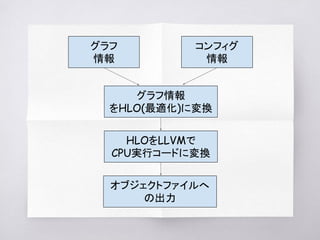
TensorFlow XLAのコード解析をしました。 この資料は、TensorFlow XLAのAOT部分に関するものです。 I analyzed the code of TensorFlow XLA. This document pertains to JIT part of TensorFlow XLA.














![まずは、BUILDファイル
aot/BUILD
cc_binary(
name = "tfcompile",
visibility = ["//visibility:public"],
deps = [":tfcompile_main"],
)
tfcompile_main](https://image.slidesharecdn.com/tensorflowxla-aot-170320015748/85/TensorFlow-XLA-AOT-15-320.jpg)
![tfcompile_main
aot/BUILD
cc_library(
name = "tfcompile_main",
srcs = ["tfcompile_main.cc"],
visibility = ["//visibility:public"],
deps = [
":tfcompile_lib",
":tfcompile_proto",
…..
],
)
tfcompile_main.cc](https://image.slidesharecdn.com/tensorflowxla-aot-170320015748/85/TensorFlow-XLA-AOT-16-320.jpg)

![tfcompile_main.cc
引数の処理
tensorflow::string usage = tensorflow::tfcompile::kUsageHeader;
usage += tensorflow::Flags::Usage(argv[0], flag_list);
bool parsed_flags_ok = tensorflow::Flags::Parse(&argc, argv, flag_list);
tensorflow::port::InitMain(usage.c_str(), &argc, &argv);
tensorflow::tfcompile::Main(flags);
return 0;
}](https://image.slidesharecdn.com/tensorflowxla-aot-170320015748/85/TensorFlow-XLA-AOT-18-320.jpg)