Downloaded 33 times




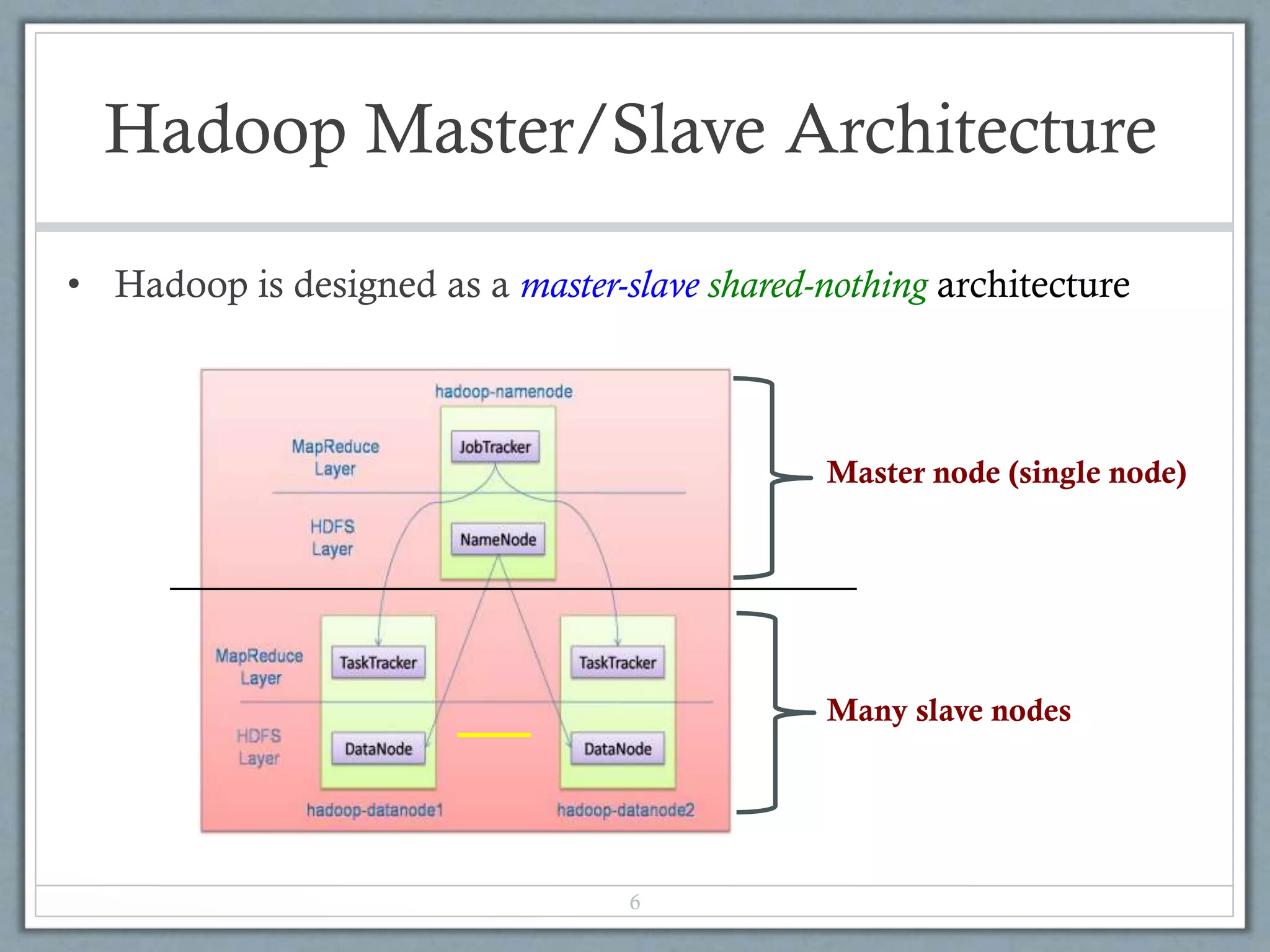





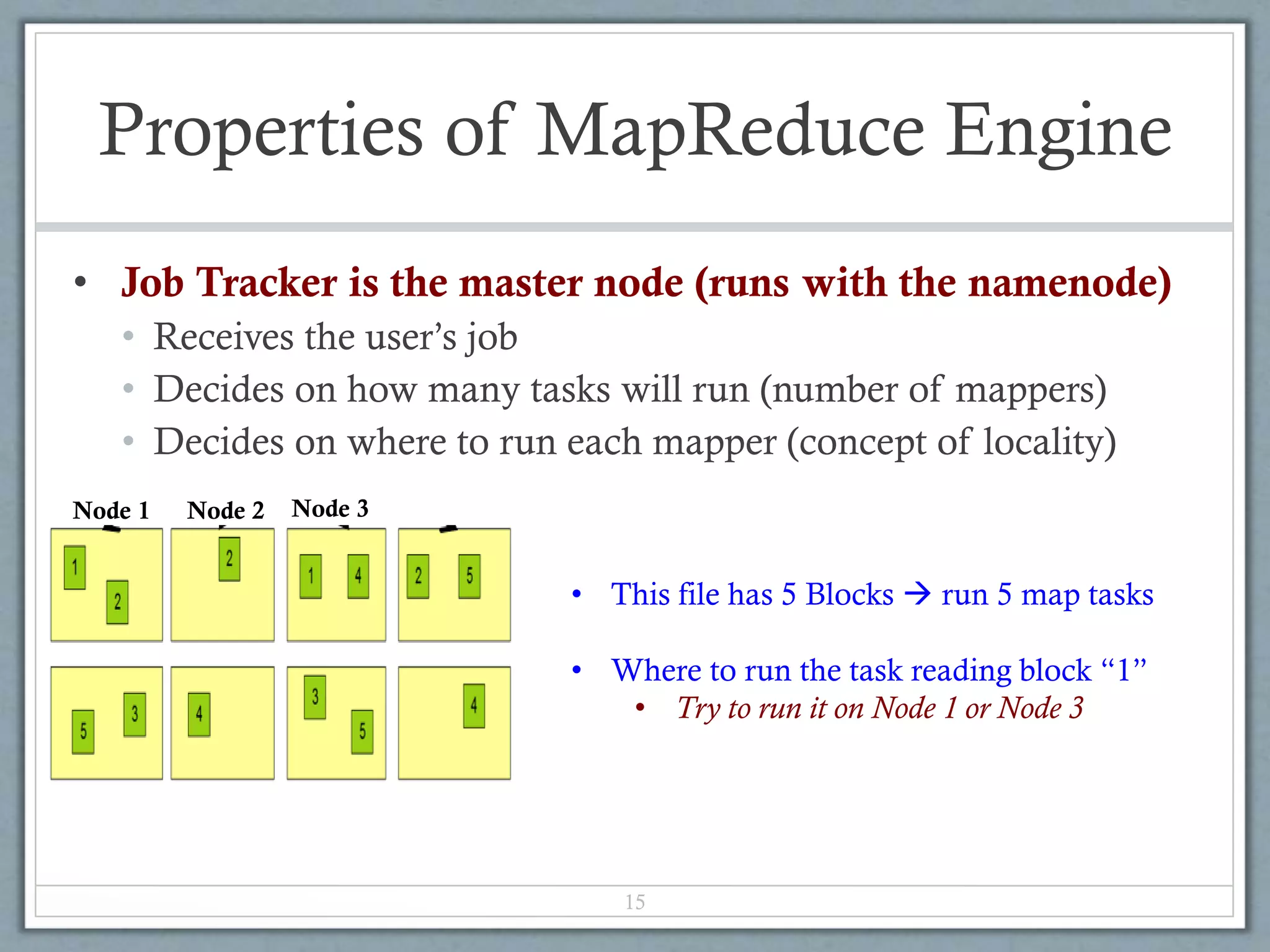
![Map-Reduce Execution Engine
(Example: Color Count)
14
Shuffle & Sorting
based on k
Reduce
Reduce
Reduce
Map
Map
Map
Map
Input blocks
on HDFS
Produces (k, v)
( , 1)
Parse-hash
Parse-hash
Parse-hash
Parse-hash
Consumes(k, [v])
( , [1,1,1,1,1,1..])
Produces(k’, v’)
( , 100)
Users only provide the “Map” and “Reduce” functions](https://image.slidesharecdn.com/hadoop-140318113954-phpapp01/75/Hadoop-14-2048.jpg)

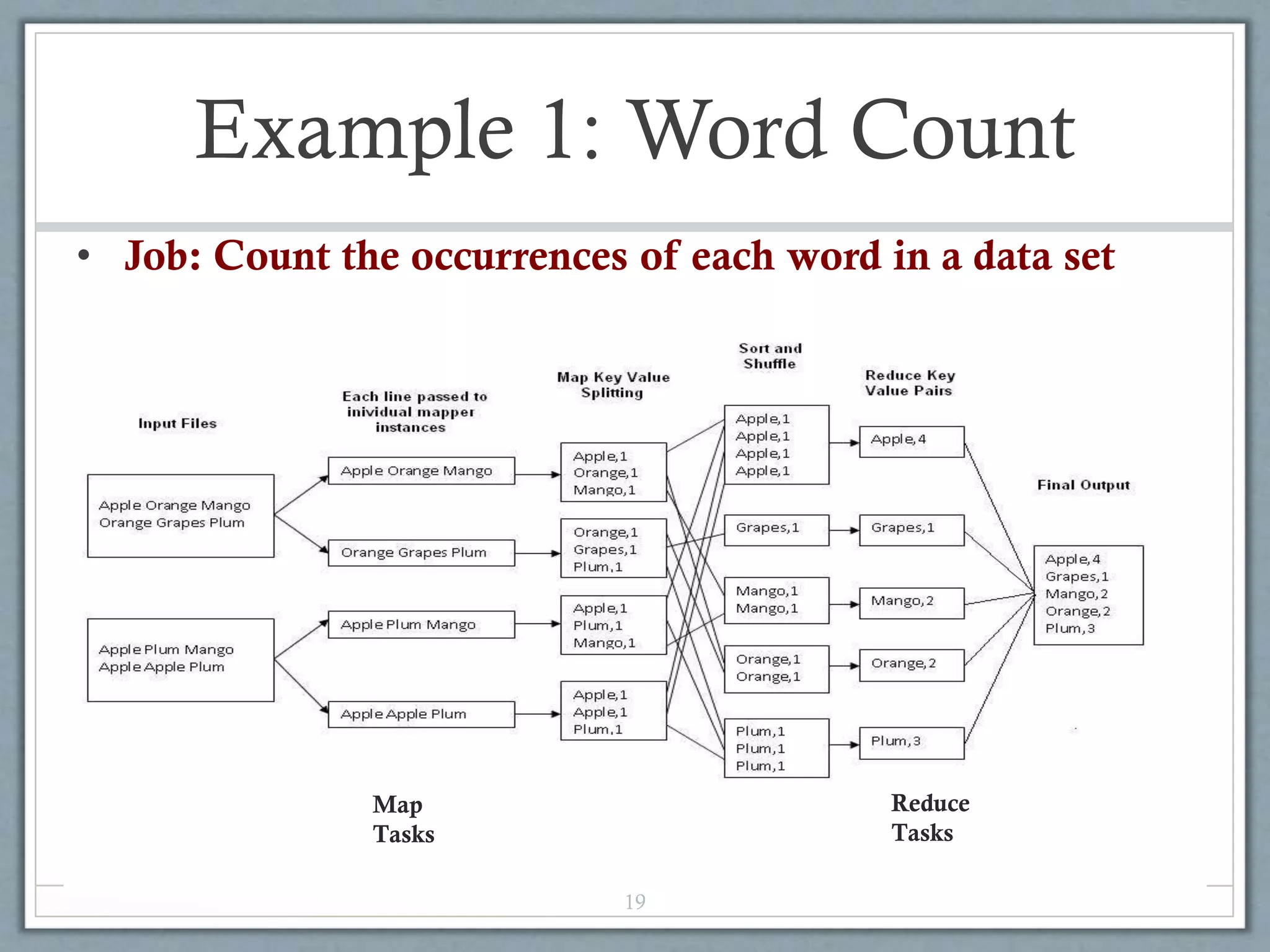
![Example 2: Color Count
20
Shuffle & Sorting
based on k
Reduce
Reduce
Reduce
Map
Map
Map
Map
Input blocks
on HDFS
Produces (k, v)
( , 1)
Parse-hash
Parse-hash
Parse-hash
Parse-hash
Consumes(k, [v])
( , [1,1,1,1,1,1..])
Produces(k’, v’)
( , 100)
Job: Count the number of each color in a data set
Part0003
Part0002
Part0001
That’s the output file, it
has 3 parts on probably 3
different machines](https://image.slidesharecdn.com/hadoop-140318113954-phpapp01/75/Hadoop-20-2048.jpg)

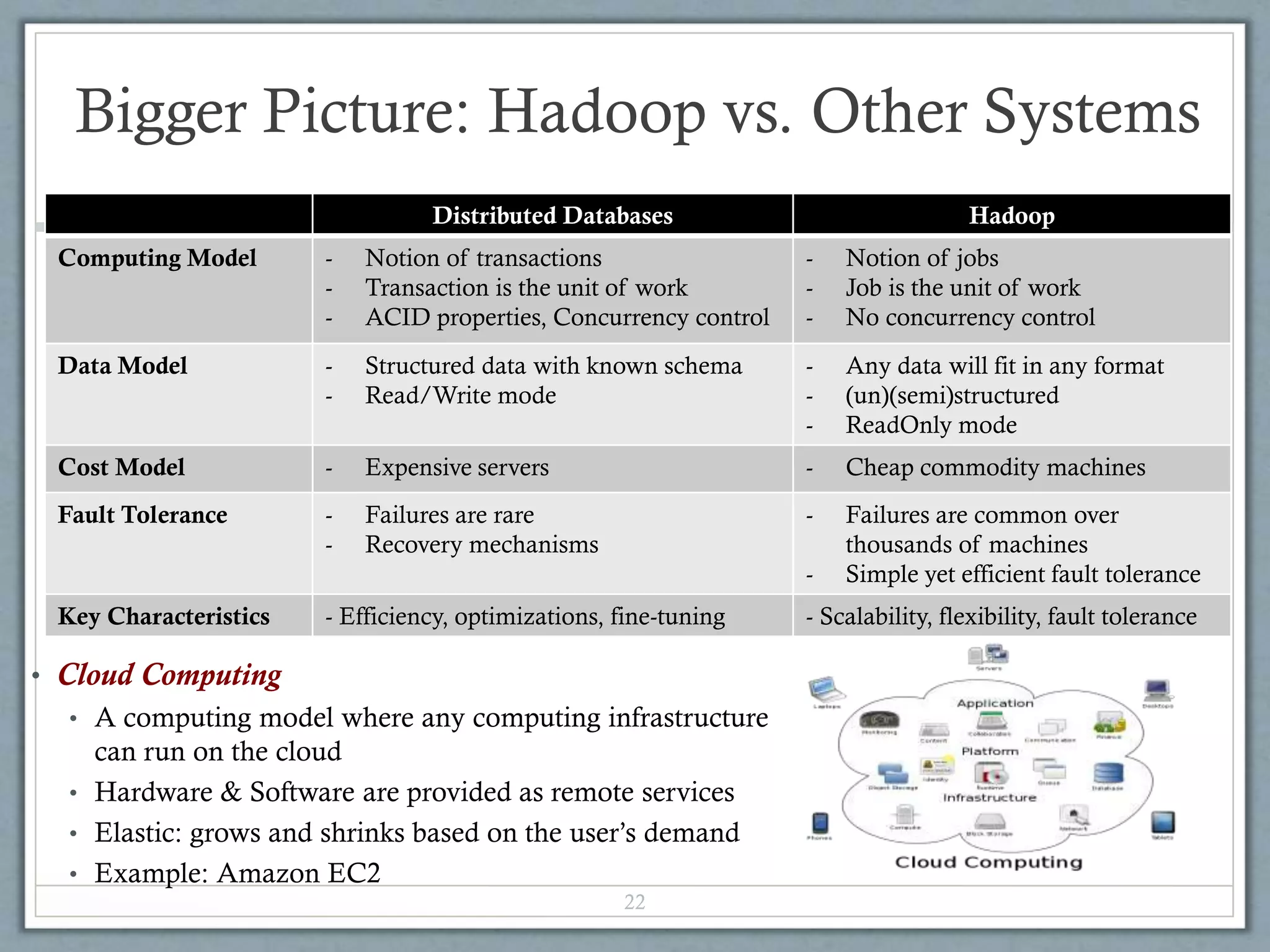

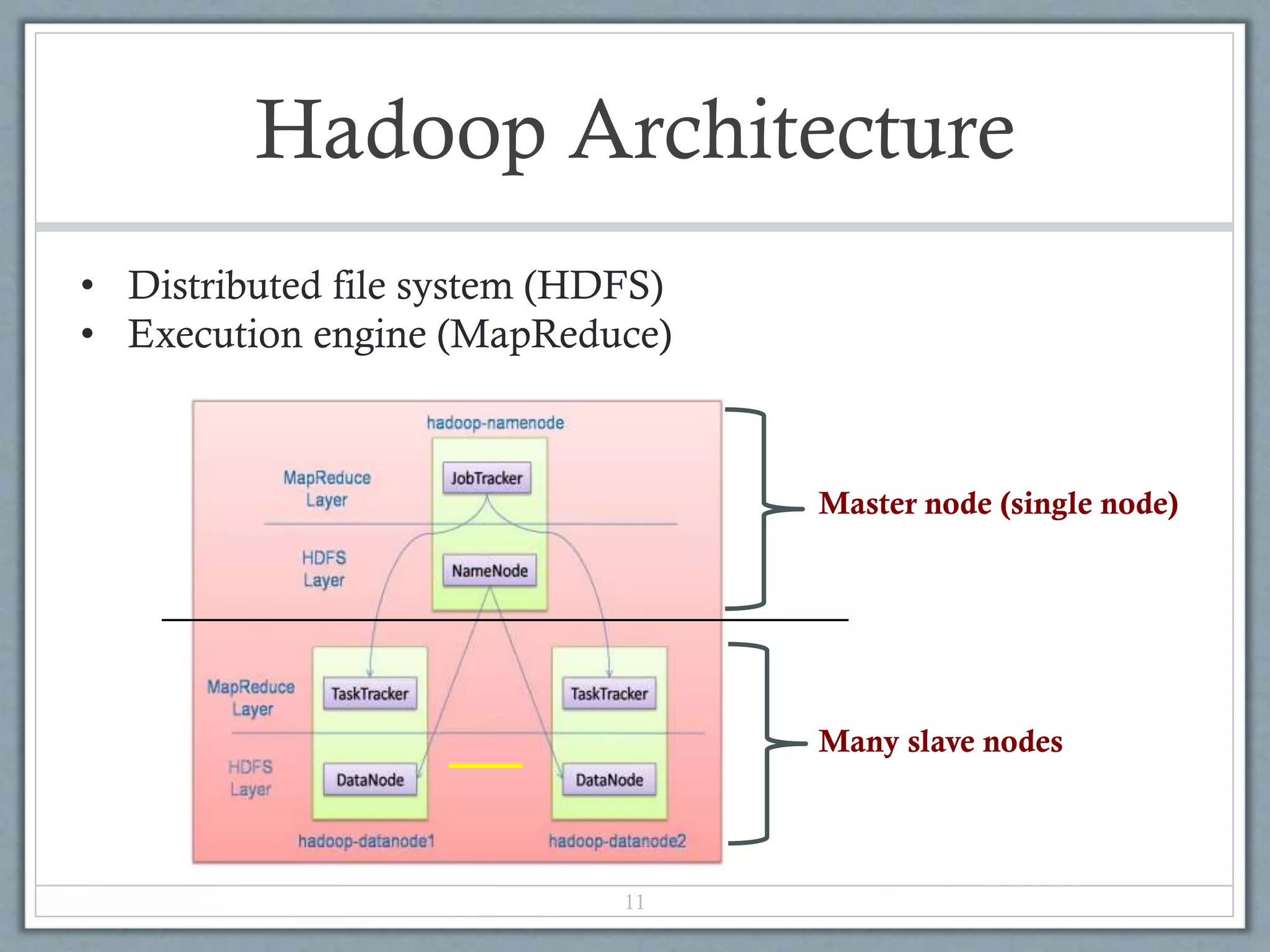
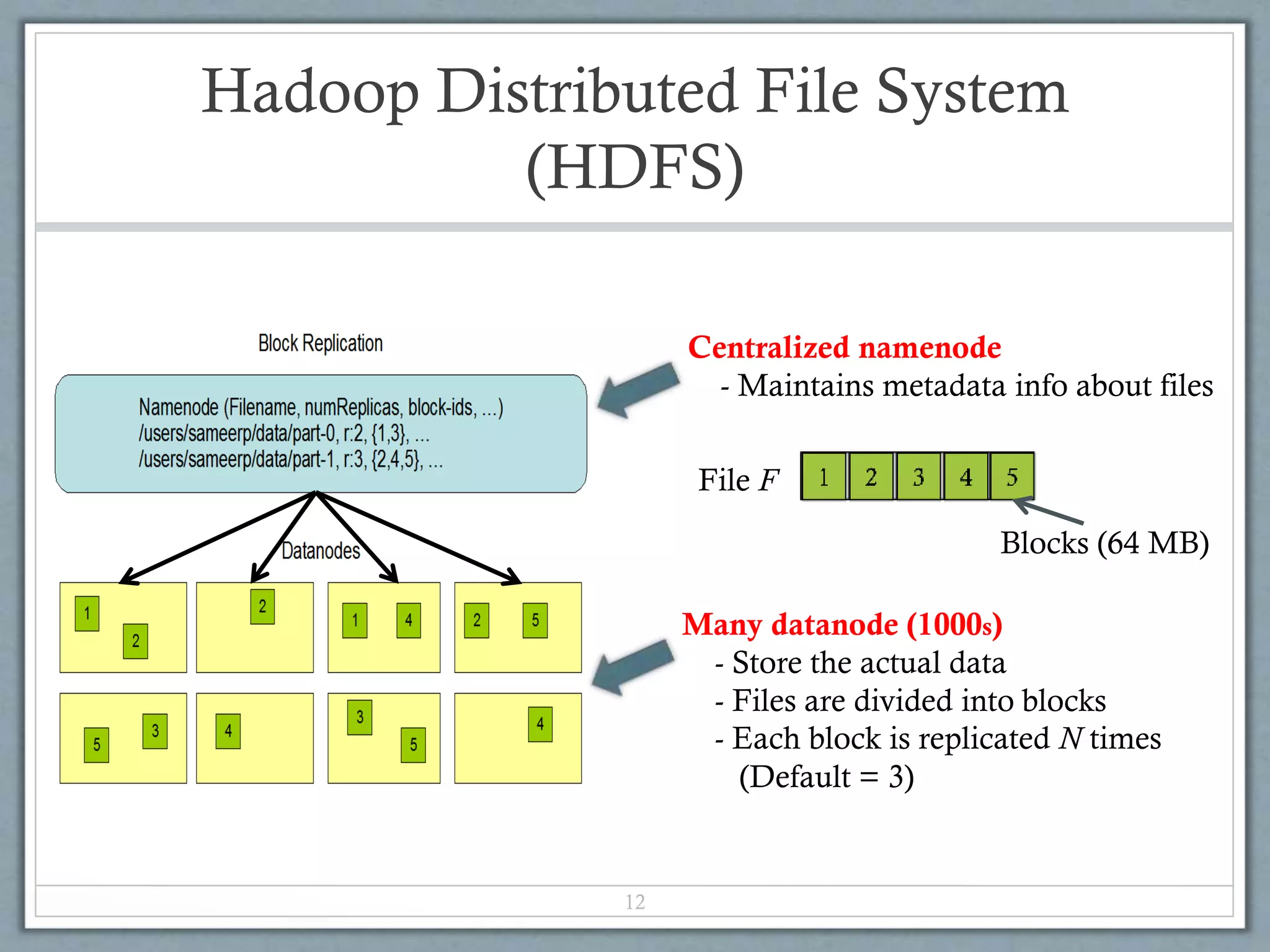
Hadoop is an open-source software framework for distributed storage and processing of large datasets across clusters of commodity hardware. It uses a simple programming model called MapReduce that automatically parallelizes and distributes work across nodes. Hadoop consists of Hadoop Distributed File System (HDFS) for storage and MapReduce execution engine for processing. HDFS stores data as blocks replicated across nodes for fault tolerance. MapReduce jobs are split into map and reduce tasks that process key-value pairs in parallel. Hadoop is well-suited for large-scale data analytics as it scales to petabytes of data and thousands of machines with commodity hardware.



































































