背景
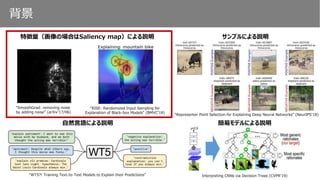
特徴量(画像の場合はSaliency map)による説明 サンプルによる説明
自然言語による説明簡易モデルによる説明
“WT5?! Training Text-to-Text Models to Explain their Predictions”
“Representer Point Selection for Explaining Deep Neural Networks” (NeurIPS'18)
Interpreting CNNs via Decision Trees (CVPR’19)
“RISE: Randomized Input Sampling for
Explanation of Black-box Models” (BMVC’18)
“SmoothGrad: removing noise
by adding noise” (arXiv’17/06)
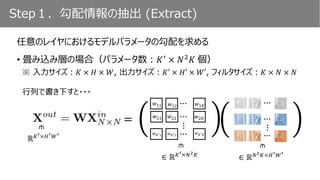
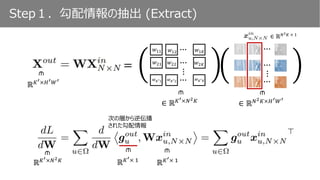
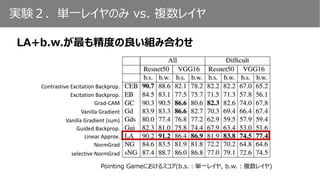
実験2.単一レイヤのみ vs. 複数レイヤ
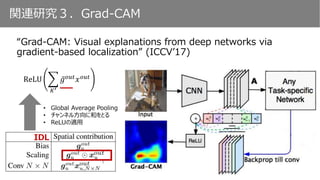
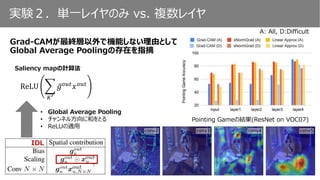
Grad-CAMが最終層以外で機能しない理由として
GlobalAverage Poolingの存在を指摘
A: All, D:Difficult
ReLU
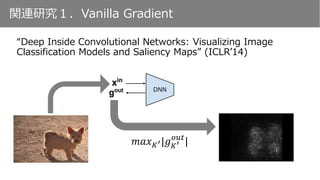
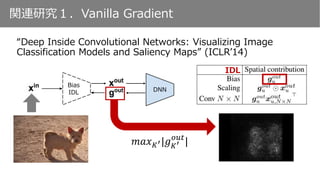
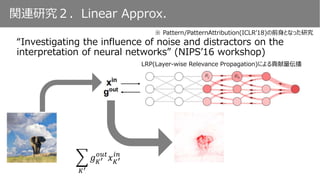
𝐾′
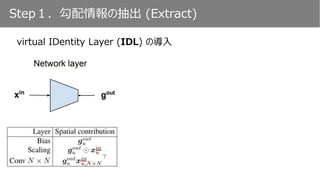
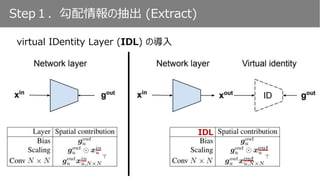
𝑔 𝑜𝑢𝑡
𝑥 𝑜𝑢𝑡
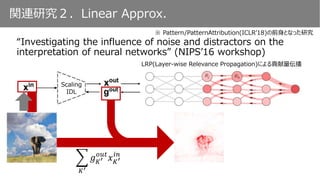
• Global Average Pooling
• チャンネル方向に和をとる
• ReLUの適用
𝑔 𝑢
𝑜𝑢𝑡
⊙ 𝑥 𝑢
𝑖𝑛
Scaling層における勾配
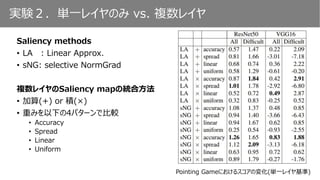
Saliency mapの計算法
IDL
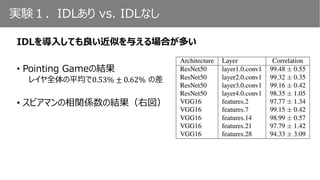
Pointing Gameの結果(ResNet on VOC07)
28.
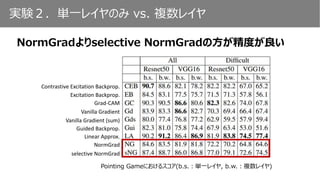
実験2.単一レイヤのみ vs. 複数レイヤ
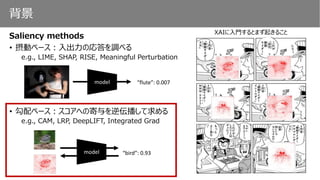
Saliencymethods
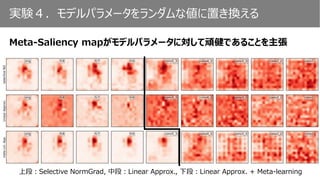
• LA : Linear Approx.
• sNG: selective NormGrad
複数レイヤのSaliency mapの統合方法
• 加算(+) or 積(×)
• 重みを以下の4パターンで比較
• Accuracy
• Spread
• Linear
• Uniform
Pointing Gameにおけるスコアの変化(単一レイヤ基準)
29.
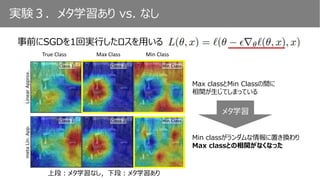
実験3.メタ学習あり vs. なし
事前にSGDを1回実行したロスを用いる
MinClassMax ClassTrue Class
Max classとMin Classの間に
相関が生じてしまっている
上段:メタ学習なし,下段:メタ学習あり
Min classがランダムな情報に置き換わり
Max classとの相関がなくなった
メタ学習






















![[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...](https://cdn.slidesharecdn.com/ss_thumbnails/deeplabv3-180309001425-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/20190125misono-190125024053-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields](https://cdn.slidesharecdn.com/ss_thumbnails/realtimemultipersonposeestimation1-170907054459-thumbnail.jpg?width=640&height=640&fit=bounds)





















![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)
