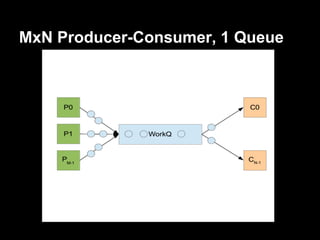
This document discusses using Redis as a work queue for distributing tasks across worker processes. It provides an overview of Redis, describes how to implement a basic work queue using Redis lists, and shows various work queue patterns like synchronous and asynchronous producer-consumer models. It also covers options for scaling out queues and ensuring high availability and reliability. Code examples are provided using the Redis.pm Perl module.


![Redis.pm
● “official” Redis client for Perl
● wrapper around Redis protocol, methods
use Redis;
my $redis = Redis->new(server =>
'192.168.2.3');
$redis->ping;
vagrant@precise64:/vagrant$ telnet 192.168.3.2 6379
Trying 192.168.3.2...
Connected to 192.168.3.2.
Escape character is '^]'.
ping
+PONG
Perl Script
Telnet Session](https://image.slidesharecdn.com/workqueueingw-redis-140603105851-phpapp02/85/Work-WIth-Redis-and-Perl-4-320.jpg)