Downloaded 62 times













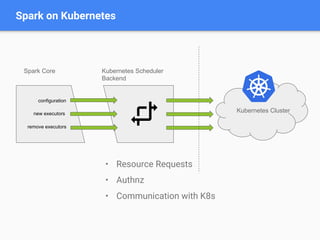

![HDFS on Kubernetes
node A node B
Driver Pod Executor Pod 1 Executor Pod 2
10.0.0.2
196.0.0.5 196.0.0.6
10.0.0.3 10.0.1.2
Namenode Pod Datanode Pod 1 Datanode Pod 2
HDFS on Kubernetes -- Lessons Learned [Public]
Kimoon Kim (PepperData)](https://image.slidesharecdn.com/bigdataandkubernetes1-170612212023/85/Big-data-and-Kubernetes-24-320.jpg)







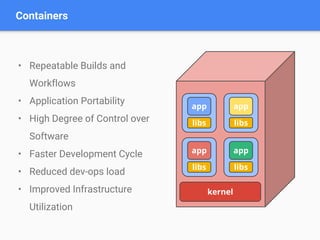
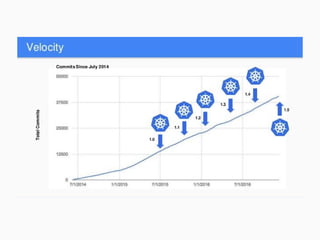
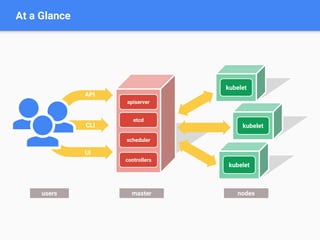
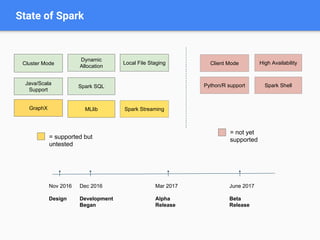
This document discusses Kubernetes, an open-source system for automating the deployment and management of containerized applications, highlighting its components, motivations, and applications such as Apache Spark on Kubernetes. It details the integration of HDFS and various data processing ecosystems, emphasizing resource sharing, operational costs reduction, and community collaboration. Future work includes advancements in batch scheduling, storage solutions, and enhancements to the Kubernetes ecosystem.




























![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)






































