

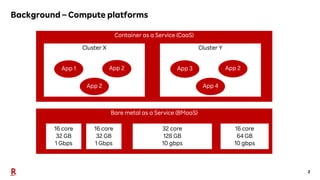
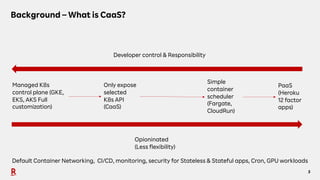



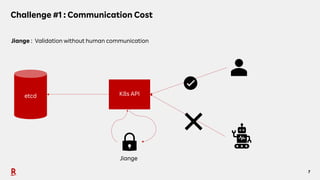


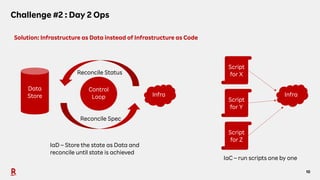

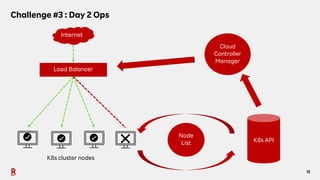


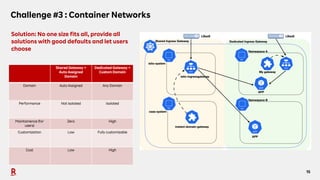
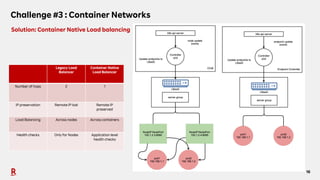



The document discusses the challenges and solutions associated with Container as a Service (CaaS) in the context of cloud computing, focusing on communication costs, Day 2 operations, and container networking. Solutions proposed include the creation of an opinionated internal developer platform, adopting an infrastructure as data approach, and enhancing network performance through dedicated load balancers. Future challenges highlighted involve multi-cluster deployments, stateful applications, and resource management.






















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
