

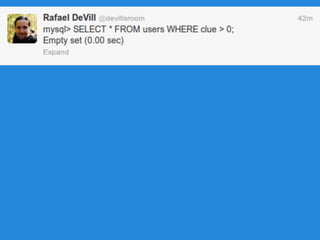
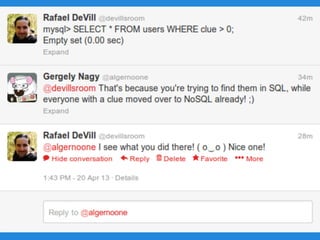
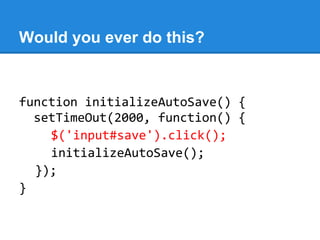


![And if we loathe this:
<script type="text/javascript">
<?php foreach($buttons as $button):?>
initButton(<?=$button["id"]?>,
<?=$button["usefulVar"]?>);
<?php endforeach; ?>
</script>](https://image.slidesharecdn.com/whatsqlshouldactuallybe-130531032447-phpapp01/85/What-SQL-should-actually-be-7-320.jpg)










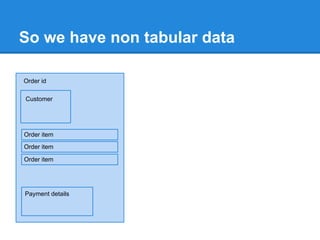


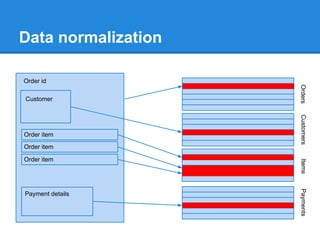





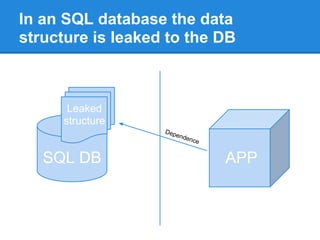
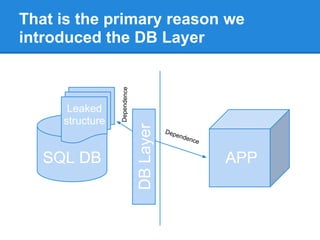
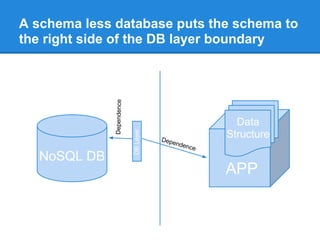


This document discusses issues with using SQL as an API rather than as a user interface. It was designed as a user interface, not an API, leading to problems like leaking data structures and logic to the database. This violates separation of concerns and makes tasks like testing and optimization difficult. The document argues for a native database API that is simpler and separates the application's data structure from what is stored in the database in a schema-less way. This would improve flexibility, testability, and avoid performance issues from changing queries to optimize logic.




















































































