Downloaded 249 times
































The document discusses Apache Kafka, a distributed publish-subscribe messaging system developed at LinkedIn. It describes how LinkedIn uses Kafka to integrate large amounts of user activity and other data across its products. Key aspects of Kafka's design allow it to scale to LinkedIn's high throughput requirements, including using a log structure and data partitioning for parallelism. LinkedIn relies on Kafka to transport over 500 billion messages per day between systems and for real-time analytics.
Overview of the presentation and what attendees can expect to learn about Kafka's design and usage.
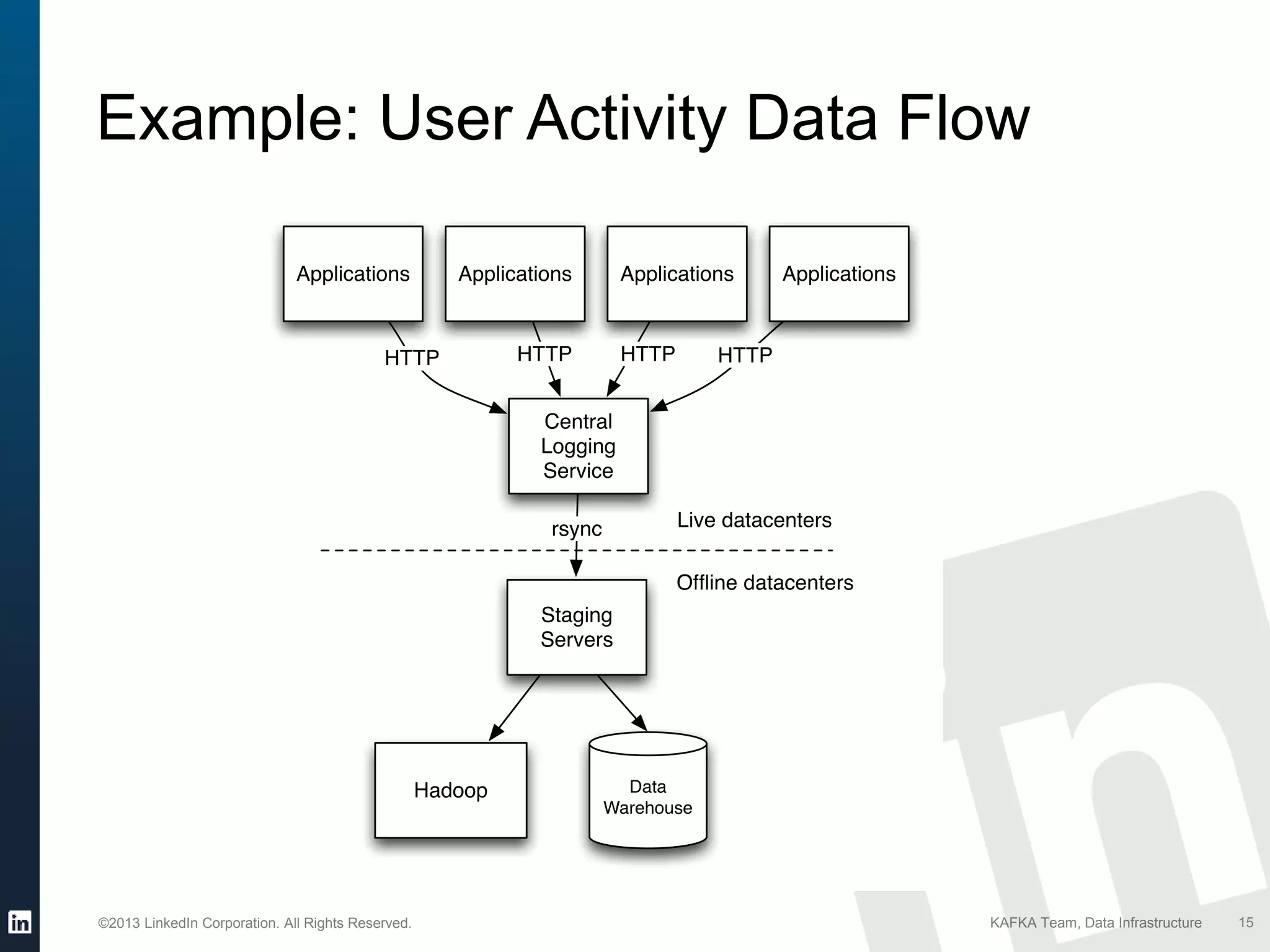
Introduction to the data challenges at LinkedIn including user tracking, server logs, and messaging.
Discussion on various data-driven products like Newsfeed, Recommendations, and Search functionality.
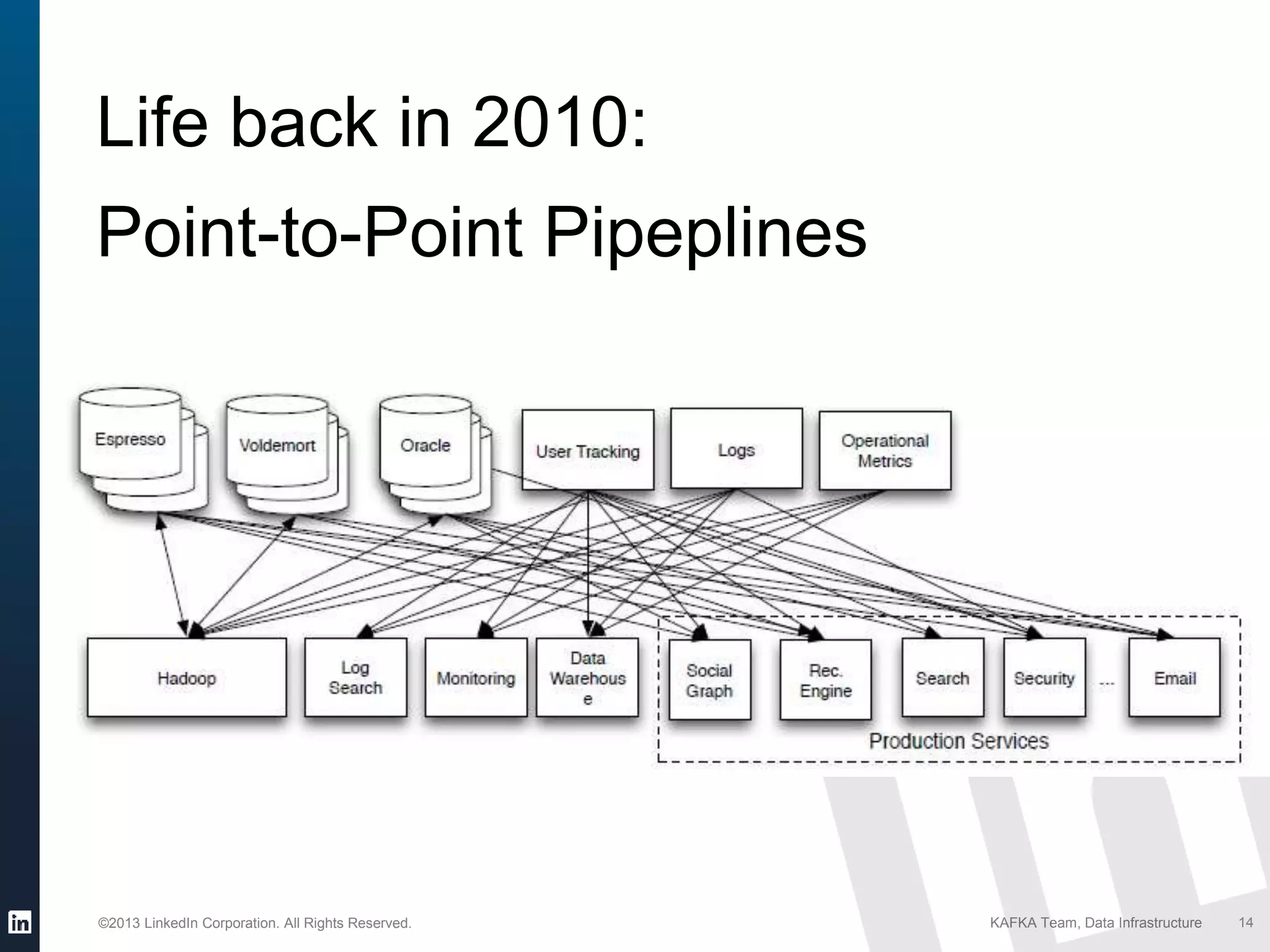
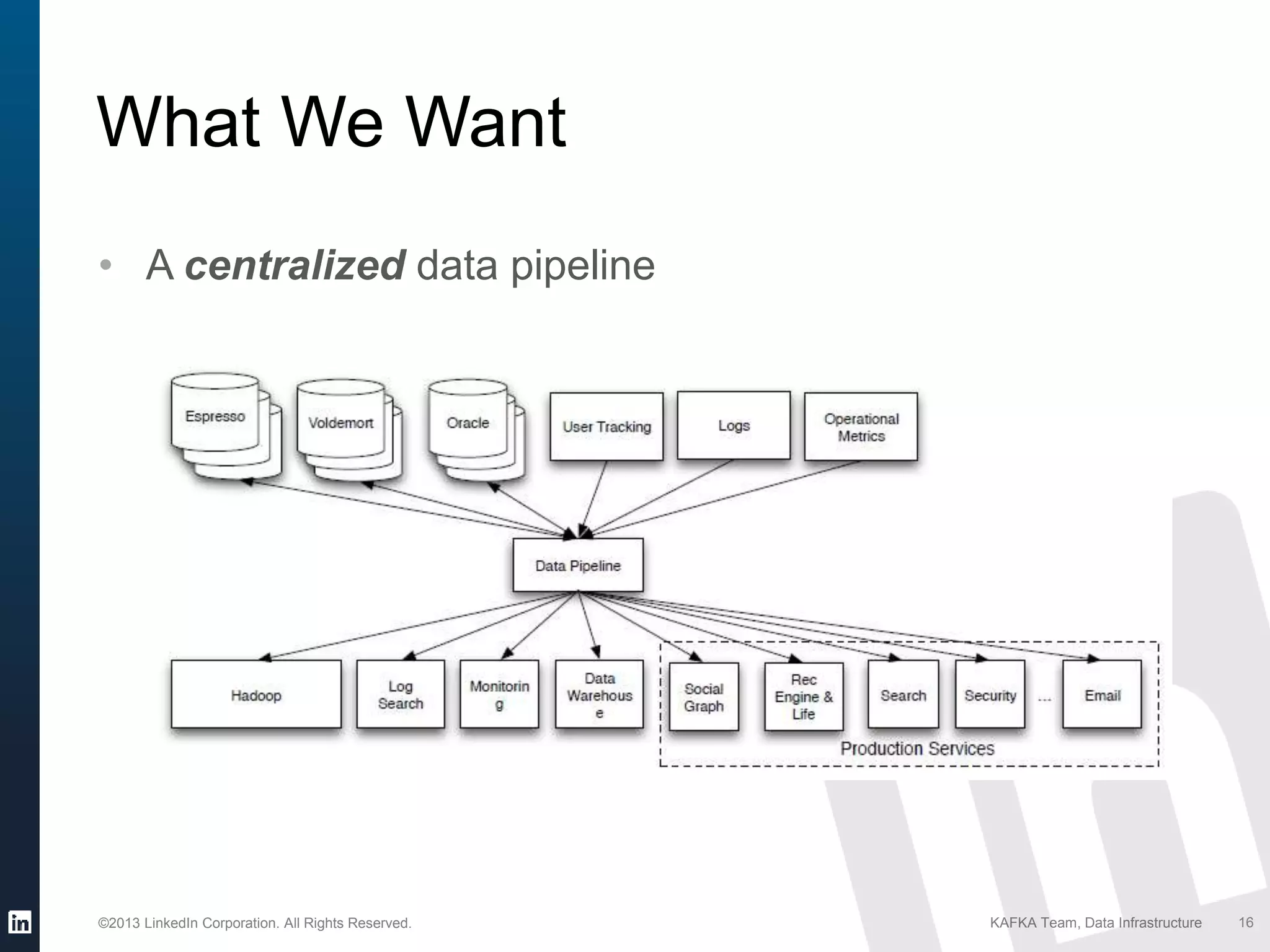
Identifying the need for integrating diverse data sources into a unified system to support various products.
Outlines what LinkedIn desired from a data pipeline including scalability, durability, and ease of use.
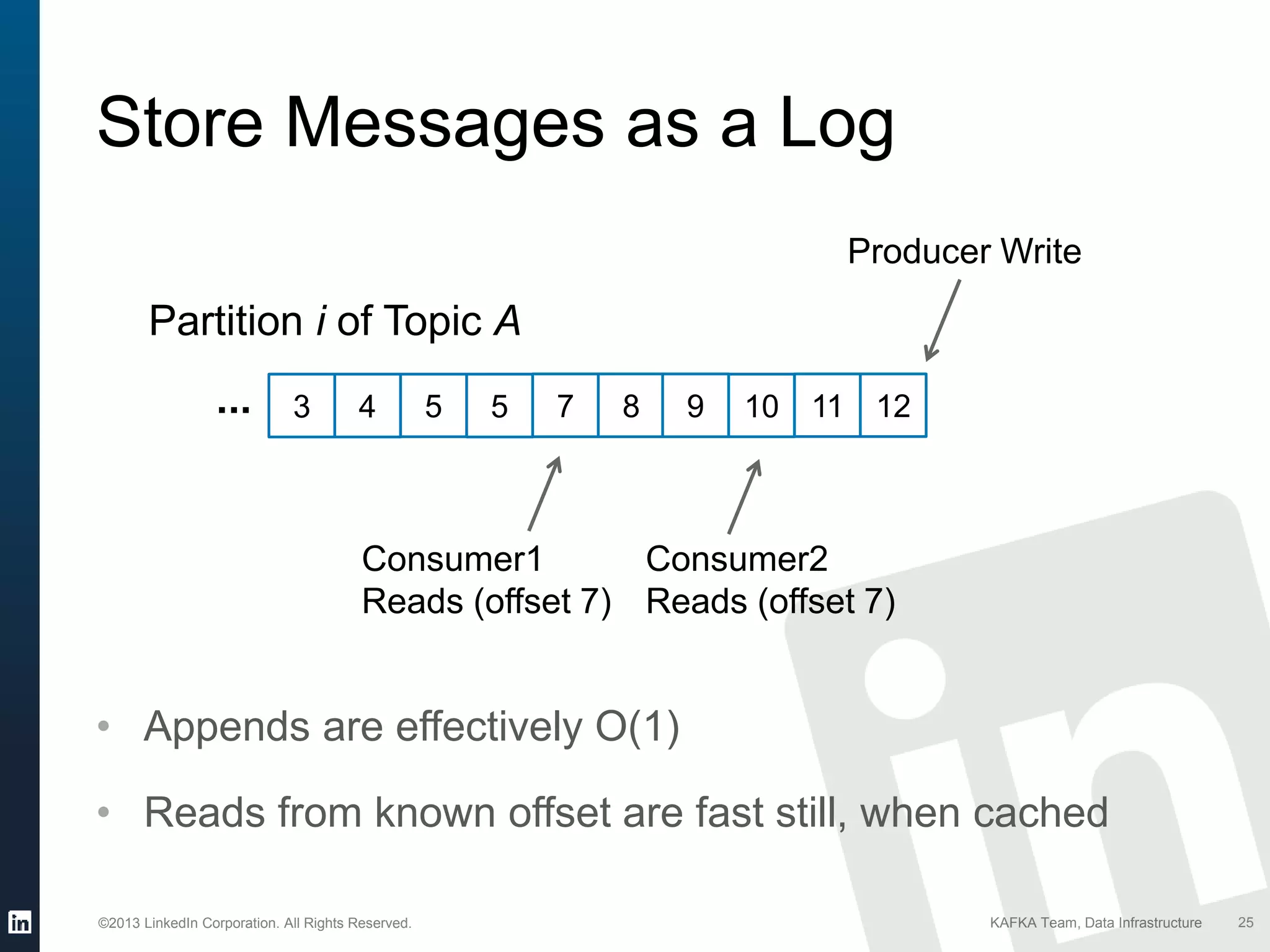
Kafka's characteristics such as scalability, fast disk usage, and efficient batch transfer for networking.
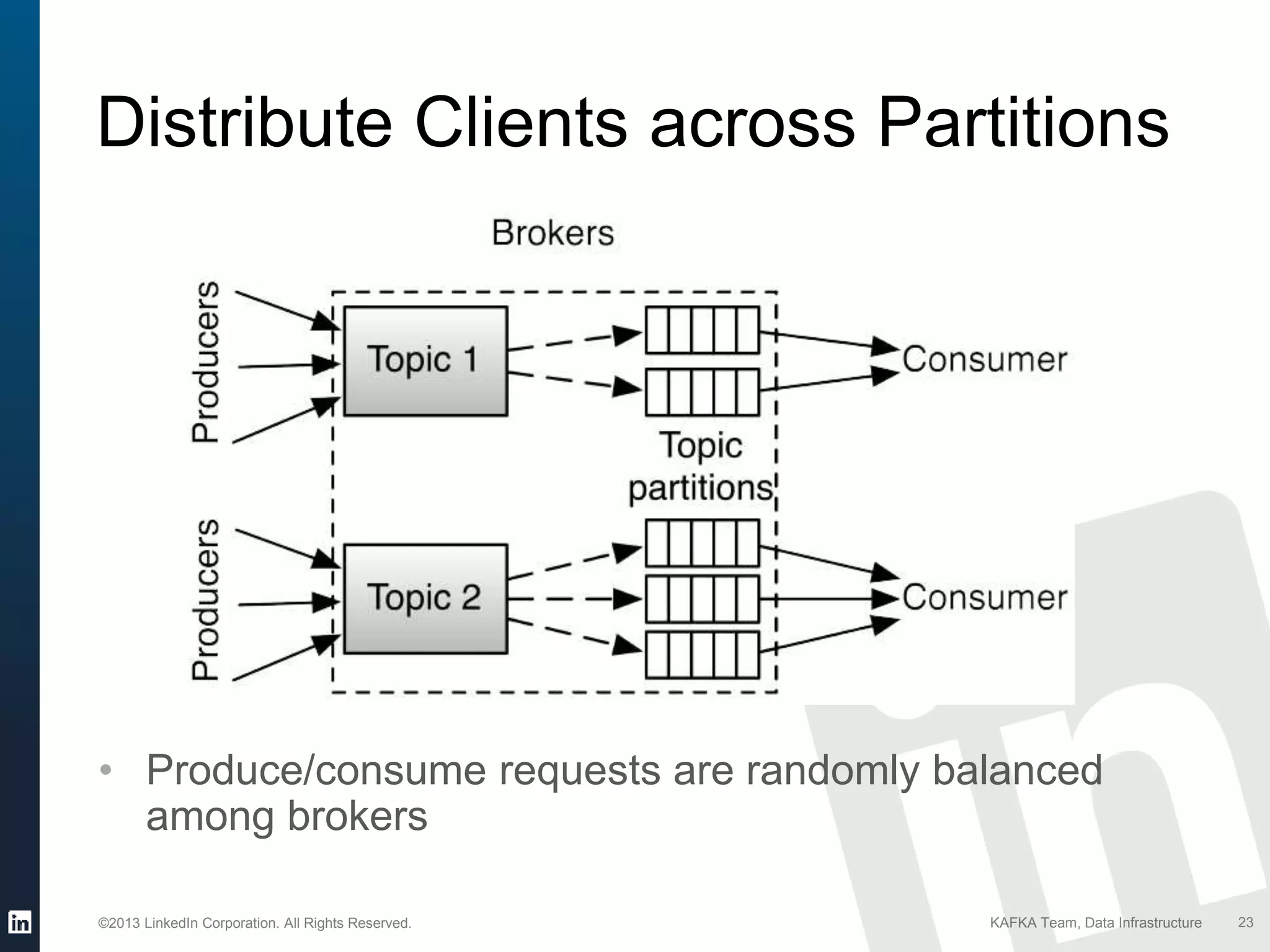
Summary of Kafka API features for producers and consumers including how messages are handled.
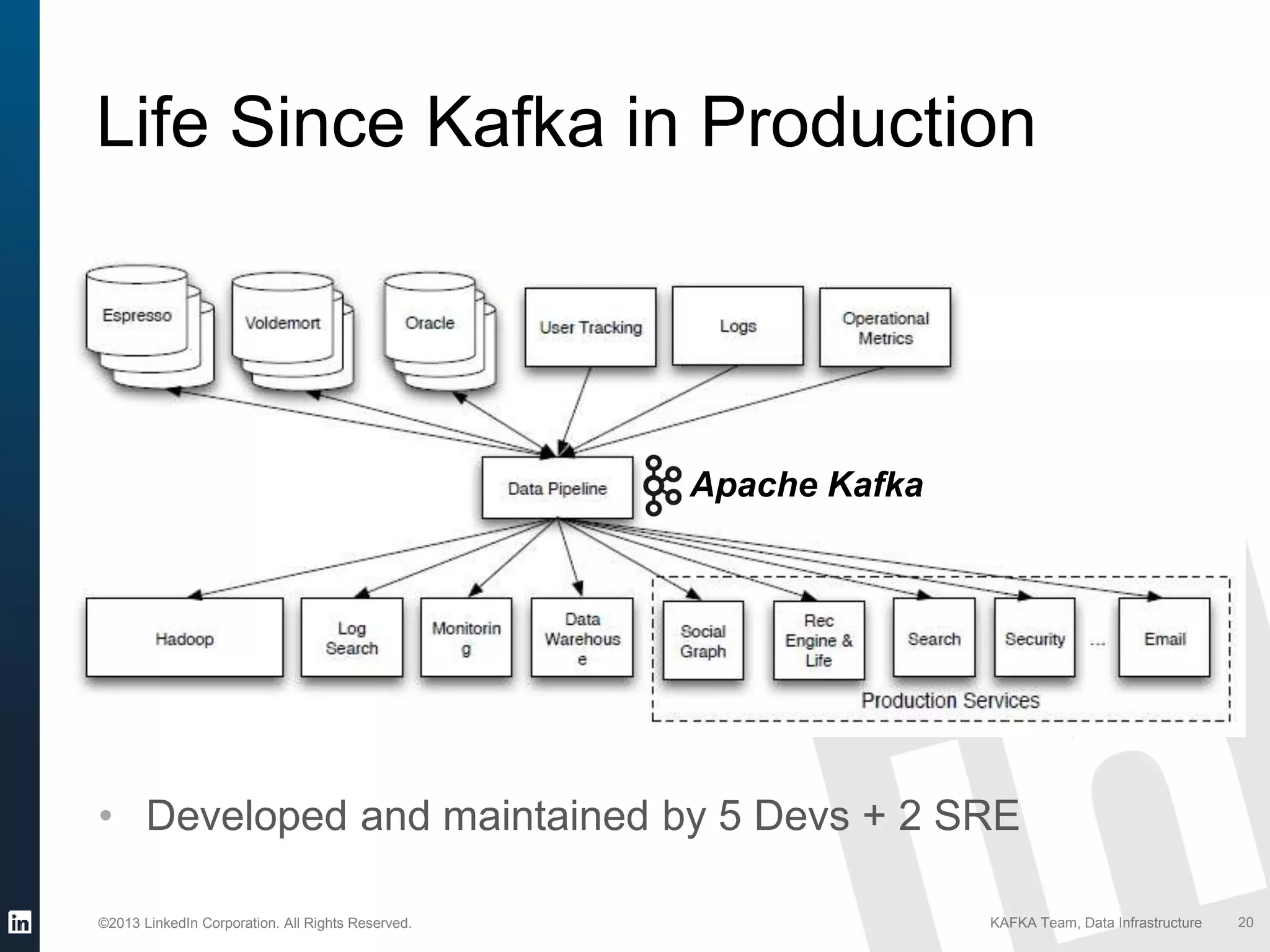
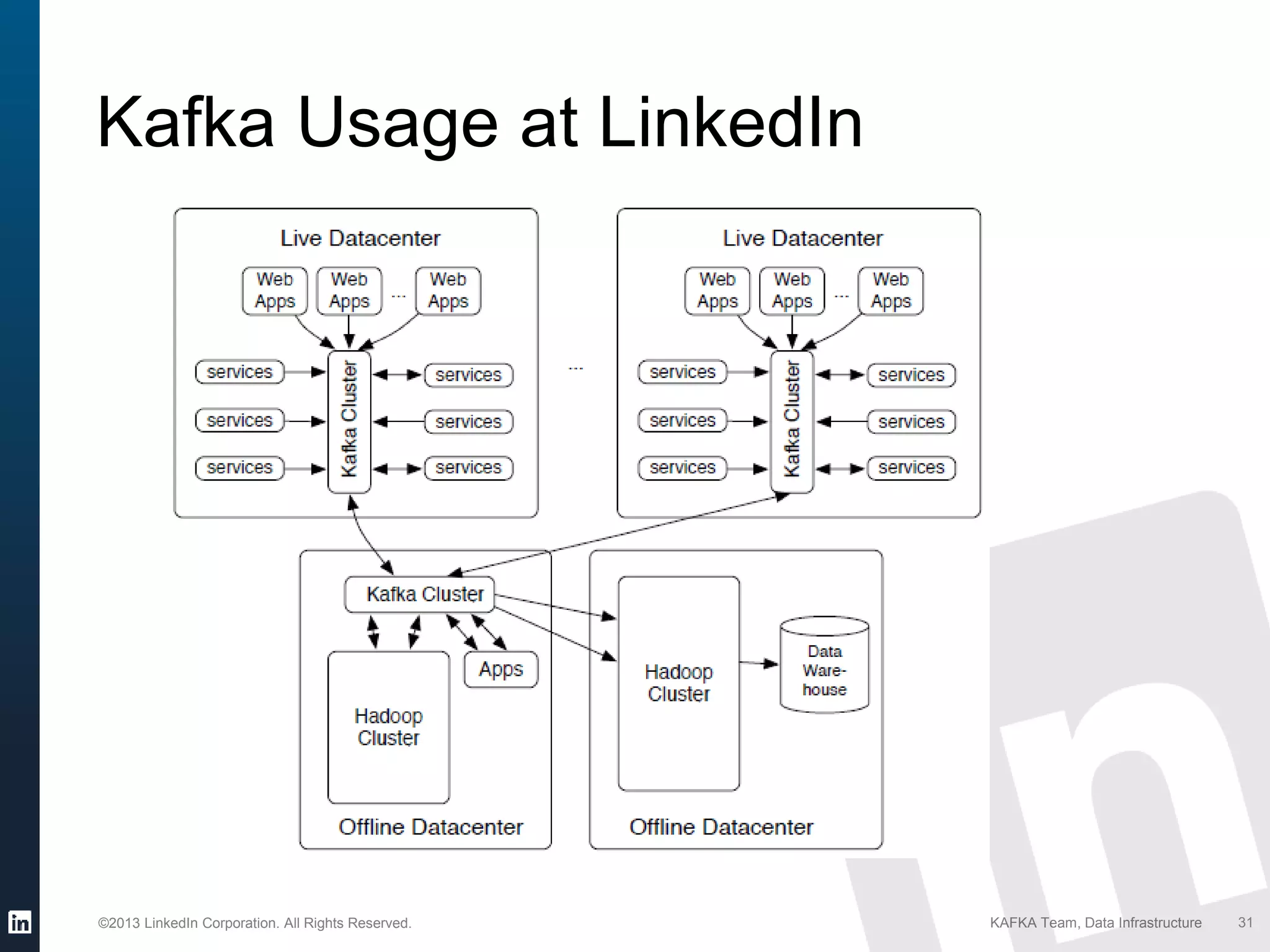
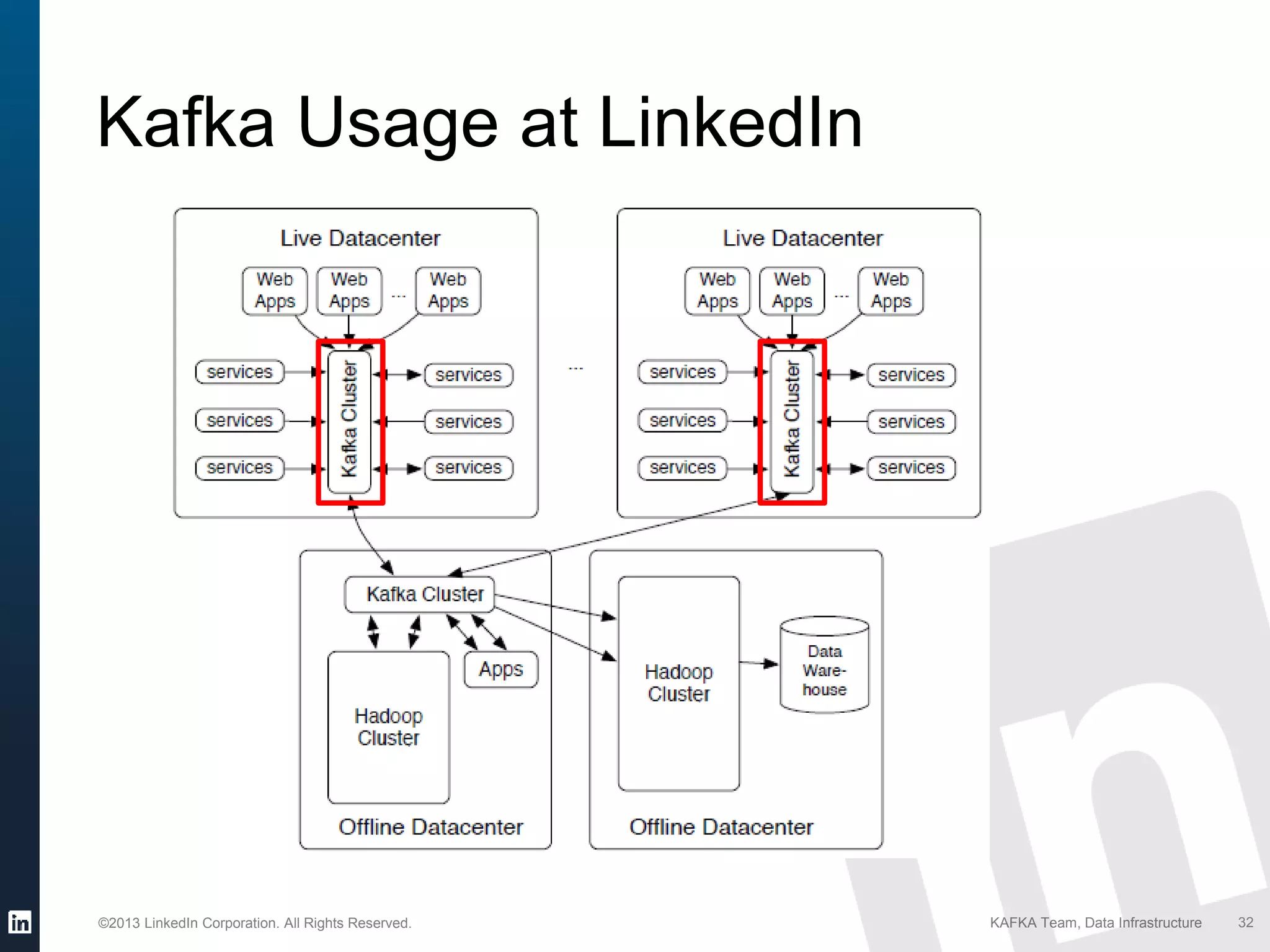
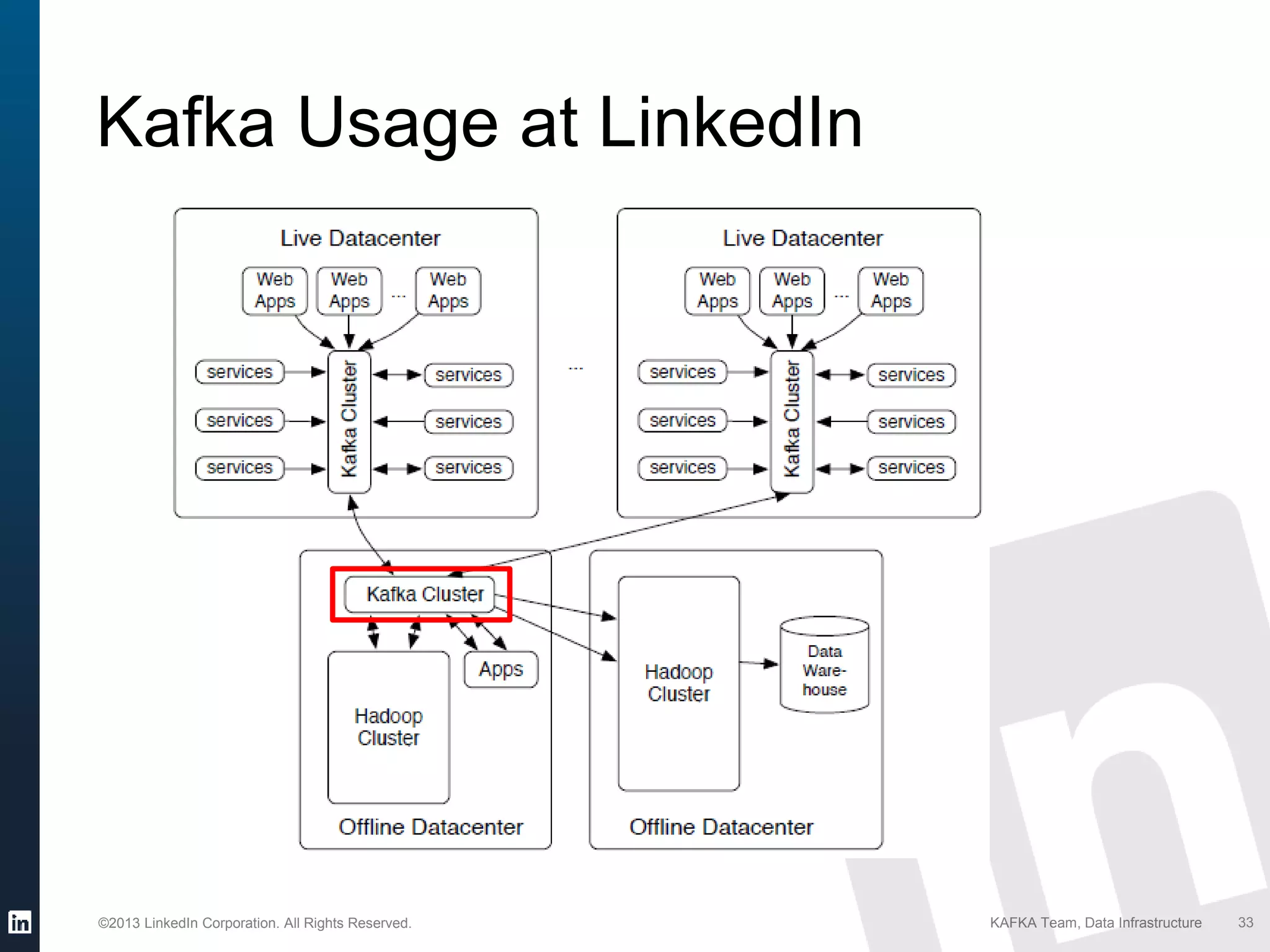
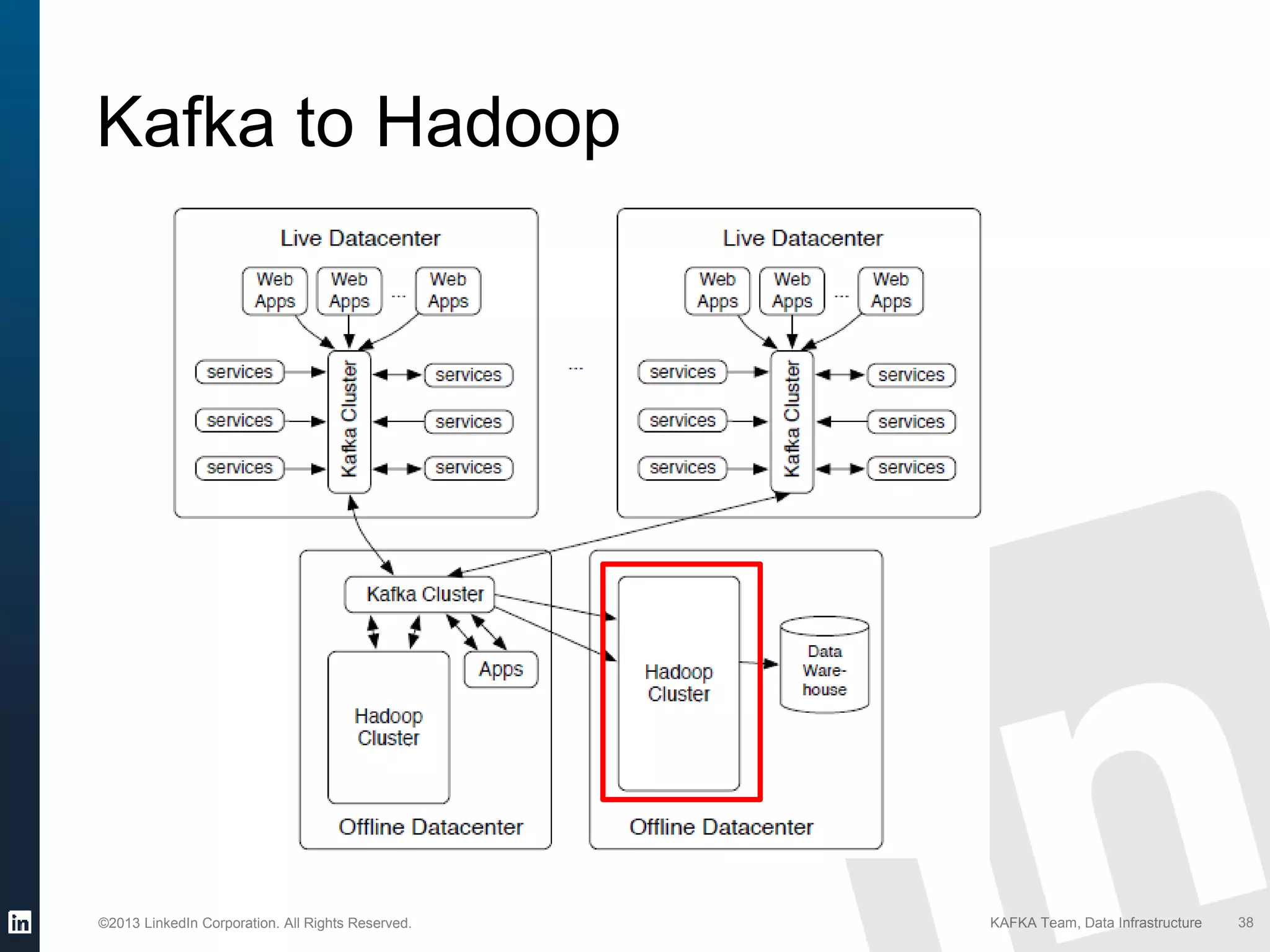
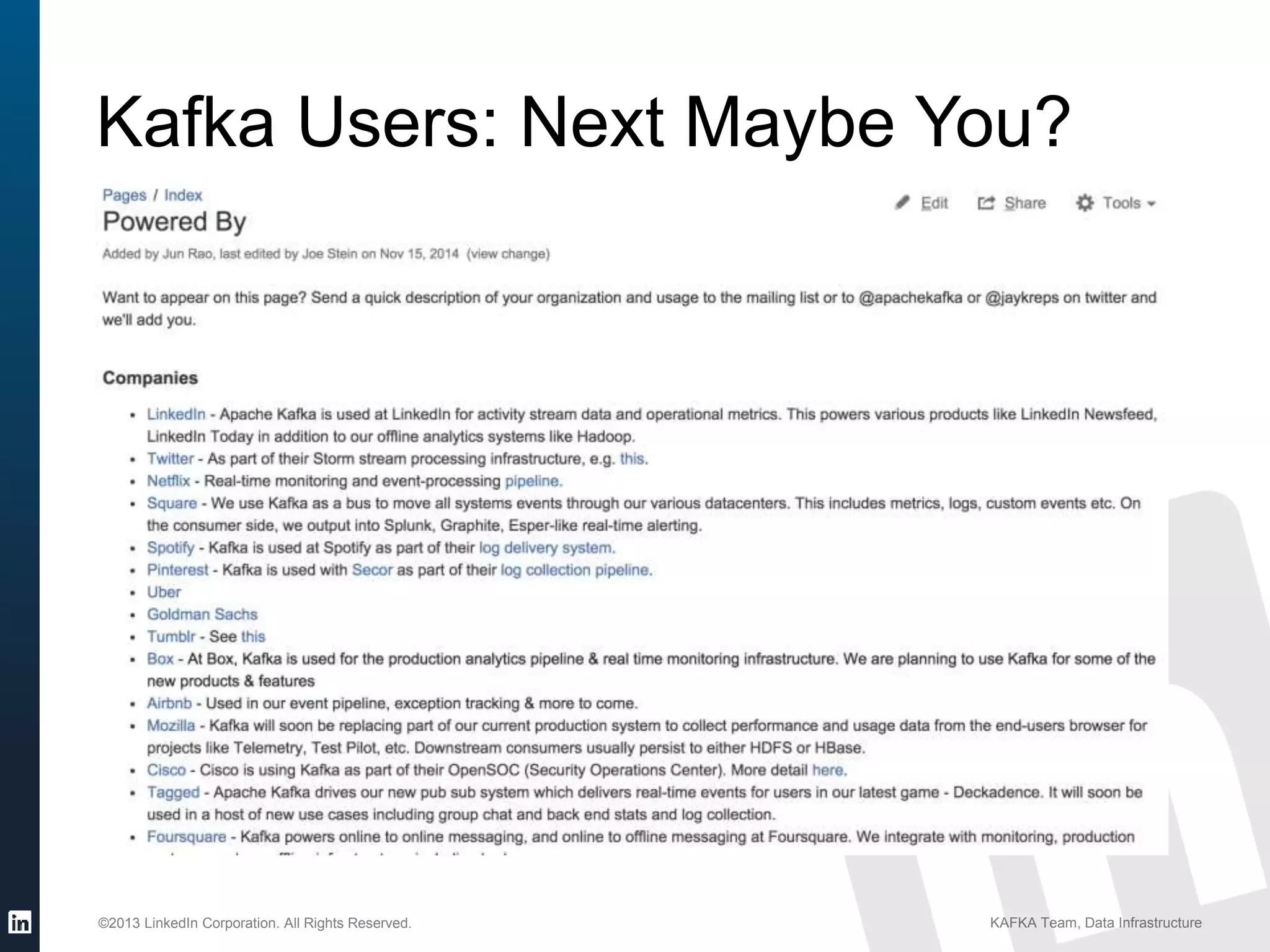
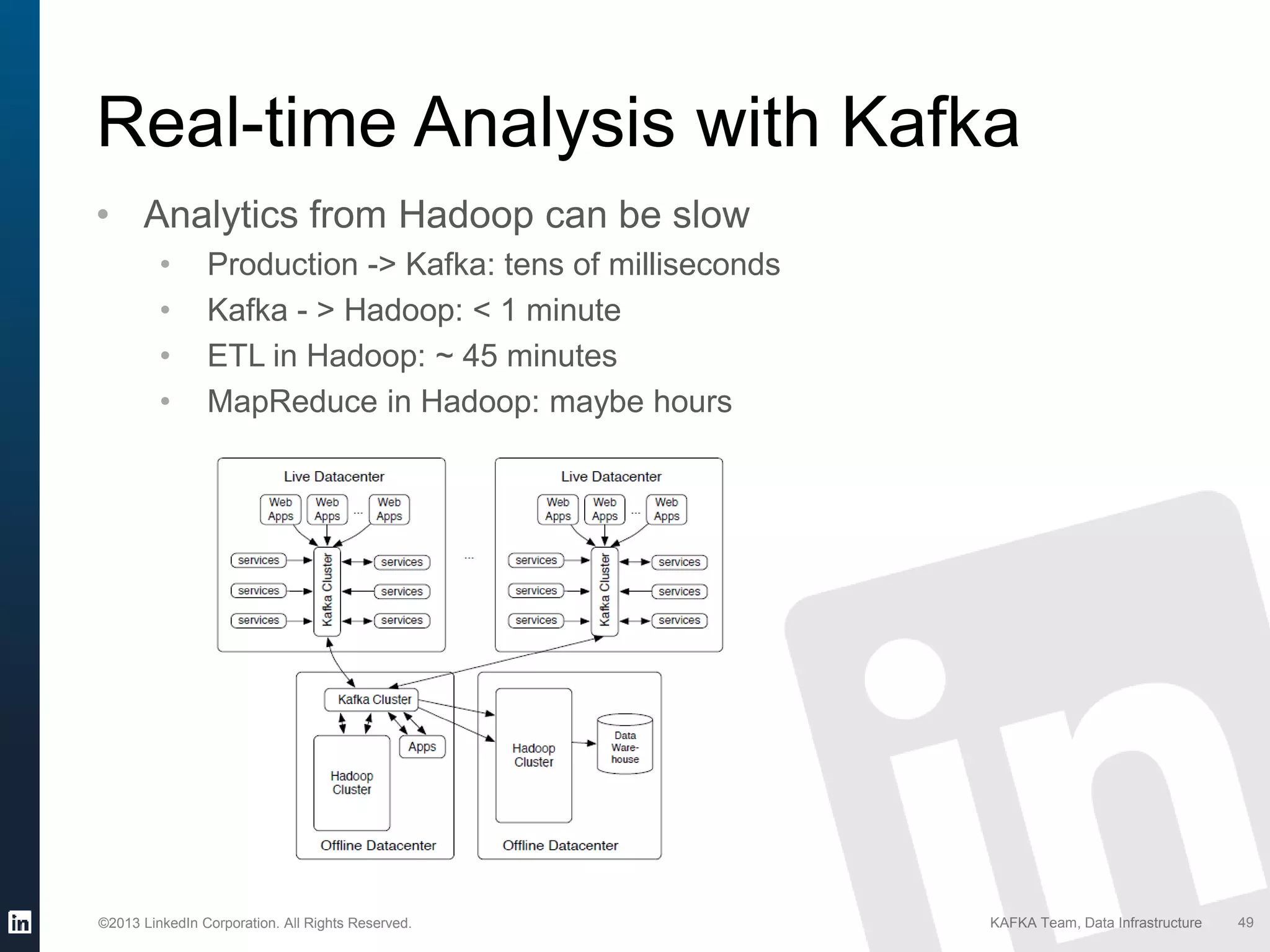
Details on Kafka's extensive usage at LinkedIn, highlighting volume of brokers, topics, messages per day.
Addressing challenges in message types and schema evolution with a standardized schema and ETL processes.
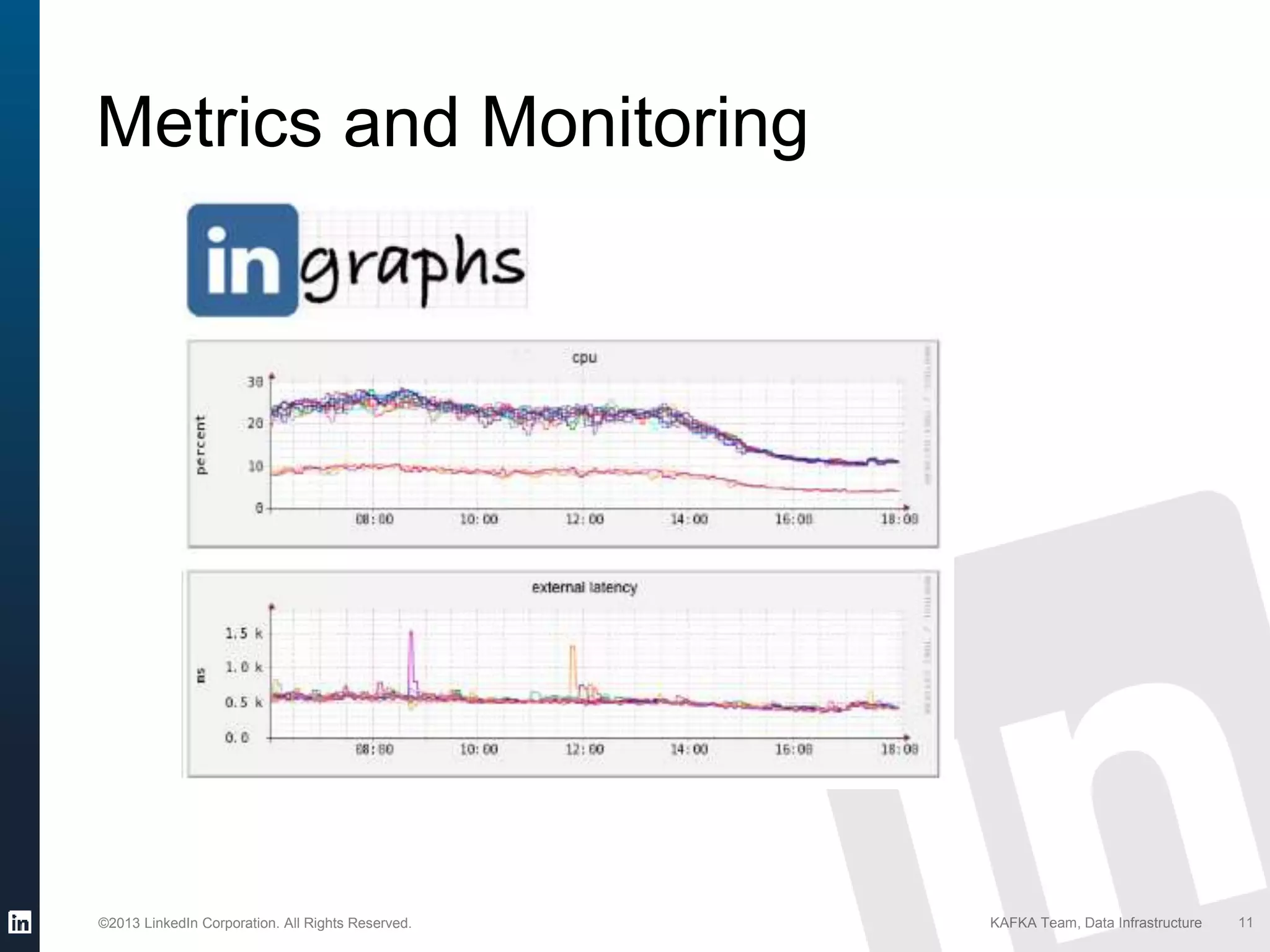
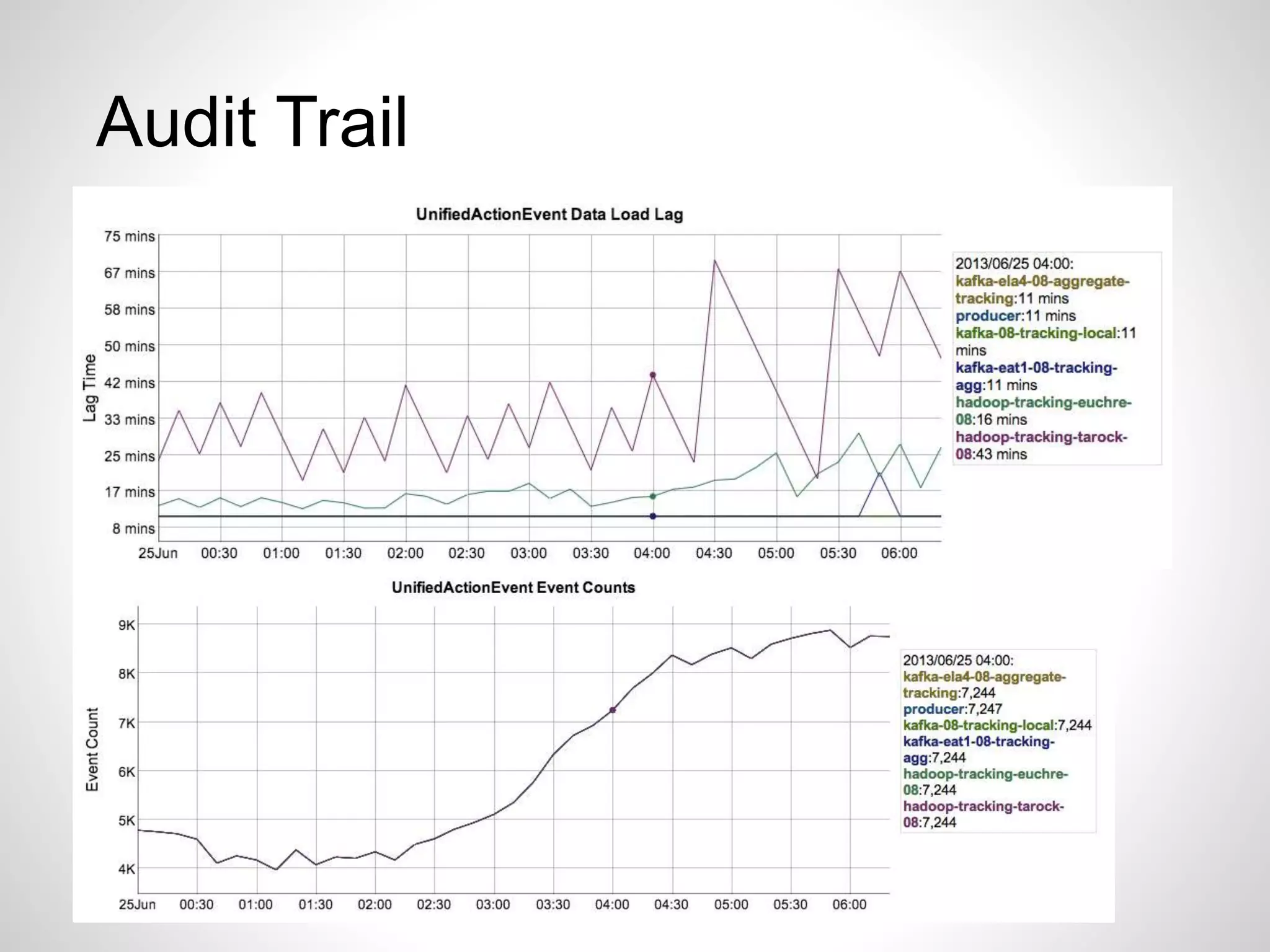
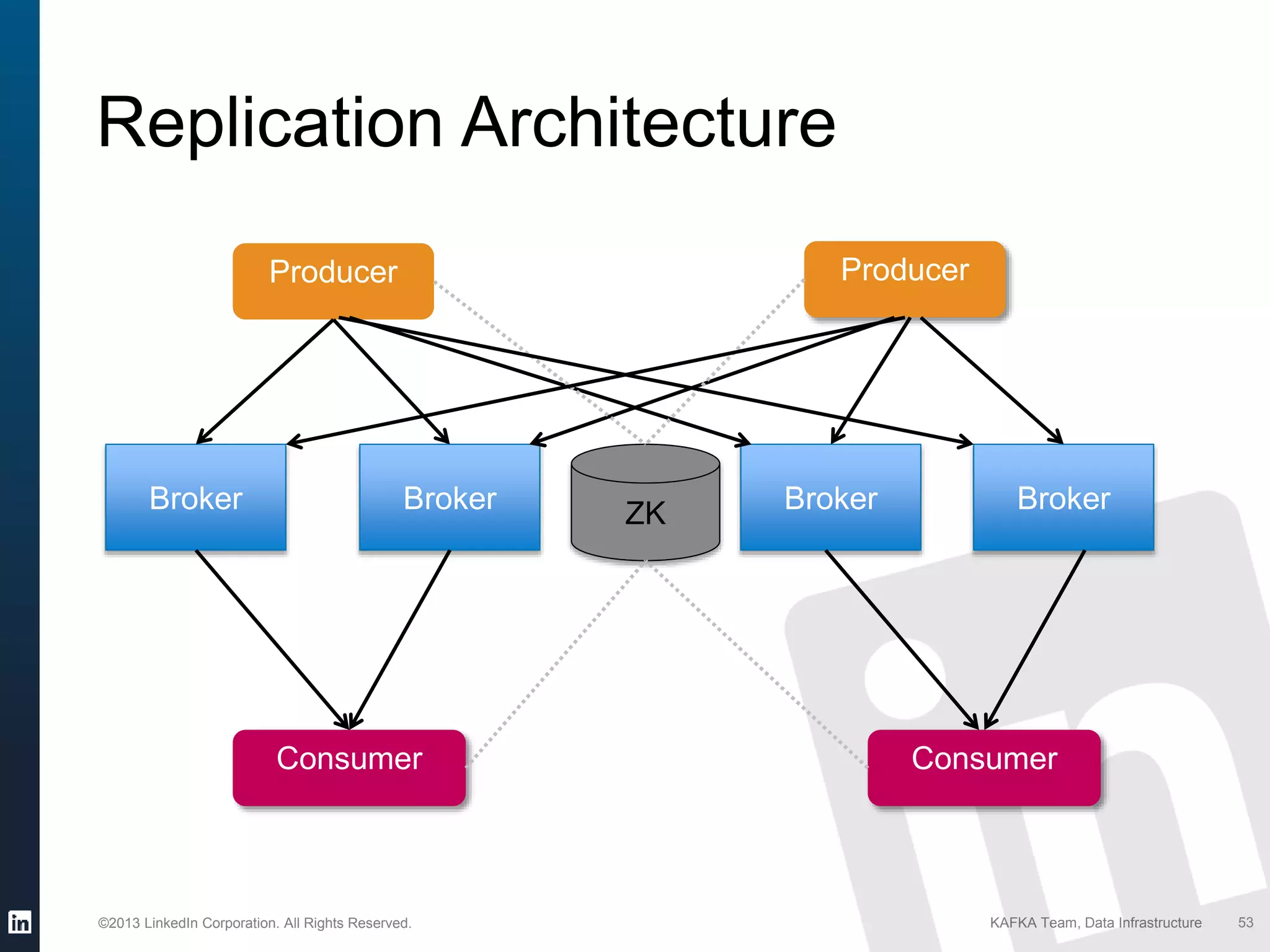
Details on Kafka's reliability features like audit trail, intra-cluster replication, and new developments in Kafka 0.9.
Factors affecting Kafka's performance such as network bandwidth and disk space along with replication architecture.
















































































