Download as PDF, PPTX







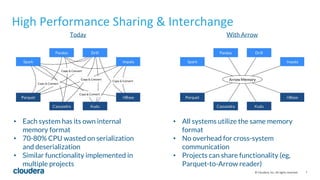
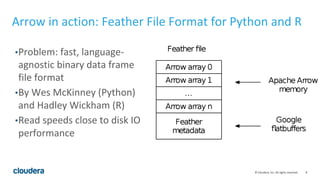

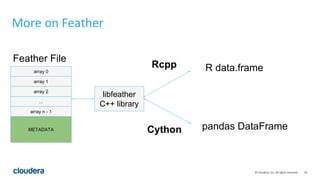





Apache Arrow is a new open source project that aims to establish a common in-memory data representation that can improve interoperability across data science programming languages like Python and R. It provides a standardized columnar memory format that can reduce the CPU overhead of serialization and deserialization between systems by 70-80%. The Feather file format leverages Arrow to provide a fast, language-agnostic binary file format for data frames that enables very fast read/write speeds between Python and R. While Feather has benefits, it still requires data conversion between Arrow storage and each language's native data structures; establishing a common in-memory representation at the C/C++ level could further improve sharing of algorithms and libraries.























































































