Download as PDF, PPTX



























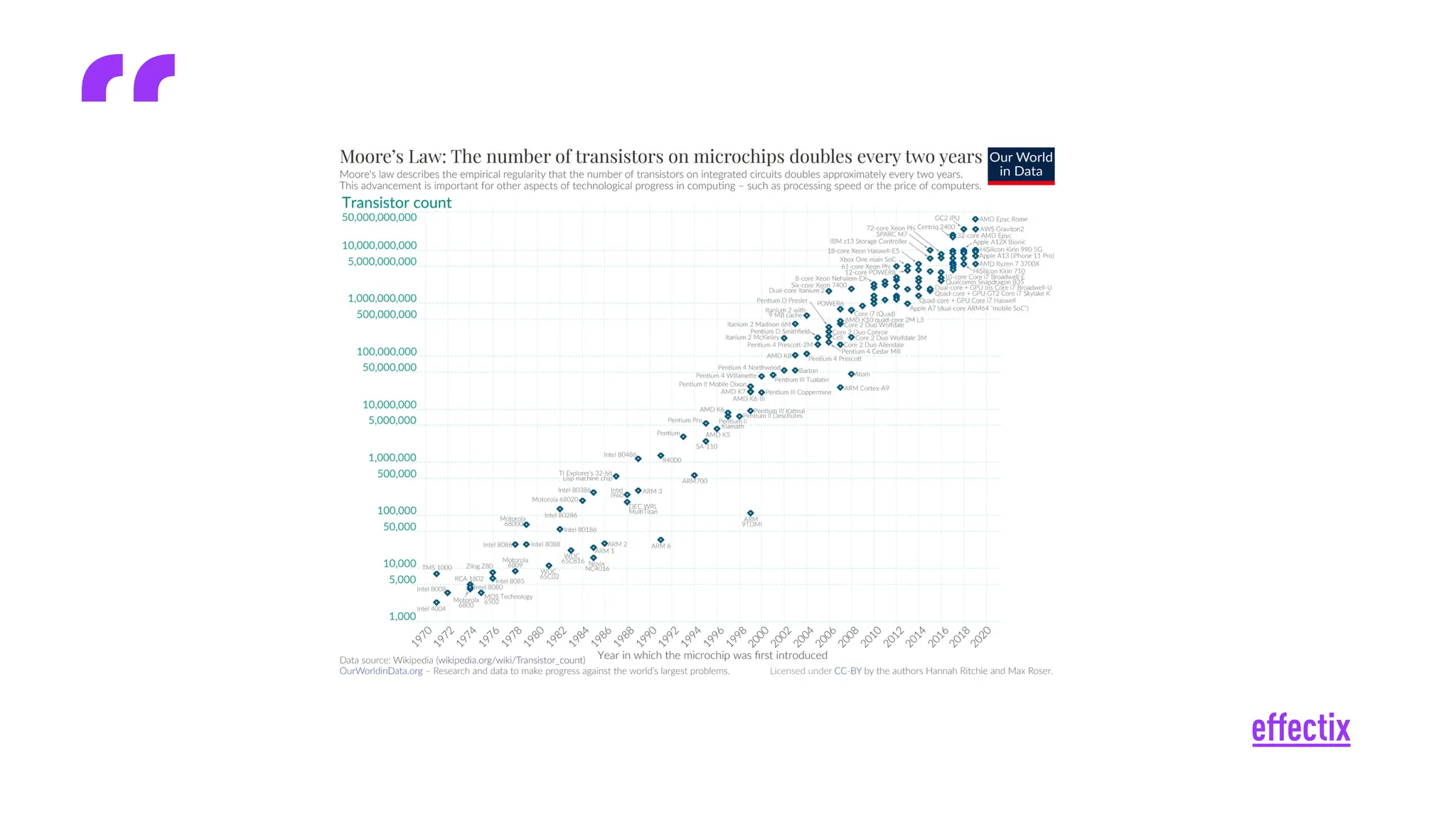


























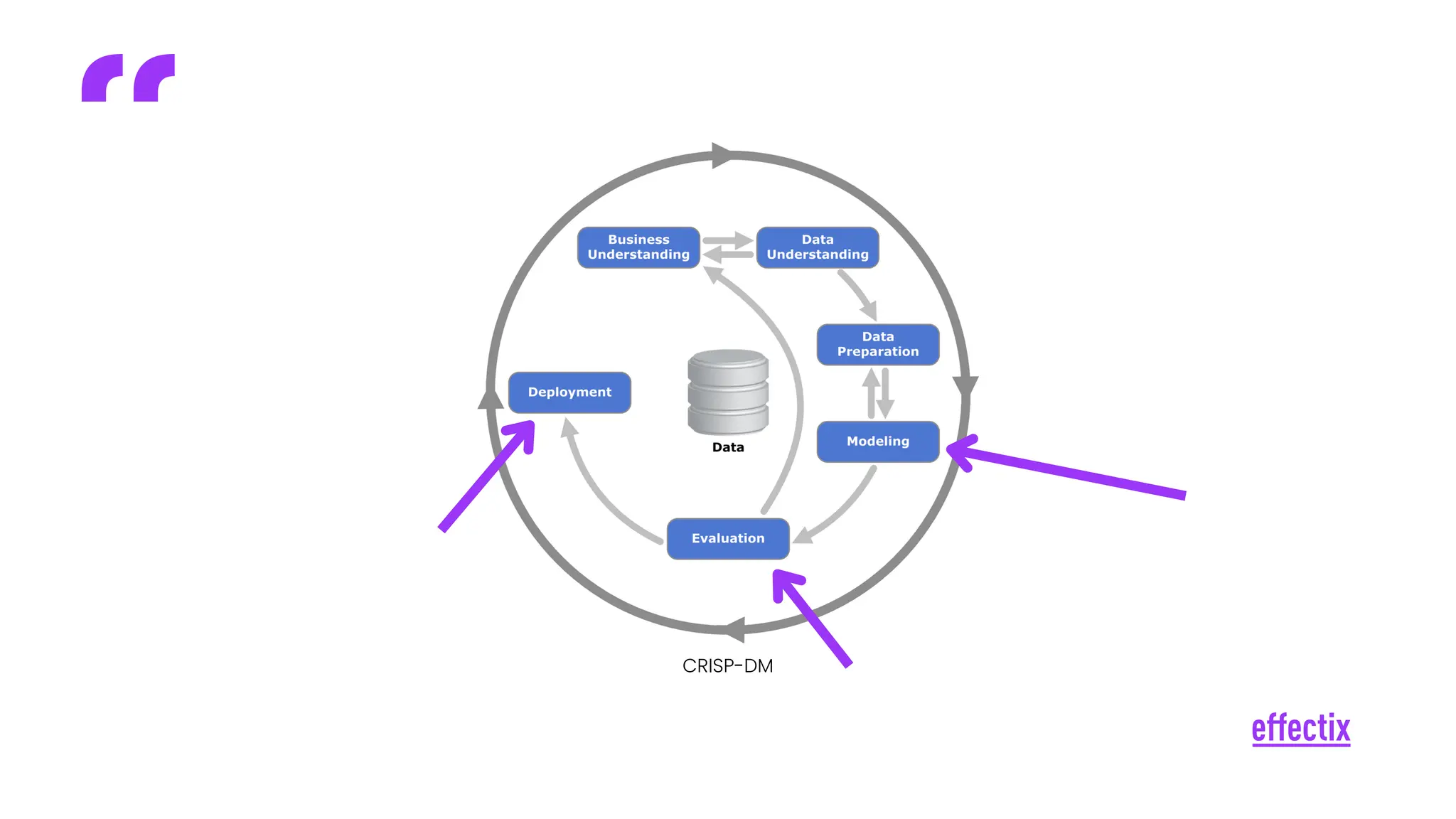



Umělá inteligence ovlivňuje celé odvětví marketingu a mění naše zažitá paradigmata. O to důležitější je tyto změny pochopit a umět je využít. Na konkrétním příkladu automatizace analýzy klíčových slov se vám pokusím osvětlit, jakým způsobem je možné přistupovat k velkým jazykovým modelům a jejich efektivní implementaci do stávajícího workflow s důrazem na lidskou kontrolu. Zaměřím se na to, jak AI účinně zapojit do stávajících procesů a vytěžit z ní maximum.













































![Podnikové aplikace pro řízení vztahů se zákazníky [2009-09-23]](https://cdn.slidesharecdn.com/ss_thumbnails/01seminarcrmv1-0-091123073454-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















