Download as PDF, PPTX






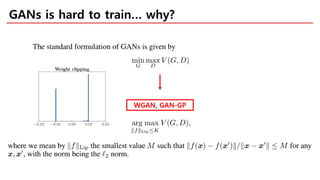
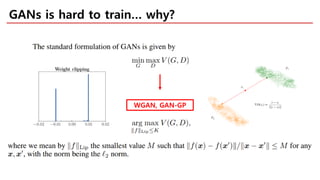
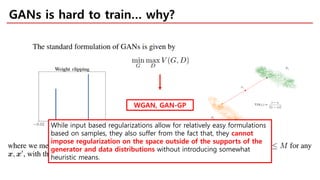








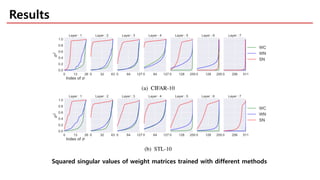
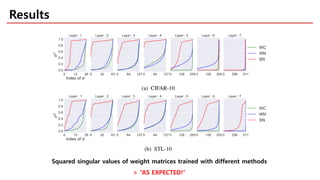
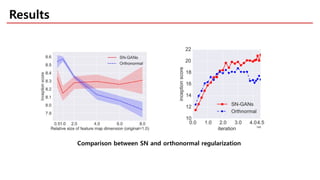
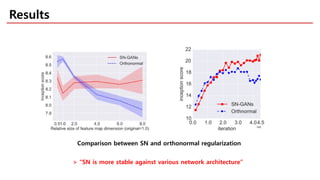




The document discusses spectral normalization, a proposed technique to stabilize the training of the discriminator in generative adversarial networks (GANs). It highlights the simplicity and effectiveness of this method, which only requires tuning a single hyper-parameter, the Lipschitz constant. Comparative results indicate that spectral normalization outperforms other regularization methods in maintaining stability across various network architectures and datasets.
















































![[PR12] Generative Models as Distributions of Functions](https://cdn.slidesharecdn.com/ss_thumbnails/pr12generativemodelsasdistributionsoffunctions-jaejunyoo-210411152822-thumbnail.jpg?width=640&height=640&fit=bounds)
![[CVPR2020] Simple but effective image enhancement techniques](https://cdn.slidesharecdn.com/ss_thumbnails/simplebuteffectiveimageenhancementtechniques-200617034047-thumbnail.jpg?width=640&height=640&fit=bounds)




![[PR12] categorical reparameterization with gumbel softmax](https://cdn.slidesharecdn.com/ss_thumbnails/pr12categoricalreparameterizationwithgumbel-softmax-180304131005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] Capsule Networks - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12capsulenetworks-jaejunyoo-171217144319-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] Inception and Xception - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12inceptionandxception-jaejunyoo-170910140157-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pr12] dann jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12dann-jaejunyoo-170604150015-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] intro. to gans jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12intro-170416162251-thumbnail.jpg?width=640&height=640&fit=bounds)










![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)








