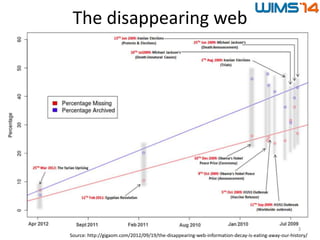
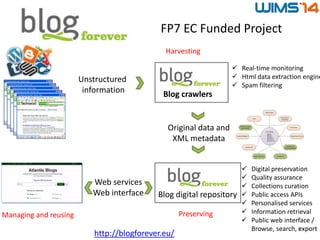
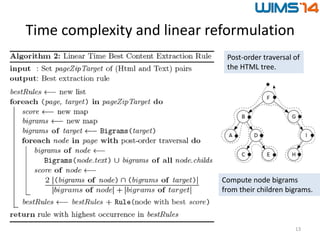
Downloaded 11 times






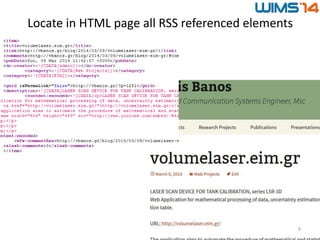


![Example: blog post title best extraction rule
• RSS feed: http://vbanos.gr/en/feed/
• Find RSS blog post title: “volumelaser.eim.gr” in html page:
http://vbanos.gr/blog/2014/03/09/volumelaser-eim-gr-2/
12
XPath HTML Element Value Similarity
Score
/body/div[@id=“page”]/header
/h1
volumelaser.eim.gr 100%
/body/div[@id=“page”]/div[@cla
ss=“entry-code”]/p/a
http://volumelaser.eim.gr/ 80%
/head/title volumelaser.eim.gr | Βαγγέλης Μπάνος 66%
... ... ...
• The Best Extraction Rule for the blog post title is:
/body/div[@id=“page”]/header/h1](https://image.slidesharecdn.com/blogforevercrawlerwims14-2014-06-01-140602090345-phpapp01/85/BlogForever-Crawler-Techniques-and-algorithms-to-harvest-modern-weblogs-Presentation-at-WIMS-14-12-320.jpg)

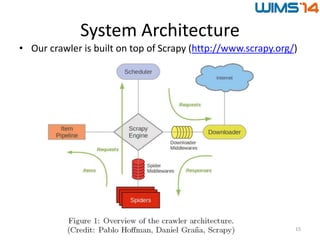







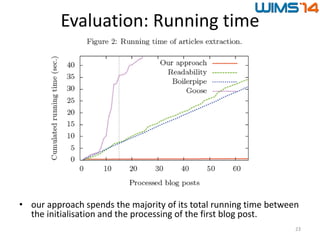



The document discusses the BlogForever crawler, a system designed for extracting and archiving blog content, including articles, authors, and comments, using advanced algorithms. It highlights the challenges of metadata extraction due to low web standards and presents a novel approach that utilizes structured XML feeds and content rendering. Evaluation of the system against existing web extraction tools demonstrates its effectiveness but also notes future work to address issues of web feed quality and structural variations.




















































![[LvDuit//Lab] Crawling the web](https://cdn.slidesharecdn.com/ss_thumbnails/crawlingtheweb-140901103920-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

































