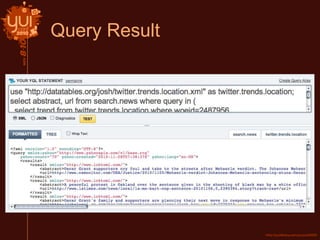
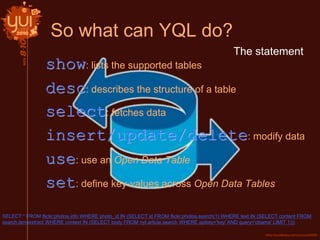
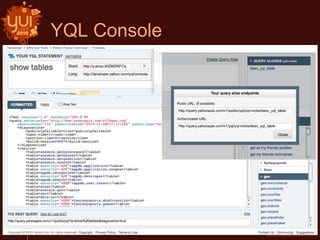
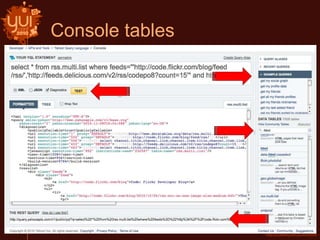
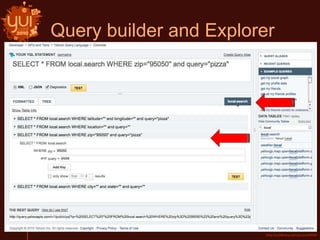
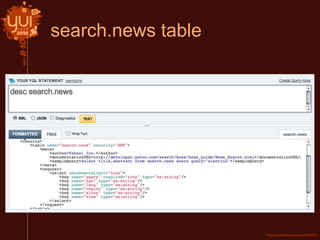
This document introduces Yahoo Query Language (YQL) and provides an overview of its features and capabilities. YQL allows users to query, filter, and join data across web services using an SQL-like language. It provides a single API specification and allows accessing and modifying internet data through a uniform query language. Examples demonstrate how to retrieve twitter trending topics for a location and get related news articles through a single YQL query. The document also discusses open data tables, the YQL console, and how to contribute new tables to the system.






















![Execute Example
<execute><![CDATA[
var resp = request.get().response;
if(resp) {
var trends = resp.trends.trend;
for(var i=trends.length()-1; i>=0; i--) {
var trend = trends[i];
if(trend.charAt(0) == "#") {
delete resp.trends.trend[i];
}
}
}
response.object = resp;
]]></execute>
• Removes all trend topics that start with hashtag (#) using
e4x
• Request and response objects in action](https://image.slidesharecdn.com/yuiconf-nov8-2010-introtoyql-101119152757-phpapp02/85/Yui-conf-nov8-2010-introtoyql-30-320.jpg)