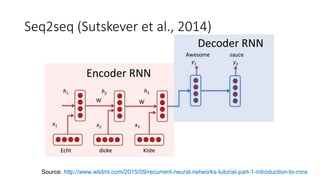
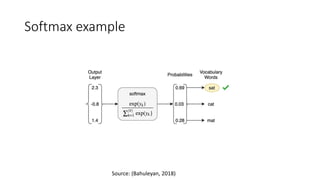
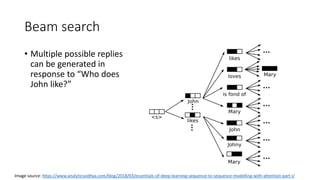
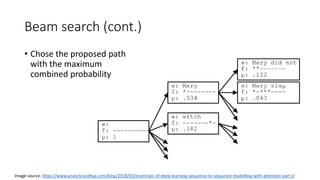
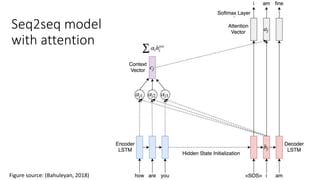
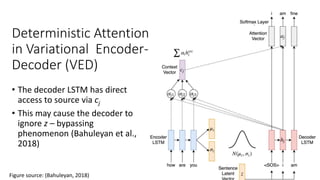
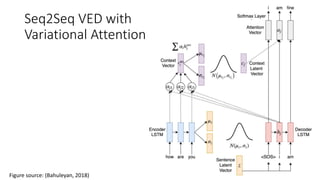
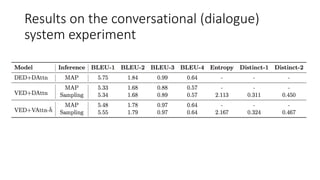
This document describes sequence-to-sequence (seq2seq) models, including an overview of encoder-decoder architectures using recurrent neural networks. It explains how seq2seq models can be used for applications like machine translation, question answering, and summarization. Attention mechanisms are introduced to allow the decoder to focus on different parts of the input sequence at each time step. Variational seq2seq models with variational attention are also described, where the context vector is modeled as a random variable to avoid bypassing the latent code. The document provides examples and results on question generation and dialogue tasks.