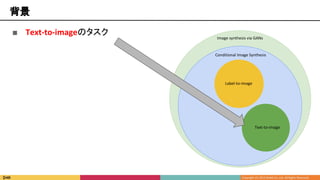
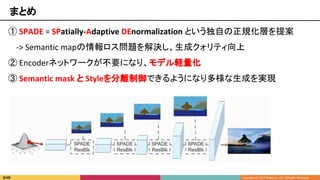
■ Text-to-imageのタスク
■ 文章を入力して画像を生成
Imagesynthesis via GANs
Conditional Image Synthesis
Text-to-image
Label-to-image
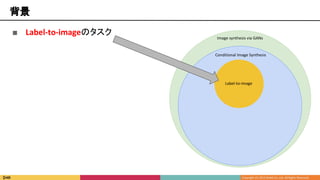
背景
People riding on
elephants that
are walking through
a river.
引用5 [Seunghoon Hong et al., 2018]
■ Discriminatorはpix2pixHDと同じMulti-scale discriminator(PatchGAN準拠)
(Adversarial loss + Feature Matching loss + Perceptual loss)
■ least squared loss -> Hinge lossに変更
■ DiscriminatorにはSPADE層をいれない
実装詳細
引用1 [Taesung Park et al., 2019]
引用7 [Ting-Chun Wang et al, 2017]
64.
■ GeneratorとDiscriminatorの両方にSpectral Normを適用
■Generator LR = 0.0001、Discriminator LR = 0.0004
■ ADAM β1 = 0、β2 = 0.999
■ Dataset
⁃ COCO-Stuff: train 118,000枚、validation 5,000枚、182 classes
⁃ ADE20K:train 20,210枚、validation 2,000枚、150 classes
⁃ Cityscapes dataset:train 3,000枚、validation 500枚
⁃ Flickr Landscapes:train 40,000枚、validation 1,000枚 (DeepLabV2使用)
実装詳細
引用11 [Holger Caesar, et al., 2018]
引用12 [Bolei Zhou, et al., 2016]
引用13 [Marius Cordts, et al., 2017]
■ Base Line:
①Pix2pixHD:SOTAなGANベースアプローチ
ベースライン
引用7 [Ting-Chun Wang et al, 2017]
67.
■ Base Line:
①Pix2pixHD:SOTAなGANベースアプローチ
② CRN:段階的に高解像度Semantic mapを入力するFeedforwardアプローチ
ベースライン
引用14 [Qifeng Chen et al., 2017]
68.
■ Base Line:
①Pix2pixHD:SOTAなGANベースアプローチ
② CRN:段階的に高解像度Semantic mapを入力するFeedforwardアプローチ
③ SIMS:本物画像のDBからセグメント合成するアプローチ
ベースライン
引用15 [Xiaojuan Qi et al., 2018]
参考文献
■ [1] TaesungPark et al. Semantic Image Synthesis with Spatially-Adaptive Normalization, 2019
https://arxiv.org/abs/1903.07291
https://youtu.be/9GR8V-VR4Qg?t=614
■ [2] Tero Karras et al. Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2018
https://arxiv.org/abs/1710.10196
https://youtu.be/XOxxPcy5Gr4
■ [3] Alec Radford et al. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015
https://arxiv.org/abs/1511.06434
■ [4] Takeru Miyato et al. cGANs with Projection Discriminator, 2018
https://arxiv.org/abs/1802.05637
■ [5] Seunghoon Hong et al. Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis, 2018
https://arxiv.org/abs/1801.05091
■ [6] Phillip Isola et al. Image-to-Image Translation with Conditional Adversarial Networks, 2016
https://arxiv.org/abs/1611.07004
■ [7] Ting-Chun Wang et al. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs, 2017
https://arxiv.org/abs/1711.11585
https://youtu.be/3AIpPlzM_qs
80.
参考文献
■ [8] QifengChen, et al. Photographic Image Synthesis with Cascaded Refinement Networks, 2017
https://arxiv.org/abs/1707.09405
■ [9] Xun Huang, et al. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization, 2017
https://arxiv.org/abs/1703.06868
■ [10] Harm de Vries, et al. Modulating early visual processing by language, 2017
https://arxiv.org/abs/1707.00683
■ [11] Holger Caesar, et al. COCO-Stuff: Thing and Stuff Classes in Context, 2018
https://arxiv.org/abs/1612.03716
■ [12] Bolei Zhou, et al. Semantic Understanding of Scenes through the ADE20K Dataset, 2016
https://arxiv.org/abs/1608.05442
■ [13] Marius Cordts, et al. The Cityscapes Dataset for Semantic Urban Scene Understanding, 2016
https://arxiv.org/abs/1604.01685
■ [14] Qifeng Chen, et al. Photographic Image Synthesis with Cascaded Refinement Networks, 2017
https://arxiv.org/abs/1707.09405
■ [15] Xiaojuan Qi, et al. Semi-parametric Image Synthesis, 2018
https://arxiv.org/abs/1804.10992
















![概要
■ CVPR 2019 Oral (https://youtu.be/9GR8V-VR4Qg?t=614)
■ UC Berkeley、NVIDIA、MITらの研究 (2019年3月)
■ pix2pixHD (CVPR 2018) の派生研究
■ Semantic layout + Styleを入力して、photorealな画像を生成する
■ Semantic image synthesisのタスク
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-20-320.jpg)

![背景
■ GANs (Generative Adversarial Networks) による画像生成
■ 何らかの潜在空間からsampleした値をupsampleしてリアルな画像を生成
■ GeneratorとDiscriminatorを戦わせて、真の分布に近づける
■ Discriminatorを騙せるようなリアル画像をGeneratorに生成させる
引用3 [Alec Radford et al., 2015]
引用2 [Tero Karras et al., 2018]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-22-320.jpg)


![背景
■ Conditional image synthesis = 条件付き画像生成
■ 何らか条件を入力して狙った画像を生成
■ 入力条件の種類によってタスク分類
Image synthesis via GANs
Conditional Image Synthesis
引用4 [Takeru Miyato et al., 2018]
[Condition]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-25-320.jpg)
![■ Label-to-imageのタスク
■ Class labelを入力して狙った画像を生成
Image synthesis via GANs
Conditional Image Synthesis
Label-to-image
引用4 [Takeru Miyato et al., 2018]
背景
[Dog]
[Mushroom]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-27-320.jpg)
![■ Text-to-imageのタスク
■ 文章を入力して画像を生成
Image synthesis via GANs
Conditional Image Synthesis
Text-to-image
Label-to-image
背景
People riding on
elephants that
are walking through
a river.
引用5 [Seunghoon Hong et al., 2018]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-29-320.jpg)
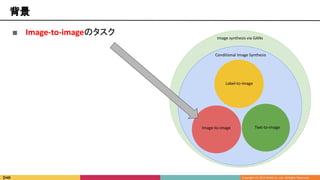
![■ Image-to-imageのタスク
■ 画像を入力して画像を出力
Image synthesis via GANs
Conditional Image Synthesis
Text-to-imageImage-to-image
Label-to-image
背景
引用6 [Phillip Isola et al., 2016]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-31-320.jpg)
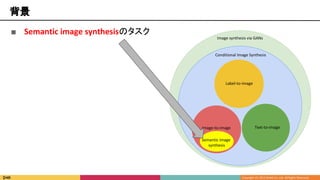
![■ Semantic image synthesisのタスク
■ Senamtic mask(map)を入力して
photorealな画像を生成
Image synthesis via GANs
Conditional Image Synthesis
Text-to-imageImage-to-image
Label-to-image
背景
Semantic image
synthesis
引用6 [Phillip Isola et al., 2016]
限定的だが
実応用上重要](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-33-320.jpg)

![■ Pix2pix (CVPR2017)
■ Conditional GANを使ったシンプルなモデル
■ Senamtic maskそのものをConditionと見なして入力
既存研究
引用6 [Phillip Isola et al., 2016]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-35-320.jpg)
![■ Pix2pixHD (CVPR2018)
■ https://www.slideshare.net/ssuser86aec4/cvpr2018-pix2pixhd-cv-103835371
■ Stacked構造のGenerator + Multi-scale Discriminator
■ 2048 x 1024の高解像度画像を安定して生成可能
既存研究
引用7 [Ting-Chun Wang et al, 2017]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-36-320.jpg)

![既存研究の課題
引用8 [Qifeng Chen, et al., 2017]
[既存手法]
[提案手法]
引用1 [Taesung Park et al., 2019]
引用7 [Ting-Chun Wang et al, 2017]
■ ネットワーク途中でSemantic mapの情報ロス問題
■ 多様なSemantic labelに汎化できず、単調な画像が生成される
Detailまで生成
単調な生成](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-38-320.jpg)
![■ 標準的なDNNは、conv層で畳み込んだ後にnormalization層で正規化
■ 勾配平滑化、過学習防止等のメリットはあるが、
これをSemantic mapに適用すると、情報のロスにつながるケースが発生
既存研究の課題
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-39-320.jpg)
![既存研究の課題
引用1 [Taesung Park et al., 2019]
■ 例:全pixelがgrassのSemantic mapを入力
■ Conv層で畳み込んだ後は一様な値(activation map)になる
(全pixelが1だったり2だったり)](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-40-320.jpg)
![■ この状態で直後にnormalizationを適用すると、全pixel = 平均値なので、
全ての値が0になる (情報が完全に失われる)
既存研究の課題
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-41-320.jpg)
![■ pix2pixHDでは、全pixelが一様なSemantic mapを入力すると、
ラベルの種類に関わらず必ずグレー画像が出力される
SPADE
引用7 [Ting-Chun Wang et al, 2017]
[pix2pixHD]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-42-320.jpg)

![■ 情報のロスを防ぐために、
■ 各normalization層の直後にsemantic mapの情報を埋め込む
SPADE
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-44-320.jpg)
![SPADE
引用1 [Taesung Park et al., 2019]
■ SPADE = SPatially-Adaptive DEnormalization という独自のlayerを定義
■ Semantic label mapの情報を埋め込んだnorm層](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-45-320.jpg)
![SPADE
引用1 [Taesung Park et al., 2019]
■ SPADE = SPatially-Adaptive DEnormalization という独自のlayerを定義
■ Semantic label mapの情報を埋め込んだnorm層
■ 正規化の後で、Semantic mapの情報を使って別空間へアフィン変換
-> 非正規化](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-46-320.jpg)
![■ Semantic mapを一度convでembedding spaceへ射影する
SPADE
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-47-320.jpg)
![■ 更に条件パラメータγとβを出力するようにそれぞれ分岐して畳み込む
■ γとβは空間的な次元を持つテンソル
SPADE
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-48-320.jpg)
![■ NNのメインストリーム側で、Parameter-freeのBatch normを計算しておく
SPADE
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-49-320.jpg)
![■ Batch Norm activationの結果に対して、要素ごとにγをかけてβを足す
■ γ = scaling
■ β = bias
SPADE
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-50-320.jpg)
![SPADE
引用1 [Taesung Park et al., 2019]
■ γとβは学習によって得られるテンソルで、x、y、channelを持つ
= xとyのpixel要素ごとに異なるscalingとbiasのアフィン変換が行われる
■ γとβは正規化されないのでSemantic mapの情報を保存できる](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-51-320.jpg)
![■ 一様なSemantic mapを入力した場合の既存研究との効果比較:
■ pix2pixHDはラベルの種類に関わらず必ずグレー画像が出力される
■ SPADEは綺麗にDetailまで生成される
SPADE
引用1 [Taesung Park et al., 2019]
引用7 [Ting-Chun Wang et al, 2017]
[pix2pixHD] [SPADE]
ネットワーク最後ま
で情報伝搬
ネットワーク
途中で情報ロス](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-52-320.jpg)

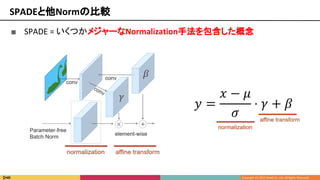
![■ SPADEのSemantic maskを別の画像に、γ と β を空間的不変、
Batch内サンプル数を1にする → AdaINになる
SPADEと他Normの比較
引用9 [Xun Huang et al, 2017]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-55-320.jpg)
![■ SPADEのSemantic mask をラベル情報に置き換え、γ と β を空間的不変
→ Conditional BNになる
SPADEと他Normの比較
引用10 [Harm de Vries et al. 2017]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-56-320.jpg)

![■ SPADEを使えばSemantic mapの情報をネットワーク途中に埋め込める
ので、入力層のSemantic mapが不要
■ pix2pixHDのGeneratorにあったEncoderをなくしてモデル軽量化
モデル設計
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-58-320.jpg)
![■ Generatorの入力部が空いたので、random vectorを入力
■ 同一のSemantic mapでも、sampleする入力値によって
マルチモーダルな生成が可能 -> Styleを制御
モデル設計
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-59-320.jpg)
![■ Semantic map側を編集する事で、Semantic Layoutを自由に変更可能
■ Semantic情報とStyle情報の分離制御を実現
モデル設計
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-60-320.jpg)
![■ random vectorの代わりに、image encoderを取り付けて学習も可能
■ reference画像のstyleを捉えて、狙ったstyleで生成できる
■ (論文ではVAEのreparameterization trickを使用)
モデル設計
引用1 [Taesung Park et al., 2019]
Image
Encoder](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-61-320.jpg)

![■ Discriminatorはpix2pixHDと同じMulti-scale discriminator (PatchGAN準拠)
(Adversarial loss + Feature Matching loss + Perceptual loss)
■ least squared loss -> Hinge lossに変更
■ DiscriminatorにはSPADE層をいれない
実装詳細
引用1 [Taesung Park et al., 2019]
引用7 [Ting-Chun Wang et al, 2017]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-63-320.jpg)
![■ GeneratorとDiscriminatorの両方にSpectral Normを適用
■ Generator LR = 0.0001、Discriminator LR = 0.0004
■ ADAM β1 = 0、β2 = 0.999
■ Dataset
⁃ COCO-Stuff: train 118,000枚、validation 5,000枚、182 classes
⁃ ADE20K:train 20,210枚、validation 2,000枚、150 classes
⁃ Cityscapes dataset:train 3,000枚、validation 500枚
⁃ Flickr Landscapes:train 40,000枚、validation 1,000枚 (DeepLabV2使用)
実装詳細
引用11 [Holger Caesar, et al., 2018]
引用12 [Bolei Zhou, et al., 2016]
引用13 [Marius Cordts, et al., 2017]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-64-320.jpg)

![■ Base Line:
① Pix2pixHD:SOTAなGANベースアプローチ
ベースライン
引用7 [Ting-Chun Wang et al, 2017]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-66-320.jpg)
![■ Base Line:
① Pix2pixHD:SOTAなGANベースアプローチ
② CRN:段階的に高解像度Semantic mapを入力するFeedforwardアプローチ
ベースライン
引用14 [Qifeng Chen et al., 2017]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-67-320.jpg)
![■ Base Line:
① Pix2pixHD:SOTAなGANベースアプローチ
② CRN:段階的に高解像度Semantic mapを入力するFeedforwardアプローチ
③ SIMS:本物画像のDBからセグメント合成するアプローチ
ベースライン
引用15 [Xiaojuan Qi et al., 2018]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-68-320.jpg)
![■ Semantic label-mapの復元度を計測
評価指標
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-69-320.jpg)
![■ Semantic label-mapの復元度を計測
■ 生成画像に対してDeepLabV2とDRN-D-105を使って、Semantic mapを予測
評価指標
引用1 [Taesung Park et al., 2019]
GT Synthesized image
DeepLabV2](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-70-320.jpg)
![■ Semantic label-mapの復元度を計測
■ 生成画像に対してDeepLabV2とDRN-D-105を使って、Semantic mapを予測
■ 正解label-mapとのmean IOU (mIoU)、pixel accuracy (accu) を比較
評価指標
引用1 [Taesung Park et al., 2019]
GT Synthesized image
DeepLabV2
mean IOU
pixel accuracy](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-71-320.jpg)
![■ Semantic label-mapの復元度を計測
■ 生成画像に対してDeepLabV2とDRN-D-105を使って、Semantic mapを予測
■ 正解labe-mapとのmean IOU (mIoU)、pixel accuracy (accu) を比較
■ 更にFrechet Inception Distance (FID) で生成画像とGTの分布間距離も比較
評価指標
引用1 [Taesung Park et al., 2019]
GT Synthesized image
DeepLabV2
mean IOU
pixel accuracy
FID](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-72-320.jpg)
![■ Semantic mapの復元指標 (mIOU、accu) で既存手法を大きく上回る結果
定量評価
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-73-320.jpg)
![■ Semantic mapの復元指標 (mIOU、accu) で既存手法を大きく上回る結果
■ FIDでもほとんど最高値だが、CityscapesでのみSIMSに負ける
⁃ SIMSでは本物画像のパッチをつなぎ合わせて画像合成している
⁃ 必然的に生成分布は本物画像の分布と合致しやすい
⁃ SIMSは欲しいパッチがデータセット内に存在しない場合もあるので
mIOU、accuのスコアは低い
定量評価
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-74-320.jpg)
![■ 人間(Amazon Mechanical Turk)による定性的評価
■ Semantic maskと2種の生成画像を見せて、適切に対応している方を選ぶ
■ 全てのケースにおいて提案手法が最も高確率で選ばれた
定性評価
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-75-320.jpg)

![■ http://34.209.64.66/
■ 絵描けない人でもイメージ通りの画像を生成できる
Webツールデモ
引用1 [Taesung Park et al., 2019]](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-78-320.jpg)
![参考文献
■ [1] Taesung Park et al. Semantic Image Synthesis with Spatially-Adaptive Normalization, 2019
https://arxiv.org/abs/1903.07291
https://youtu.be/9GR8V-VR4Qg?t=614
■ [2] Tero Karras et al. Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2018
https://arxiv.org/abs/1710.10196
https://youtu.be/XOxxPcy5Gr4
■ [3] Alec Radford et al. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015
https://arxiv.org/abs/1511.06434
■ [4] Takeru Miyato et al. cGANs with Projection Discriminator, 2018
https://arxiv.org/abs/1802.05637
■ [5] Seunghoon Hong et al. Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis, 2018
https://arxiv.org/abs/1801.05091
■ [6] Phillip Isola et al. Image-to-Image Translation with Conditional Adversarial Networks, 2016
https://arxiv.org/abs/1611.07004
■ [7] Ting-Chun Wang et al. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs, 2017
https://arxiv.org/abs/1711.11585
https://youtu.be/3AIpPlzM_qs](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-79-320.jpg)
![参考文献
■ [8] Qifeng Chen, et al. Photographic Image Synthesis with Cascaded Refinement Networks, 2017
https://arxiv.org/abs/1707.09405
■ [9] Xun Huang, et al. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization, 2017
https://arxiv.org/abs/1703.06868
■ [10] Harm de Vries, et al. Modulating early visual processing by language, 2017
https://arxiv.org/abs/1707.00683
■ [11] Holger Caesar, et al. COCO-Stuff: Thing and Stuff Classes in Context, 2018
https://arxiv.org/abs/1612.03716
■ [12] Bolei Zhou, et al. Semantic Understanding of Scenes through the ADE20K Dataset, 2016
https://arxiv.org/abs/1608.05442
■ [13] Marius Cordts, et al. The Cityscapes Dataset for Semantic Urban Scene Understanding, 2016
https://arxiv.org/abs/1604.01685
■ [14] Qifeng Chen, et al. Photographic Image Synthesis with Cascaded Refinement Networks, 2017
https://arxiv.org/abs/1707.09405
■ [15] Xiaojuan Qi, et al. Semi-parametric Image Synthesis, 2018
https://arxiv.org/abs/1804.10992](https://image.slidesharecdn.com/kantocv630-190701065632/85/SPADE-Semantic-Image-Synthesis-with-Spatially-Adaptive-Normalization-80-320.jpg)




![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Toward Multimodal Image-to-Image Translation (NIPS'17)](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180514071433-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)


