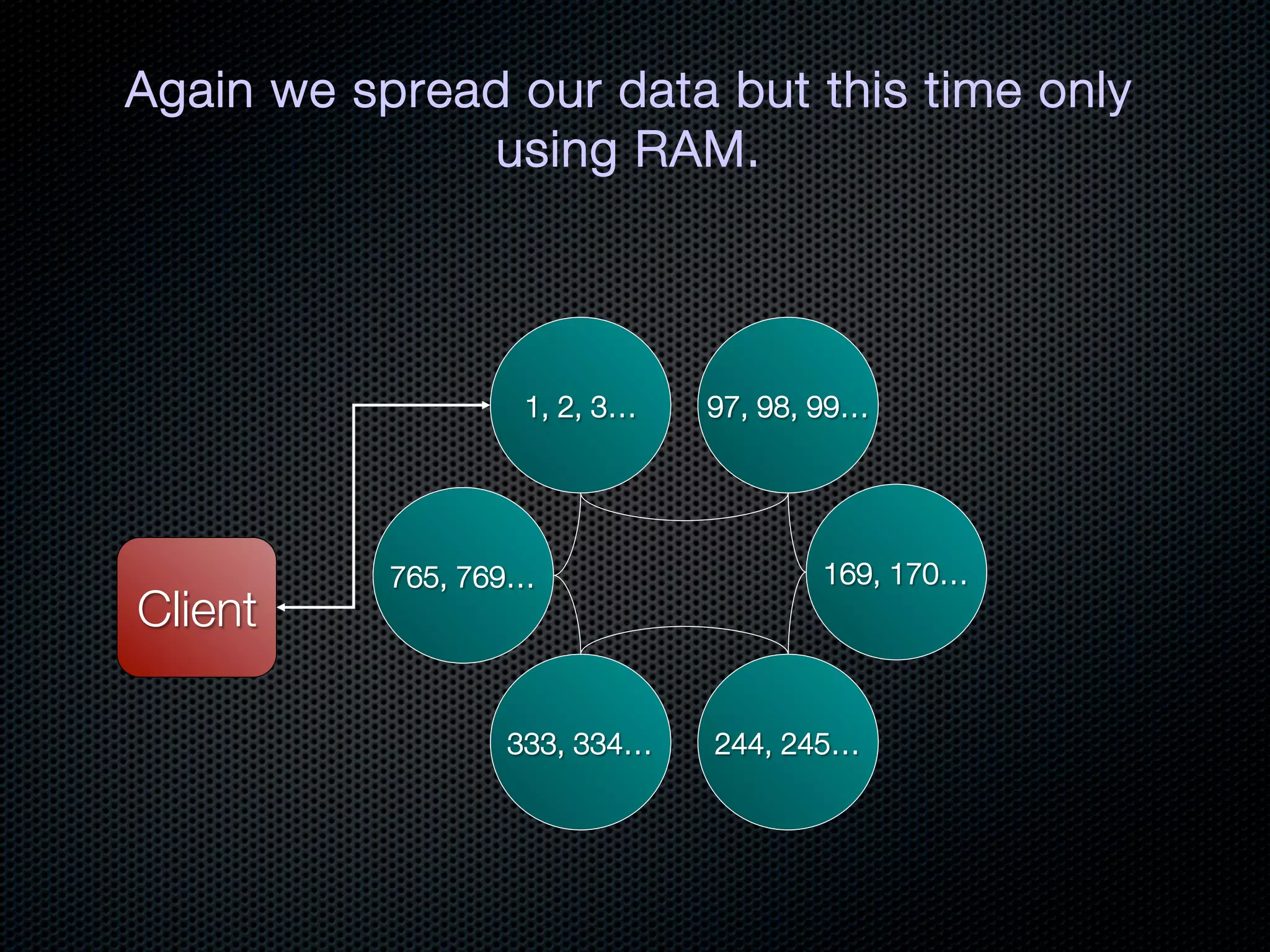



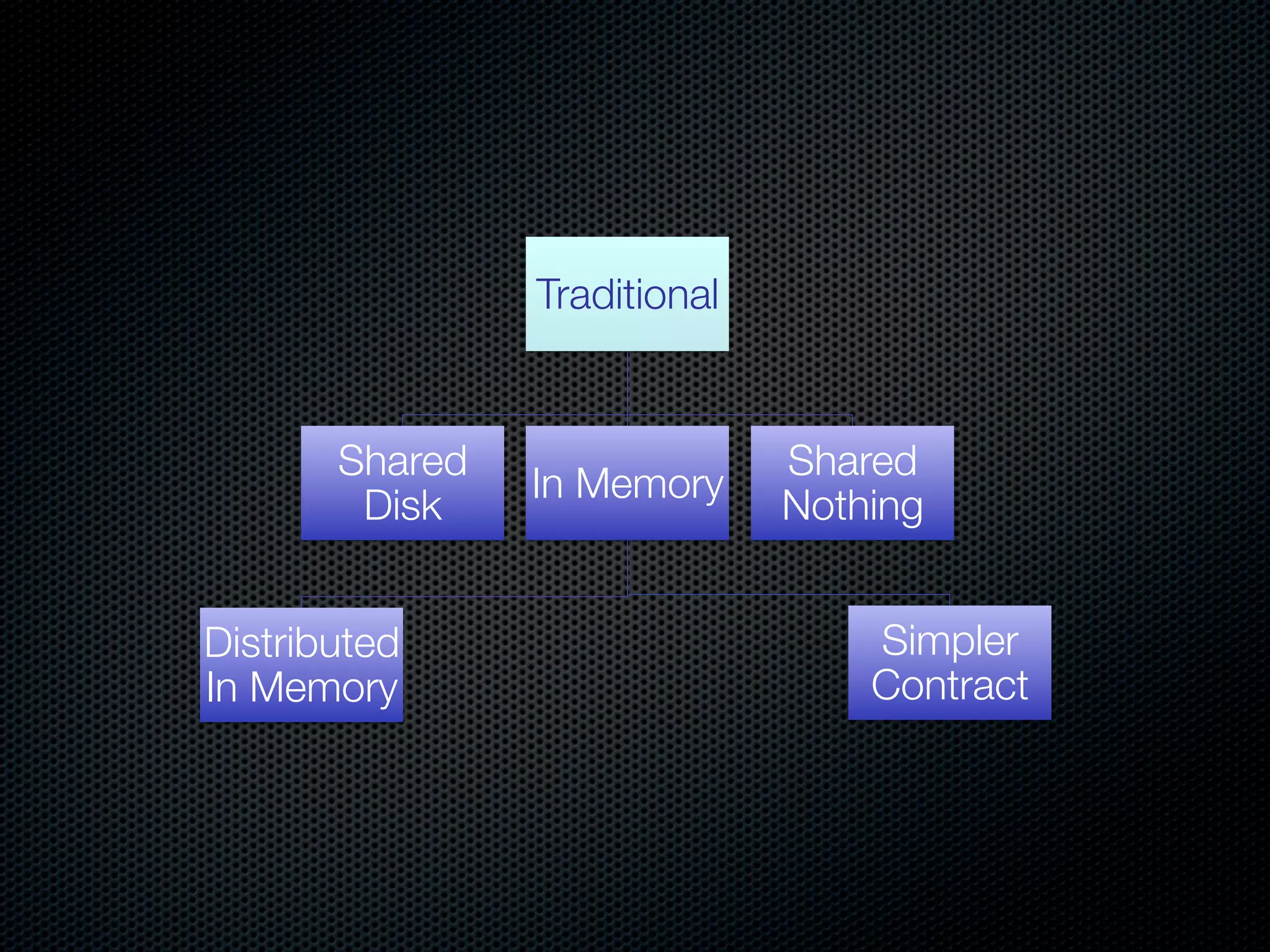
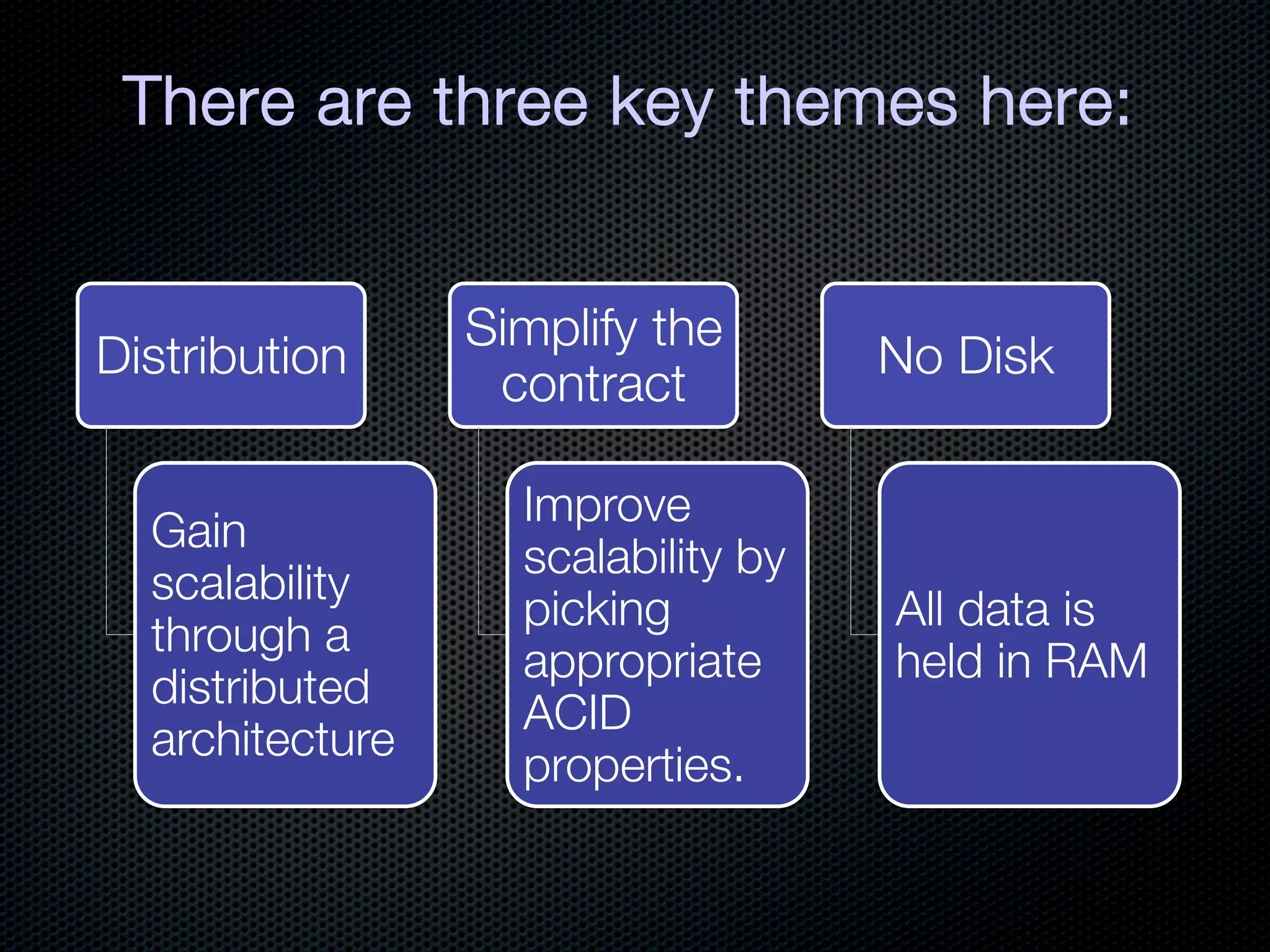

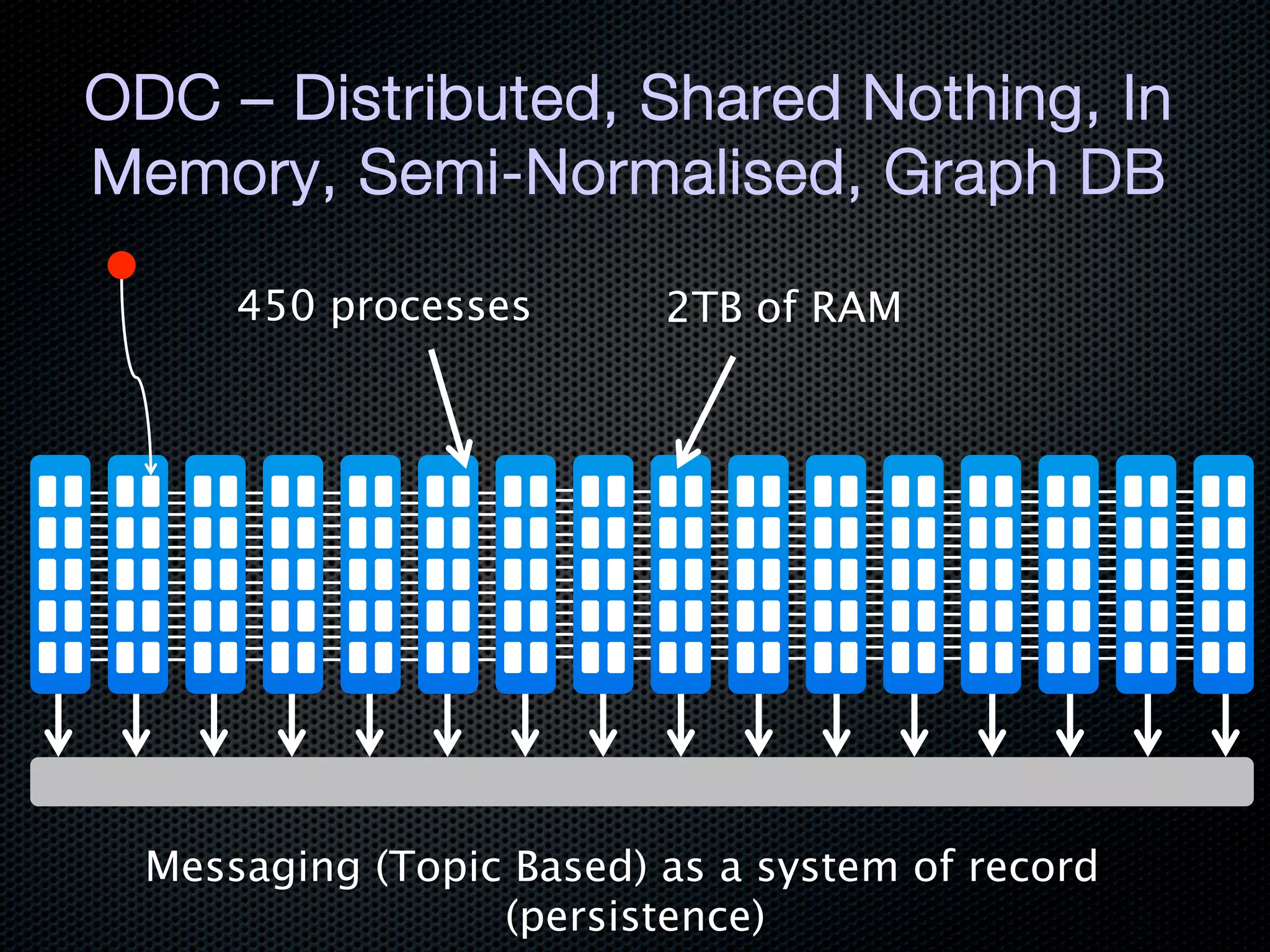



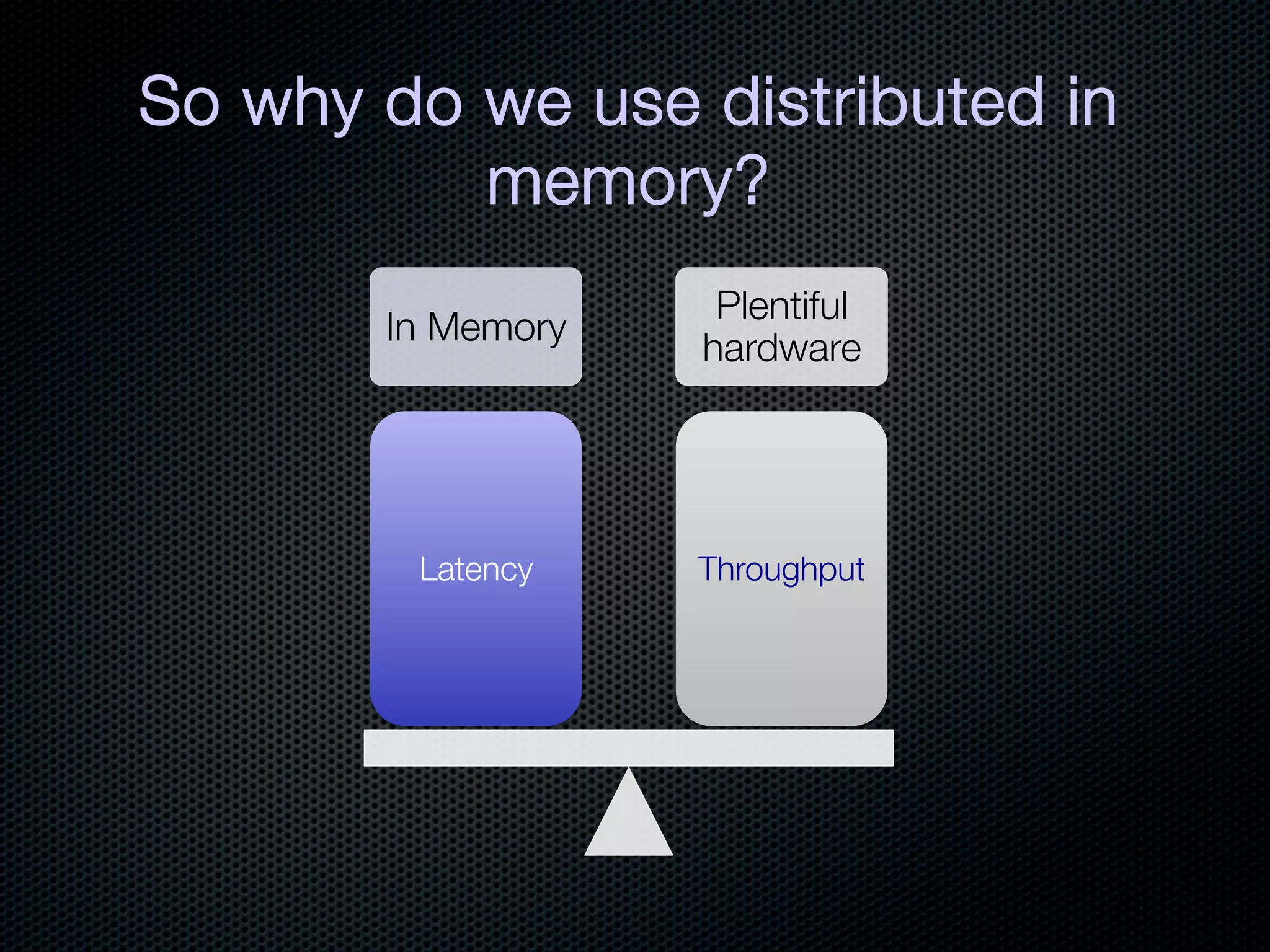









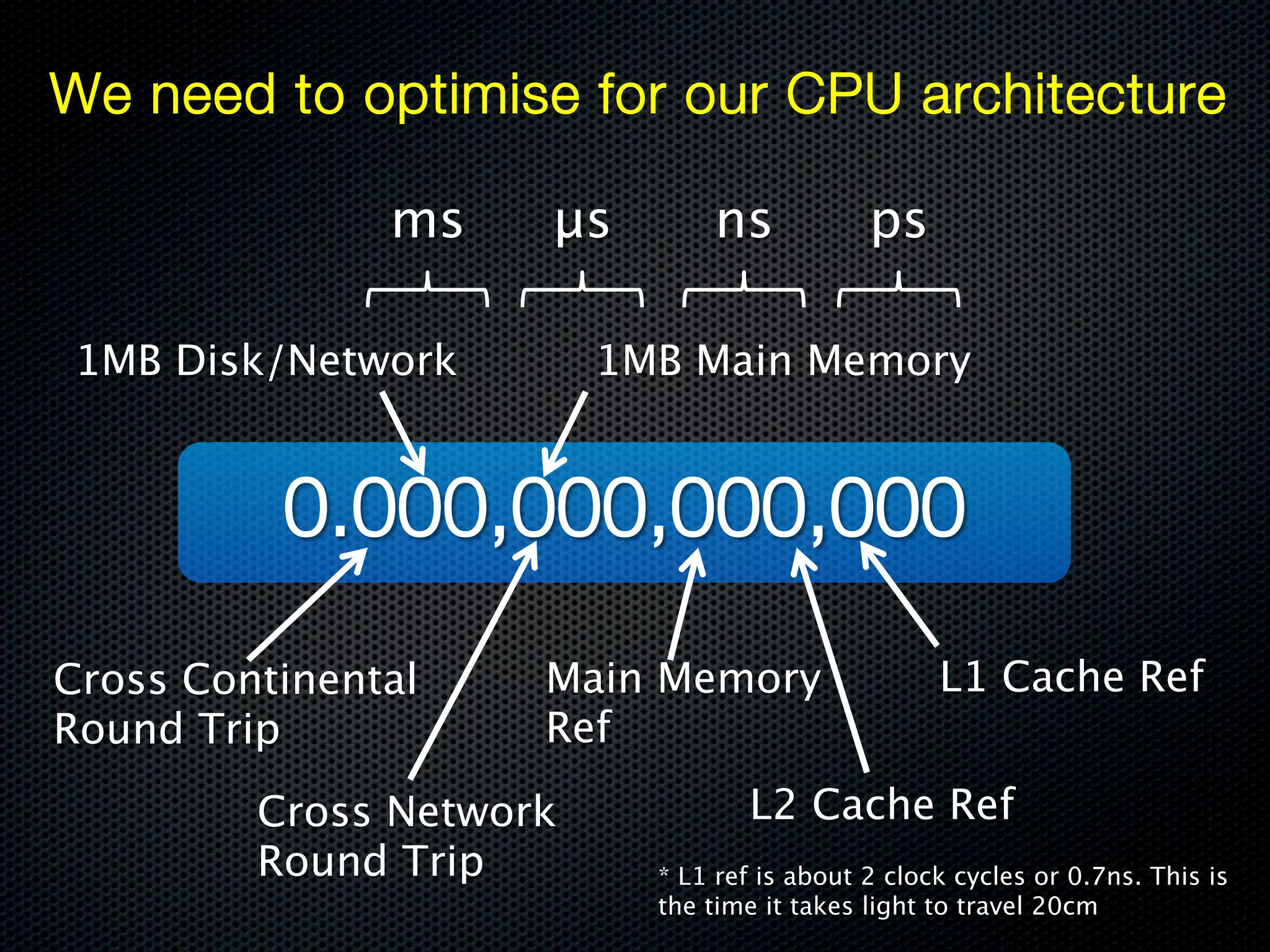




This document discusses the increasing dominance of memory-oriented solutions for high-performance data access. It notes that database lookups are around 20 milliseconds while hashmap lookups are around 20 nanoseconds. It then discusses how abstraction improves software but hurts performance. It outlines the traditional database architecture with disk storage and compares it to newer in-memory and distributed in-memory architectures that can provide faster performance by avoiding disk I/O and leveraging memory and distribution.





















































































