본 문서는 두 개의 도메인 간의 적응을 위한 신경망의 도메인 적대적 훈련(DANN) 알고리즘을 다루고 있으며, 소스 도메인과 타겟 도메인이 서로 다를 때의 분류 문제를 중점적으로 설명한다. DANN은 도메인 독립적 특성을 추출하고 일반화 보장을 기반으로 하는 효과적인 표현 학습 방법을 제안하며, 모델의 오류를 최소화하는 데 필요한 다양한 이론적 결과를 제시한다.
Domain Adversarial Trainingof
Neural Network
PR12와 함께 이해하는
* Domain Adversarial Training of Neural Network, Y. Ganin et al. 2016를 바탕으로 작성한 리뷰
Jaejun Yoo
Ph.D. Candidate @KAIST
PR12
4TH MAY, 2017
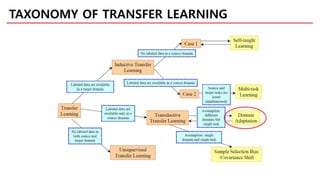
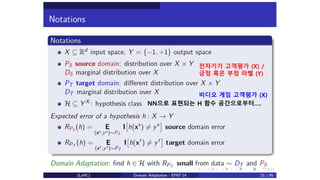
전자기기 고객평가 (X)/
긍정 혹은 부정 라벨 (Y)
비디오 게임 고객평가 (X)
NN으로 표현되는 H 함수 공간으로부터….
16.
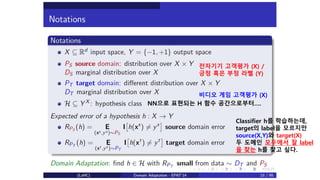
전자기기 고객평가 (X)/
긍정 혹은 부정 라벨 (Y)
비디오 게임 고객평가 (X)
Classifier h를 학습하는데,
target의 label을 모르지만
source(X,Y)와 target(X)
두 도메인 모두에서 잘 label
을 찾는 h를 찾고 싶다.
NN으로 표현되는 H 함수 공간으로부터….
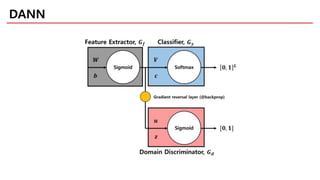
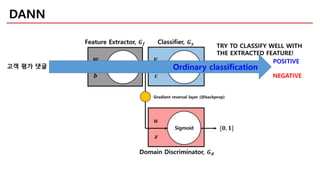
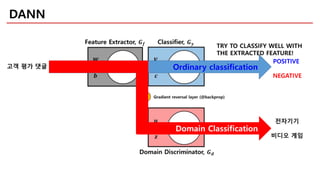
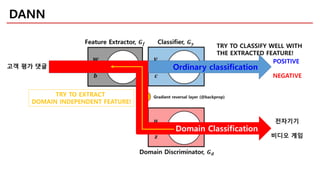
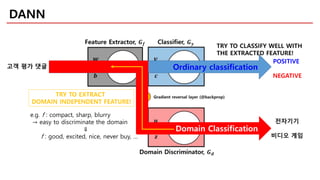
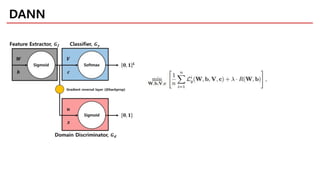
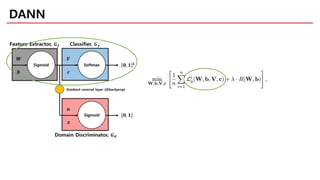
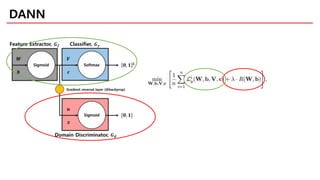
DANN
Ordinary classification
Domain Classification
전자기기
비디오게임
TRY TO CLASSIFY WELL WITH
THE EXTRACTED FEATURE!
POSITIVE
NEGATIVE
고객 평가 댓글
TRY TO EXTRACT
DOMAIN INDEPENDENT FEATURE!
e.g. f : compact, sharp, blurry
→ easy to discriminate the domain
⇓
f : good, excited, nice, never buy, …
22.
• Combining DAand feature learning within one training process
• Principled way to learn a good representation based on the
generalization guarantee
: minimize the H divergence directly (no heuristic)
“When or when not the DA algorithm works.”
“Why it works.”
DANN
23.
기존 전략: 최대한적은 parameter로 training
error가 최소인 model을 찾자
24.
이제는 training domain(source)과 testing
domain (target)이 서로 다르다
기존의 전략 외에 다른 전략이 추가로 필요하다.
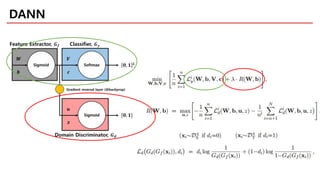
A Bound onthe Adaptation Error
1. Difference across all measurable subsets cannot be estimated from
finite samples
2. We’re only interested in differences related to classification error
29.
Idea: Measure subsetswhere hypotheses in disagree
Subsets A are error sets of one hypothesis wrt another
1. Always lower than L1
2. computable from finite unlabeled samples. (Kifer et al. 2004)
3. train classifier to discriminate between source and target data
30.
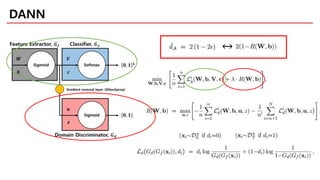
A Computable AdaptationBound
Divergence estimation
complexity
Dependent on number
of unlabeled samples
31.
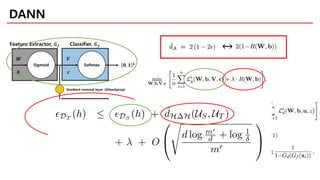
The optimal jointhypothesis
is the hypothesis with minimal combined error
is that error
REFERENCE
PAPERS
1. A surveyon transfer learning, SJ Pan 2009
2. A theory of learning from different domains, S Ben-David et al. 2010
3. Domain-Adversarial Training of Neural Networks, Y Ganin 2016
BLOG
1. http://jaejunyoo.blogspot.com/2017/01/domain-adversarial-training-of-neural.html
2. https://github.com/jaejun-yoo/tf-dann-py35
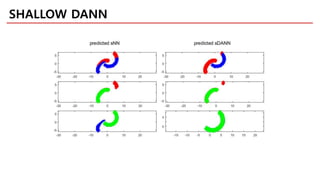
3. https://github.com/jaejun-yoo/shallow-DANN-two-moon-dataset
SLIDES
1. http://www.di.ens.fr/~germain/talks/nips2014_dann_slides.pdf
2. http://john.blitzer.com/talks/icmltutorial_2010.pdf (DA theory part)
3. https://epat2014.sciencesconf.org/conference/epat2014/pages/slides_DA_epat_17.pdf (DA theory part)
4. https://www.slideshare.net/butest/ppt-3860159 (DA theory part)
VIDEO
1. https://www.youtube.com/watch?v=h8tXDbywcdQ (Terry Um 딥러닝 토크)
2. https://www.youtube.com/watch?v=F2OJ0fAK46Q (DA theory part)
3. https://www.youtube.com/watch?v=uc6K6tRHMAA&index=13&list=WL&t=2570s (DA theory part)

































![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)




![[기초개념] Graph Convolutional Network (GCN)](https://cdn.slidesharecdn.com/ss_thumbnails/agistdkimgcn190507-190507153736-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]A closer look at few shot classification](https://cdn.slidesharecdn.com/ss_thumbnails/acloserlookatfew-shotclassification-190304034759-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AAAI21] Self-Domain Adaptation for Face Anti-Spoofing](https://cdn.slidesharecdn.com/ss_thumbnails/aaai21self-domainadaptationforfaceanti-spoofing-230404070154-76c48848-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2A4]DeepLearningAtNAVER](https://cdn.slidesharecdn.com/ss_thumbnails/2a4deeplearningatnaver-140929210707-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[PR12] Inception and Xception - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12inceptionandxception-jaejunyoo-170910140157-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)



![[PR12] Capsule Networks - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12capsulenetworks-jaejunyoo-171217144319-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] categorical reparameterization with gumbel softmax](https://cdn.slidesharecdn.com/ss_thumbnails/pr12categoricalreparameterizationwithgumbel-softmax-180304131005-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] Spectral Normalization for Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/pr12spectralnormalizationforgans-180513142600-thumbnail.jpg?width=640&height=640&fit=bounds)

![[CVPR2020] Simple but effective image enhancement techniques](https://cdn.slidesharecdn.com/ss_thumbnails/simplebuteffectiveimageenhancementtechniques-200617034047-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] Generative Models as Distributions of Functions](https://cdn.slidesharecdn.com/ss_thumbnails/pr12generativemodelsasdistributionsoffunctions-jaejunyoo-210411152822-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] intro. to gans jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12intro-170416162251-thumbnail.jpg?width=640&height=640&fit=bounds)



















