Downloaded 68 times















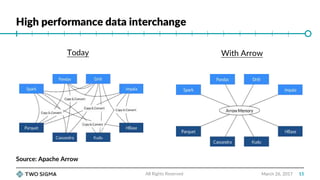








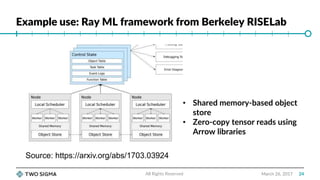




Wes McKinney gave a talk on Apache Arrow, an open source project for memory interoperability between analytics and machine learning systems. Arrow provides efficient columnar memory structures and zero-copy sharing of data between applications. It defines common data types and schemas that can be used across programming languages. Arrow is implemented in C++ and provides language bindings for other languages like Python. It aims to improve performance for tasks like data loading, preprocessing, modeling and serving. Projects like pandas, Spark and Ray are exploring using Arrow internally for more efficient data handling.



















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









