Downloaded 27 times






![The Secret Sauce:
Process Proxies mixed with Kernel Launchers
© 2018 IBM Corporation
Process Proxy:
• Abstracts kernel process represented by Jupyter
framework
• Pluggable class definition identified in kernelspec
(kernel.json)
• Manages kernel lifecycle
Kernel Launcher:
• Embeds target kernel
• Listens on gateway communication port
• Conveys interrupt requests (via local signal)
• Could be extended for additional communications
{
"language": "python",
"display_name": "Spark - Python (Kubernetes Mode)",
"process_proxy": {
"class_name":
"enterprise_gateway.services.processproxies.k8s.KubernetesProcessP
roxy",
"config": {
"image_name": "elyra/kubernetes-kernel-py:dev",
"executor_image_name": "elyra/kubernetes-kernel-py:dev”,
"port_range" : "40000..42000"
}
},
"env": {
"SPARK_HOME": "/opt/spark",
"SPARK_OPTS": "--master k8s://https://${KUBERNETES_SERVICE_HOST
--deploy-mode cluster --name …",
…
},
"argv": [
"/usr/local/share/jupyter/kernels/spark_python_kubernetes/bin/run.
sh",
"{connection_file}",
"--RemoteProcessProxy.response-address",
"{response_address}",
"--RemoteProcessProxy.spark-context-initialization-mode",
"lazy"
]
}](https://image.slidesharecdn.com/codait-jupyterenterprisegatewayoverviewexternal-20180821-180822003530/75/Jupyter-Enterprise-Gateway-Overview-15-2048.jpg)

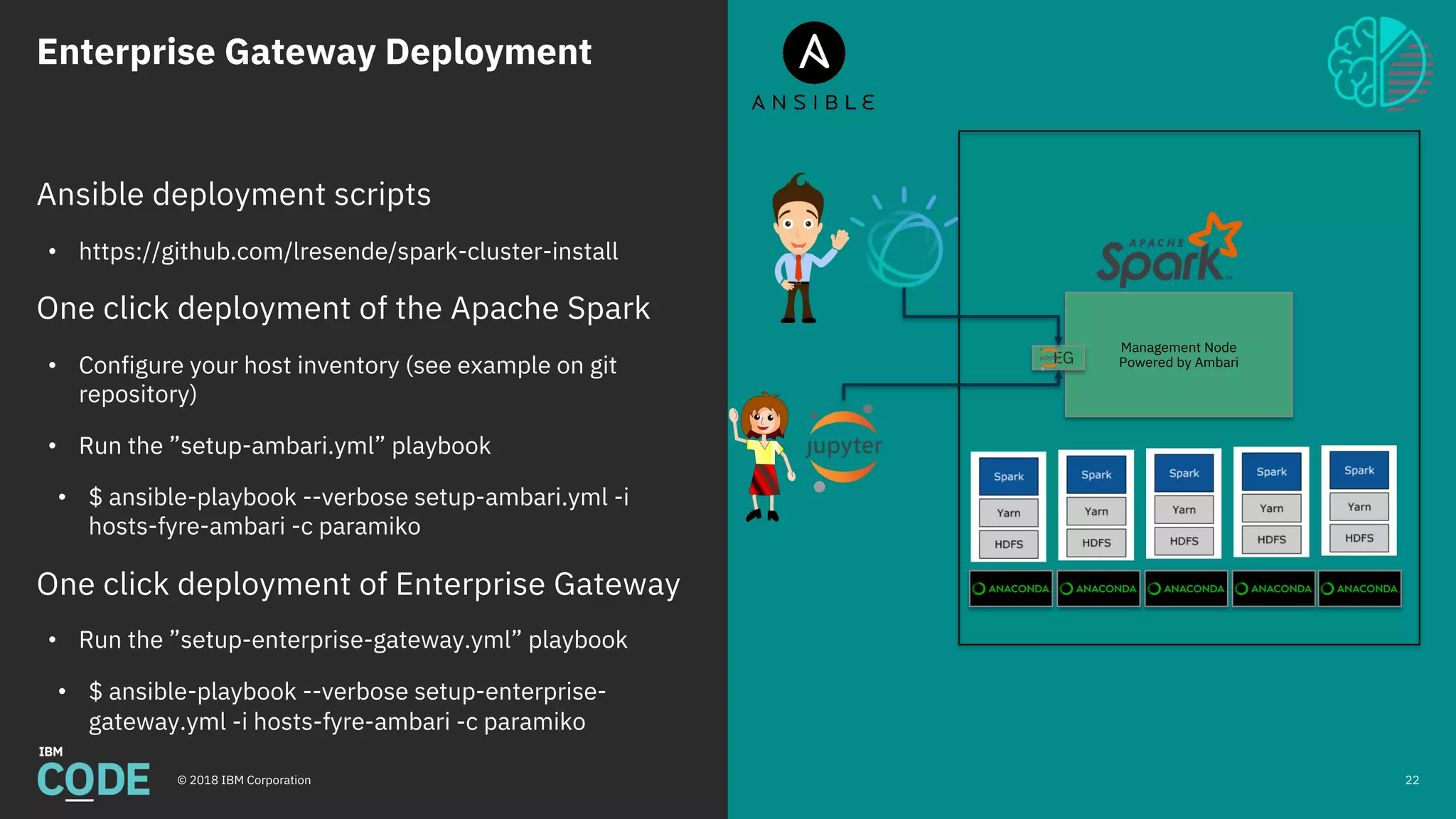
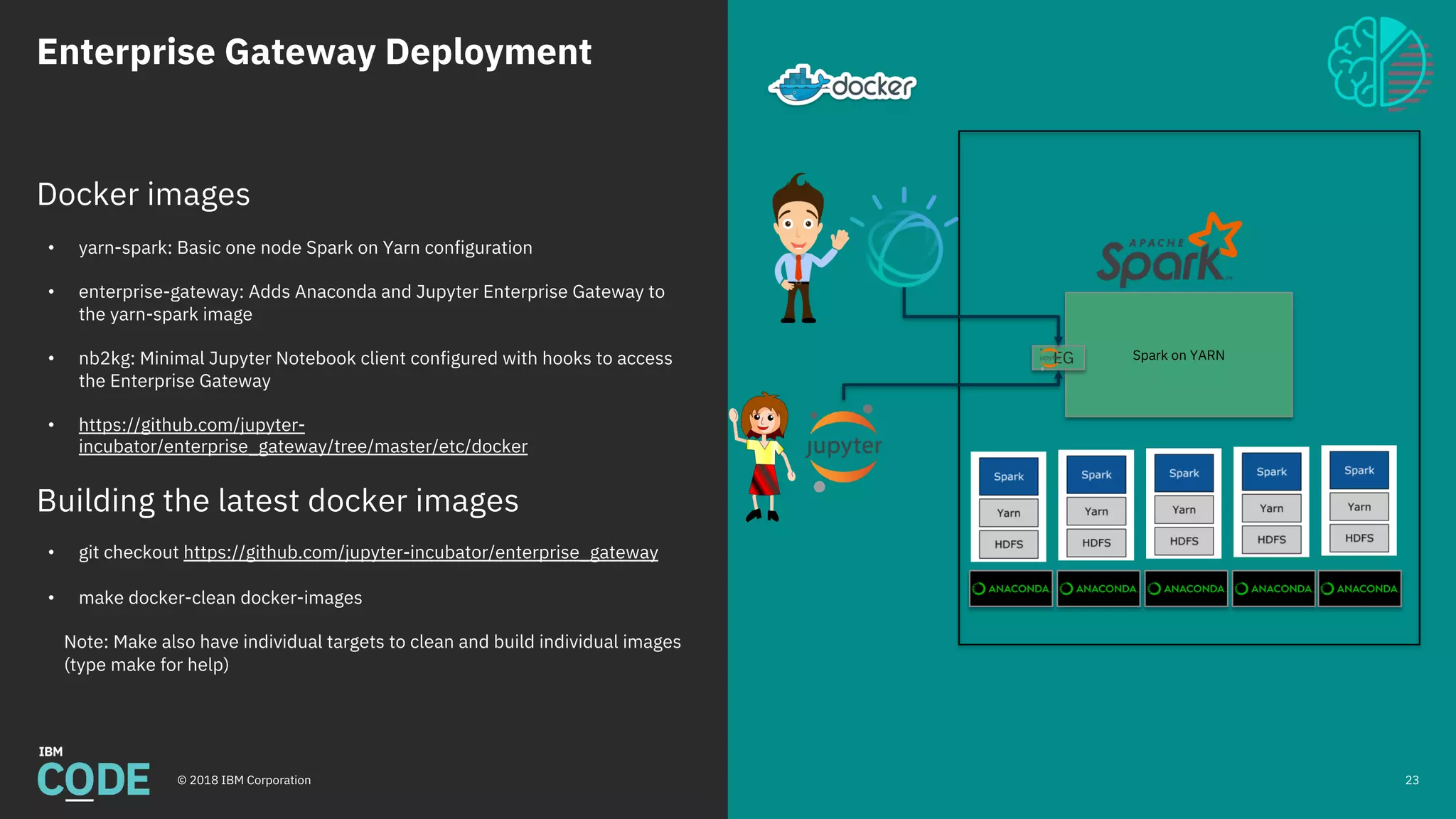
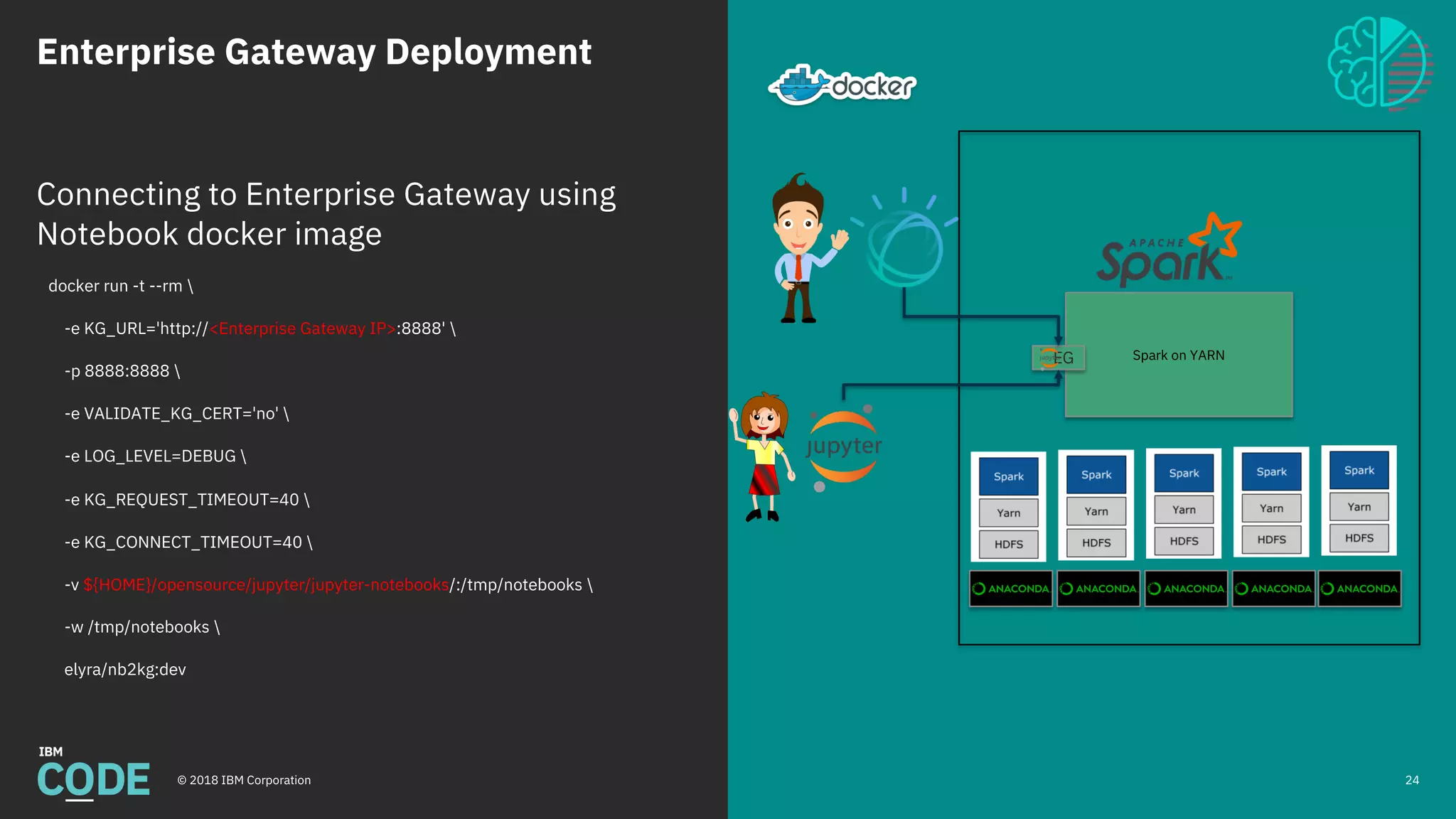

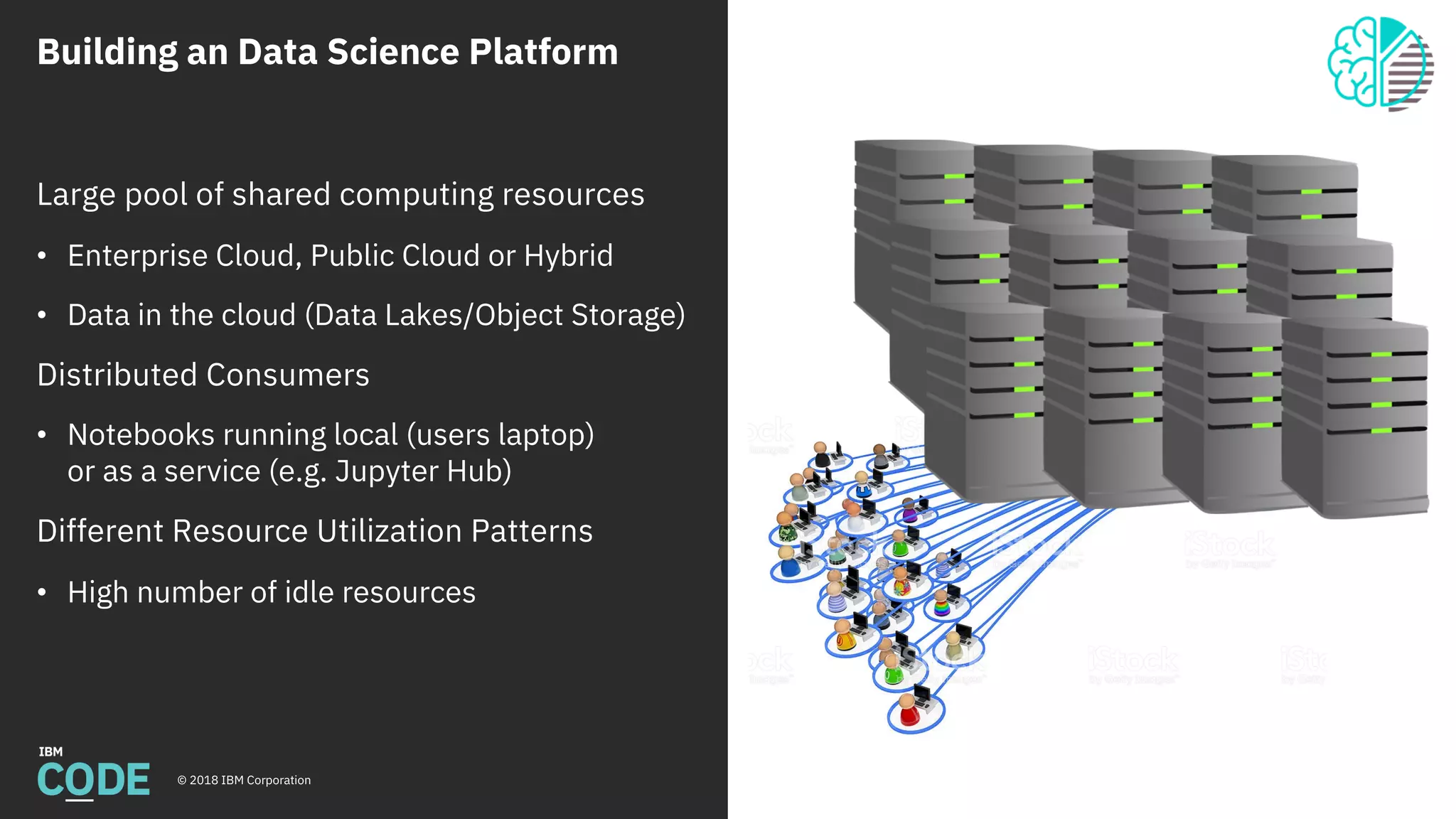
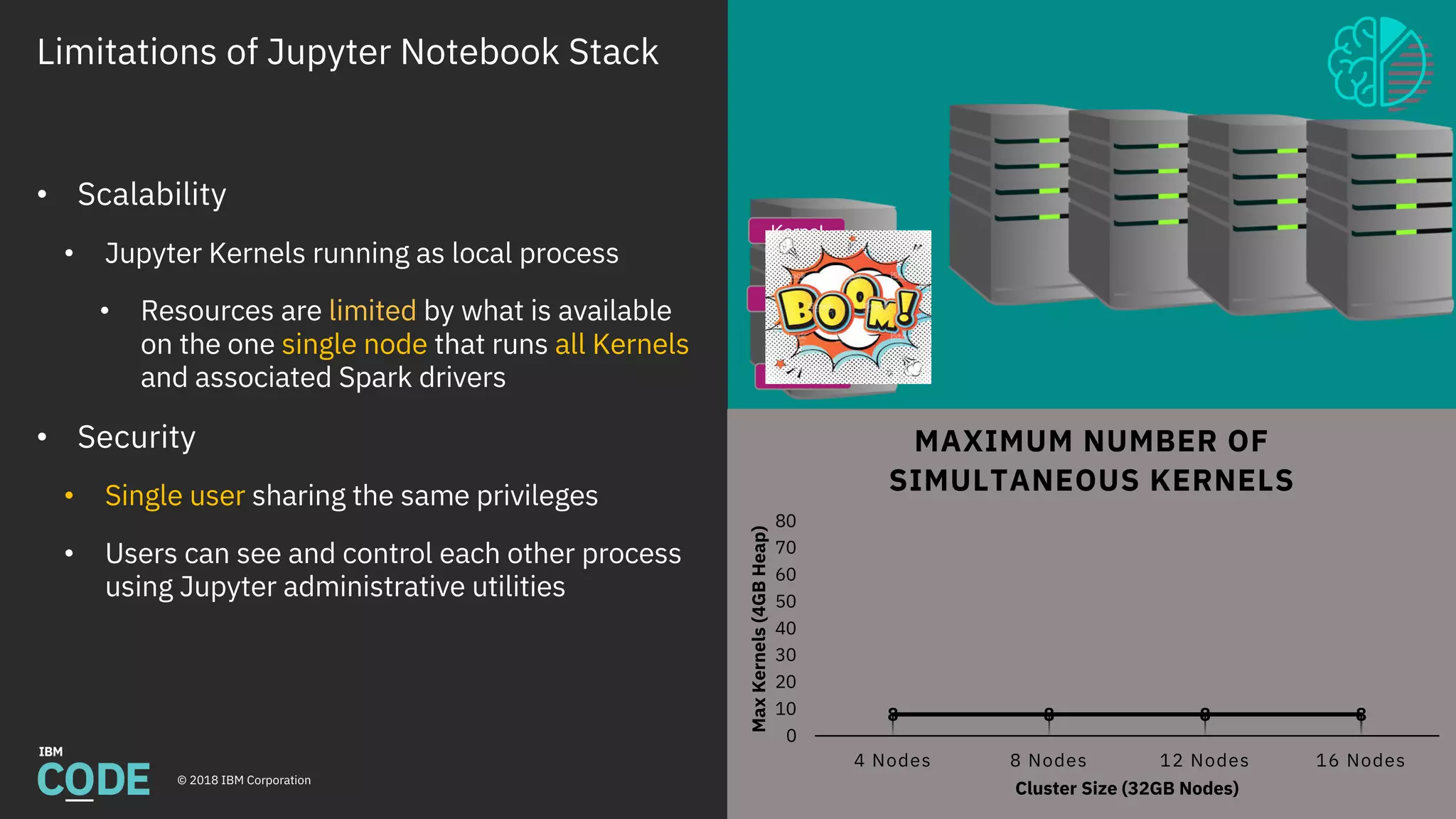
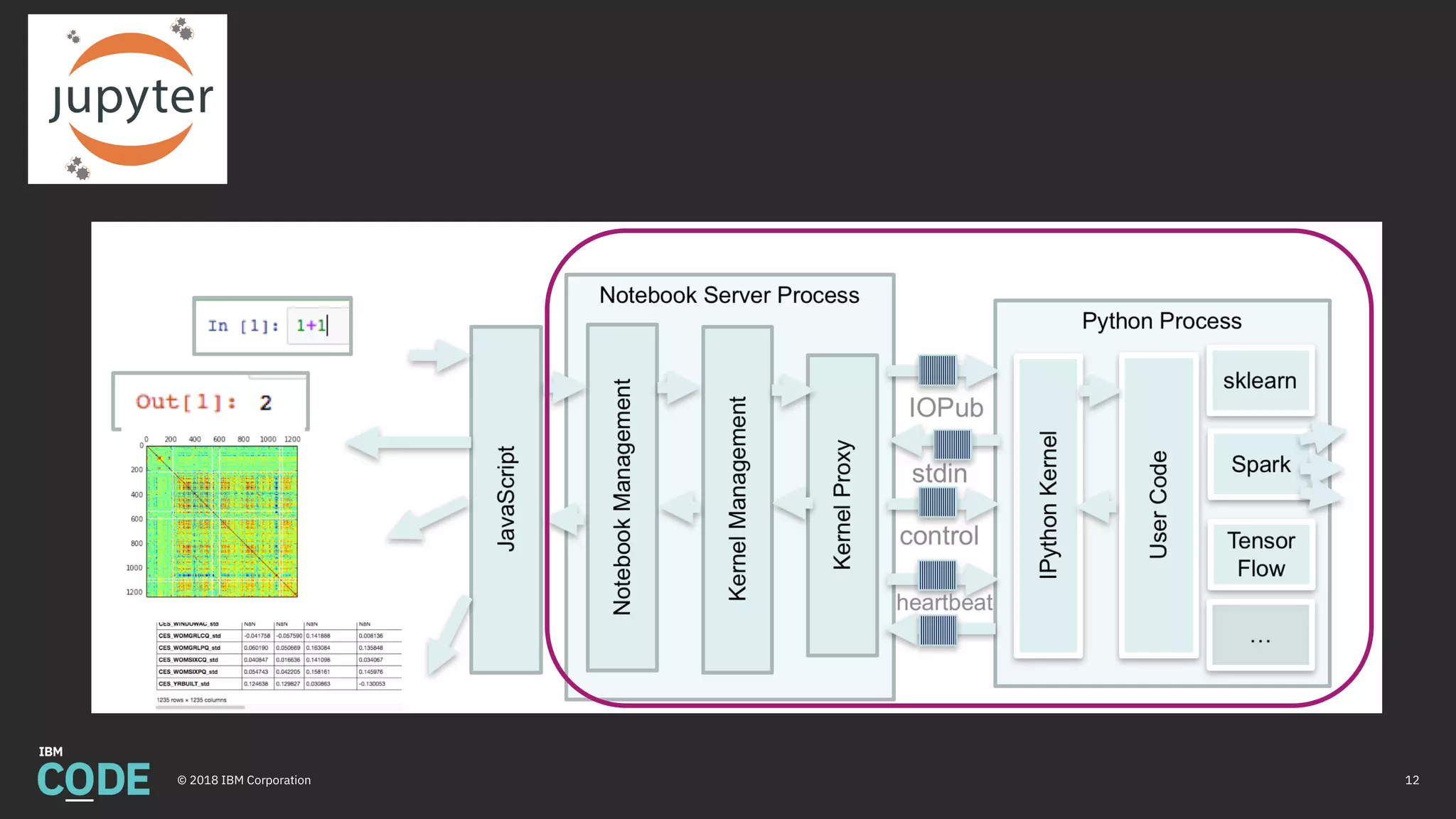
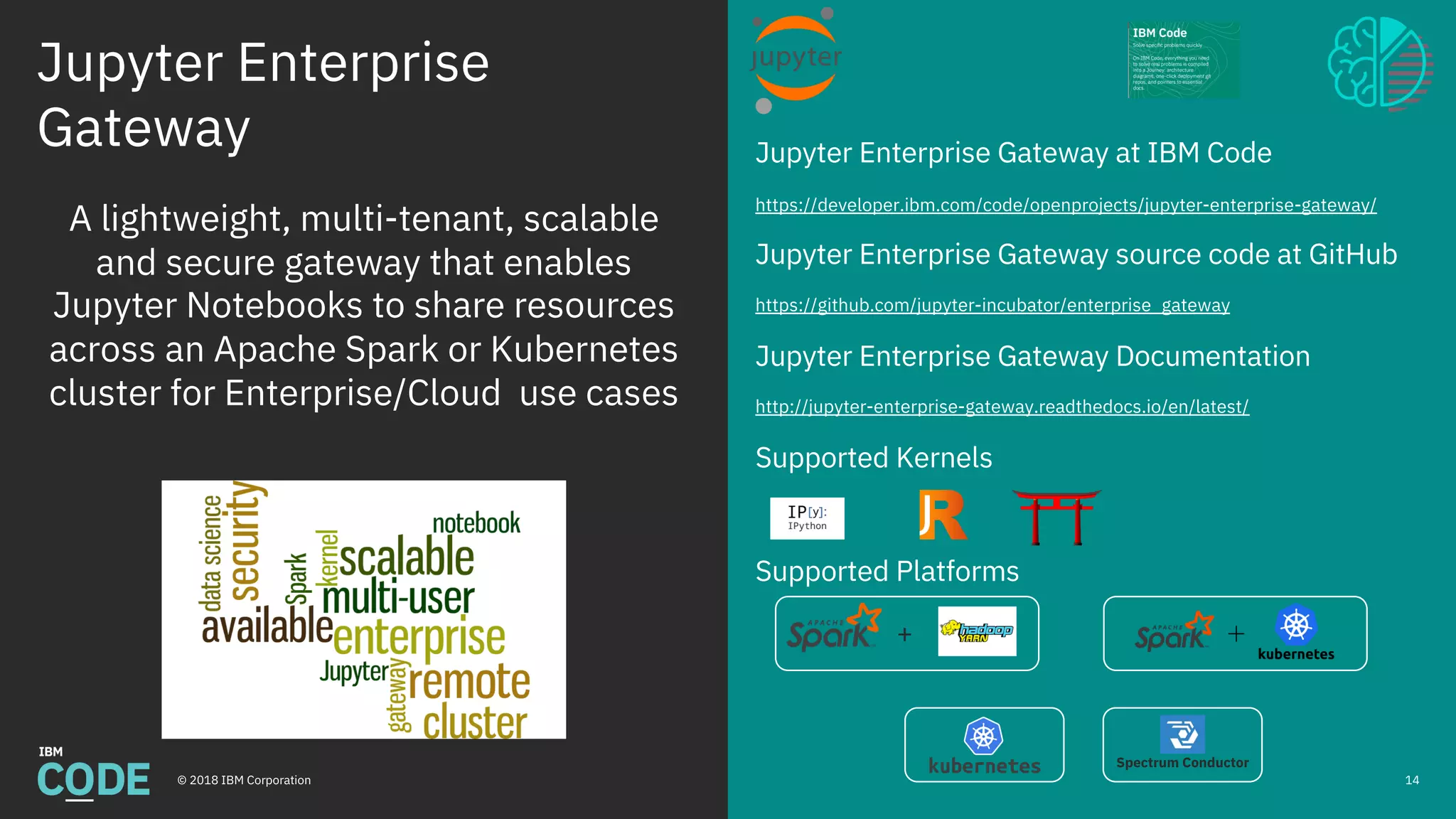
This document discusses Jupyter notebooks and the Jupyter Enterprise Gateway. It provides an overview of Jupyter notebooks, their functionality, and architecture. It then describes the limitations of running Jupyter notebooks at an enterprise scale. The Jupyter Enterprise Gateway is introduced as a solution that enables sharing of resources across clusters in a scalable, secure, and multi-tenant way. The document outlines the key features and architecture of the Gateway when used with YARN and Kubernetes clusters. Finally, it provides information on deploying and connecting to the Jupyter Enterprise Gateway.























































































