More Related Content

PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning 
PPTX
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem ![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF

PDF

PPTX
Tensor コアを使った PyTorch の高速化 
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models 
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools 
PDF
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait... What's hot

PPTX
【DL輪読会】DayDreamer: World Models for Physical Robot Learning 
PDF

PDF
Teslaにおけるコンピュータビジョン技術の調査 (2) 
PDF
![[DL輪読会]Energy-based generative adversarial networks](https://cdn.slidesharecdn.com/ss_thumbnails/energy-basedgenerativeadversarialnetworks-171030102253-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Energy-based generative adversarial networks 
PDF

PDF

PPTX

PDF

PPTX
【DL輪読会】Transformers are Sample Efficient World Models 
PDF
【DL輪読会】Foundation Models for Decision Making: Problems, Methods, and Opportun... 
PDF
cvpaper.challenge 研究効率化 Tips ![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision ![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant... 
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial) 
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ 
PDF
MediaPipeを使ったARアプリ開発事例 ~カメラをかざして家䛾中で売れるも䛾を探そう~ 
PDF
クラシックな機械学習入門:付録:よく使う線形代数の公式 
PDF

PDF
第1回 配信講義 計算科学技術特論A (2021) Similar to Maxout networks

PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~ 
PPTX
【輪読会】Braxlines: Fast and Interactive Toolkit for RL-driven Behavior Engineeri... 
PDF

PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2 
PPTX
Deep learning basics described 
PDF

PPTX

PDF

PDF
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PDF
Chapter 02 #ml-professional 
PDF
NN, CNN, and Image Analysis 
PDF
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計 
PDF

PDF
Practical recommendations for gradient-based training of deep architectures 
PPTX
MIRU2014 tutorial deeplearning 
PPTX

PDF
2014/5/29 東大相澤山崎研勉強会:パターン認識とニューラルネットワーク,Deep Learningまで 
PPTX

PDF
More from Junya Saito

PDF
Large-Scale Bandit Problems and KWIK Learning 
PDF

PDF
Improving neural networks by preventing co adaptation of feature detectors 
PDF
Acoustic Modeling using Deep Belief Networks 
PDF
Deep Mixtures of Factor Analysers 
PDF
Bayesian Efficient Multiple Kernel Learning Maxout networks
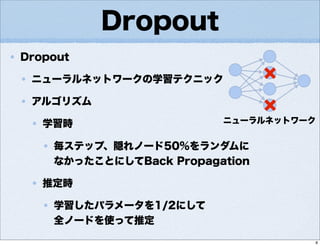
- 1.
Maxout Networks
Ian Goodfellow,David Warde-Farley, Mehdi Mirza, Aaron Courville, Yoshua Bengio
(Universit ́e de Montr ́eal)
ICML 2013
斎藤淳哉
junya[あっと]fugaga.info
論文紹介
1
- 2.
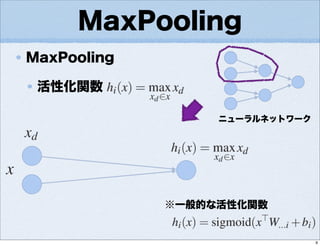
- 3.
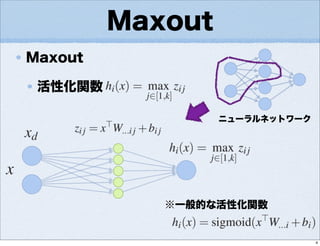
- 4.
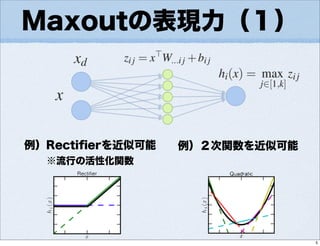
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.

![Maxout Networks
Ian Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, Yoshua Bengio
(Universit ́e de Montr ́eal)
ICML 2013
斎藤淳哉
junya[あっと]fugaga.info
論文紹介
1](https://image.slidesharecdn.com/maxoutnetworks-130709105717-phpapp01/85/Maxout-networks-1-320.jpg)
![Maxout Networks
Ian Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, Yoshua Bengio
(Universit ́e de Montr ́eal)
ICML 2013
斎藤淳哉
junya[あっと]fugaga.info
論文紹介
1](https://image.slidesharecdn.com/maxoutnetworks-130709105717-phpapp01/75/Maxout-networks-1-2048.jpg)


![Maxoutの表現力(2)
定理1(ざっくり)
Maxout は、隠れノード( )が十分にあれば
任意の凸関数を近似可能
補題(ざっくり)
凸関数 と からなる関数 は
任意の関数を近似可能
定理2(ざっくり)
Maxout と からなる関数 は
任意の関数を近似可能
• 2層以上のMaxout
• 1層以上のMaxout+1層以上のSoftmax
→ 任意の関数を近似可能
※値域:[0,1]
6](https://image.slidesharecdn.com/maxoutnetworks-130709105717-phpapp01/85/Maxout-networks-6-320.jpg)