Downloaded 187 times














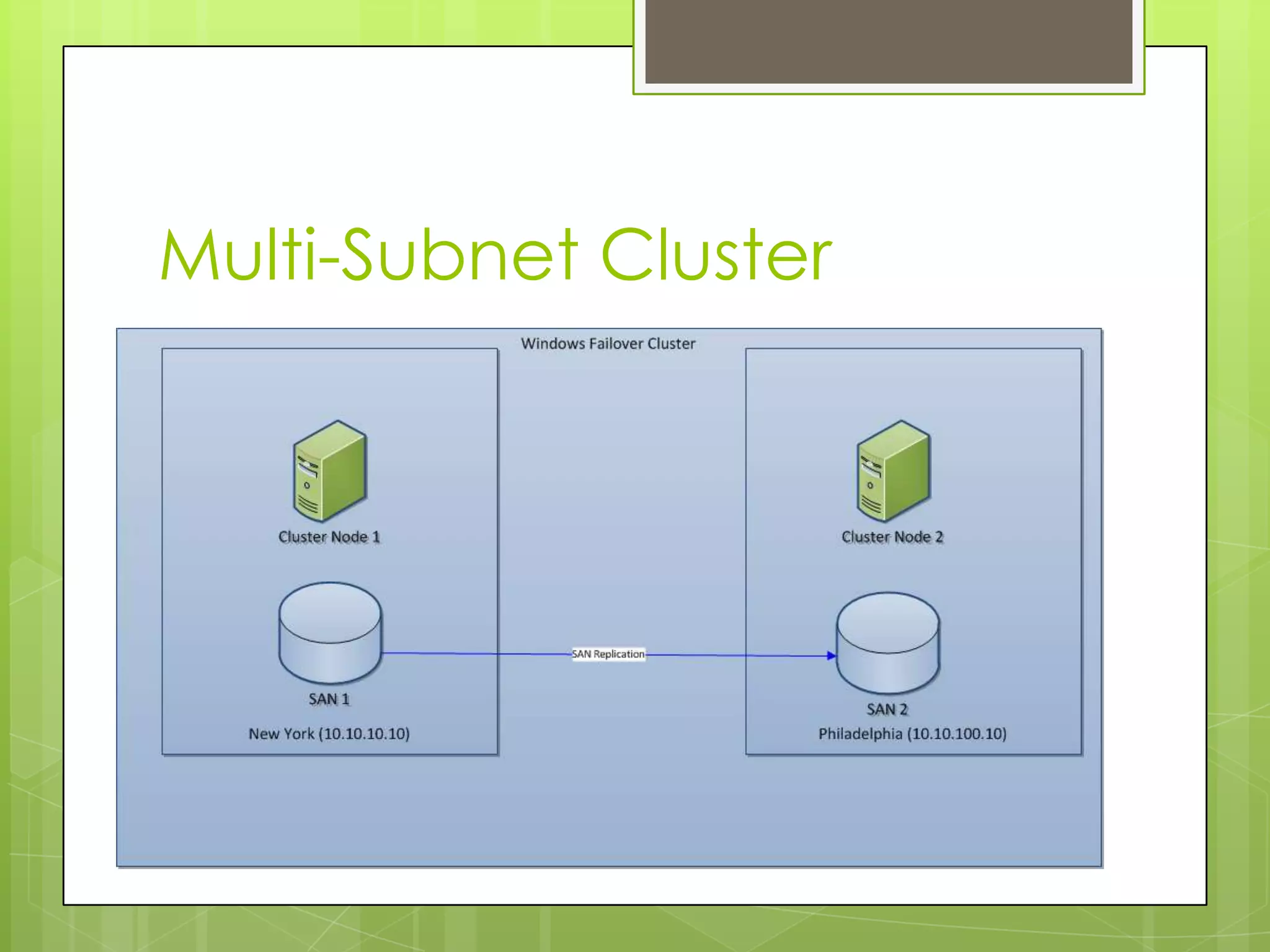





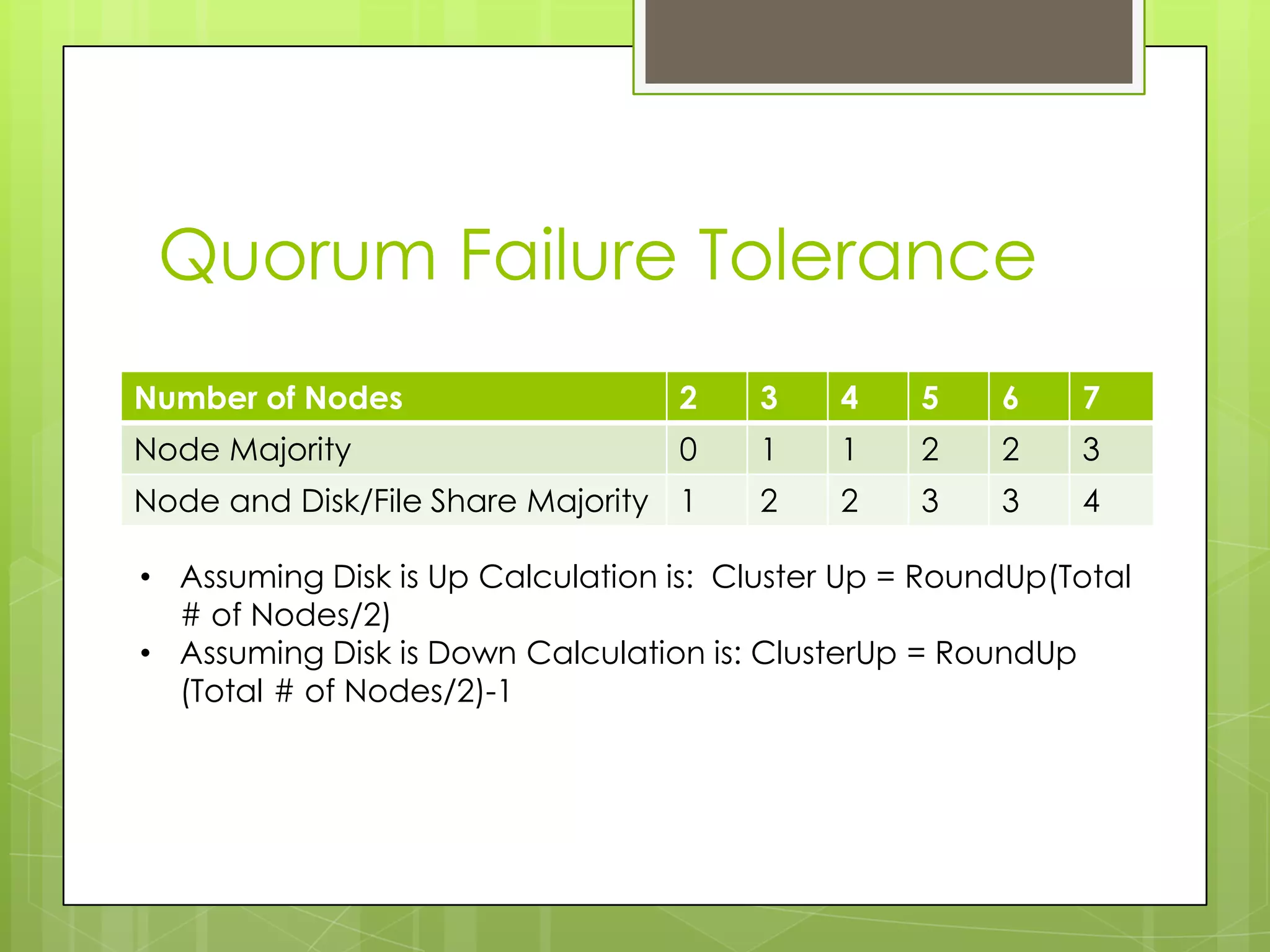


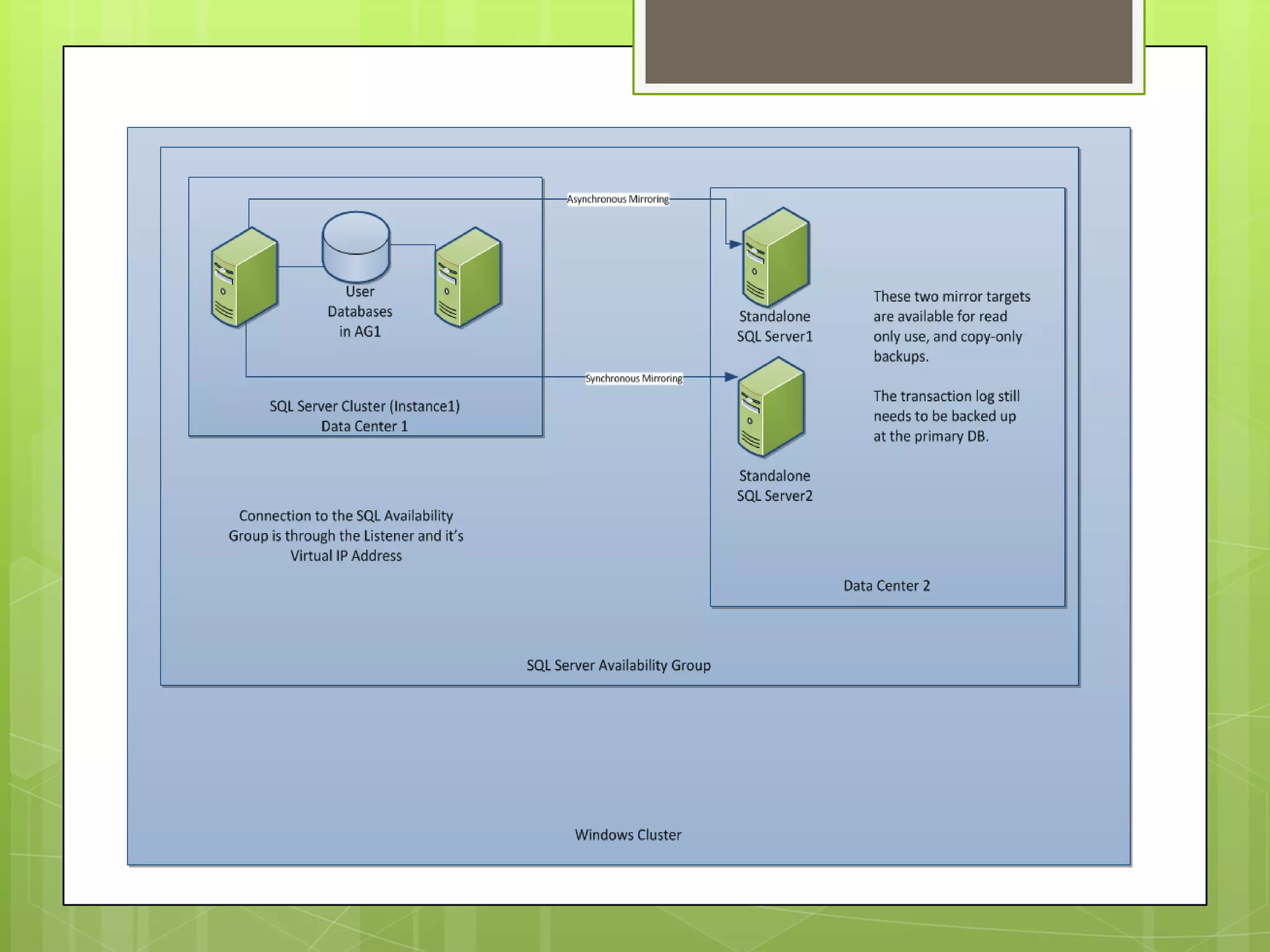




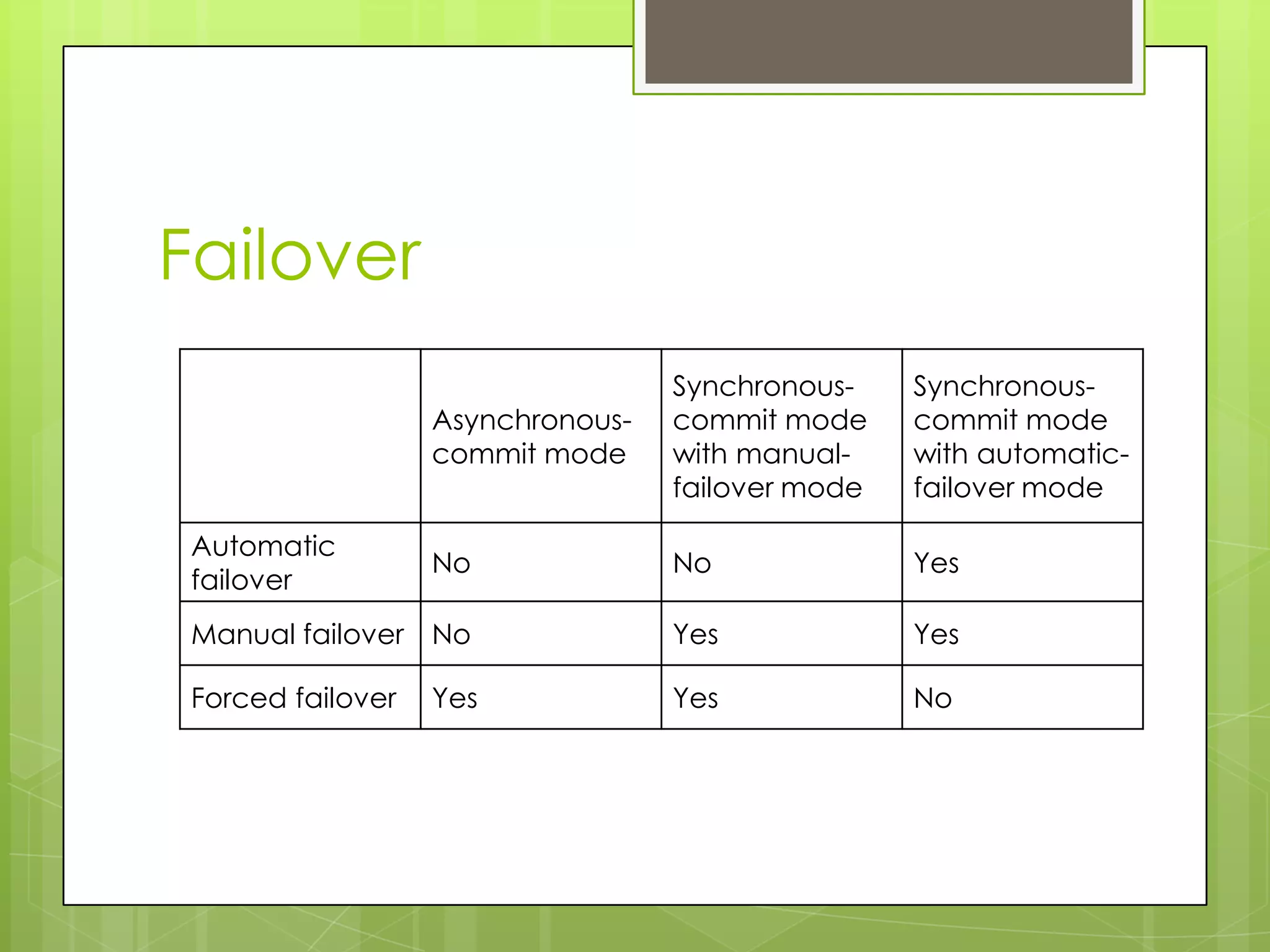








This document provides an overview and agenda for a presentation on SQL Server 2012 high availability and disaster recovery capabilities. The presentation covers changes from SQL Server 2008 to 2012 in HA and DR options, including availability groups which allow for database mirroring across multiple servers without shared storage. Licensing changes are also discussed. The objectives are to explain SQL clustering, how it works, and what's new in SQL Server 2012 for HA and DR.








































































































