Downloaded 23 times








![13
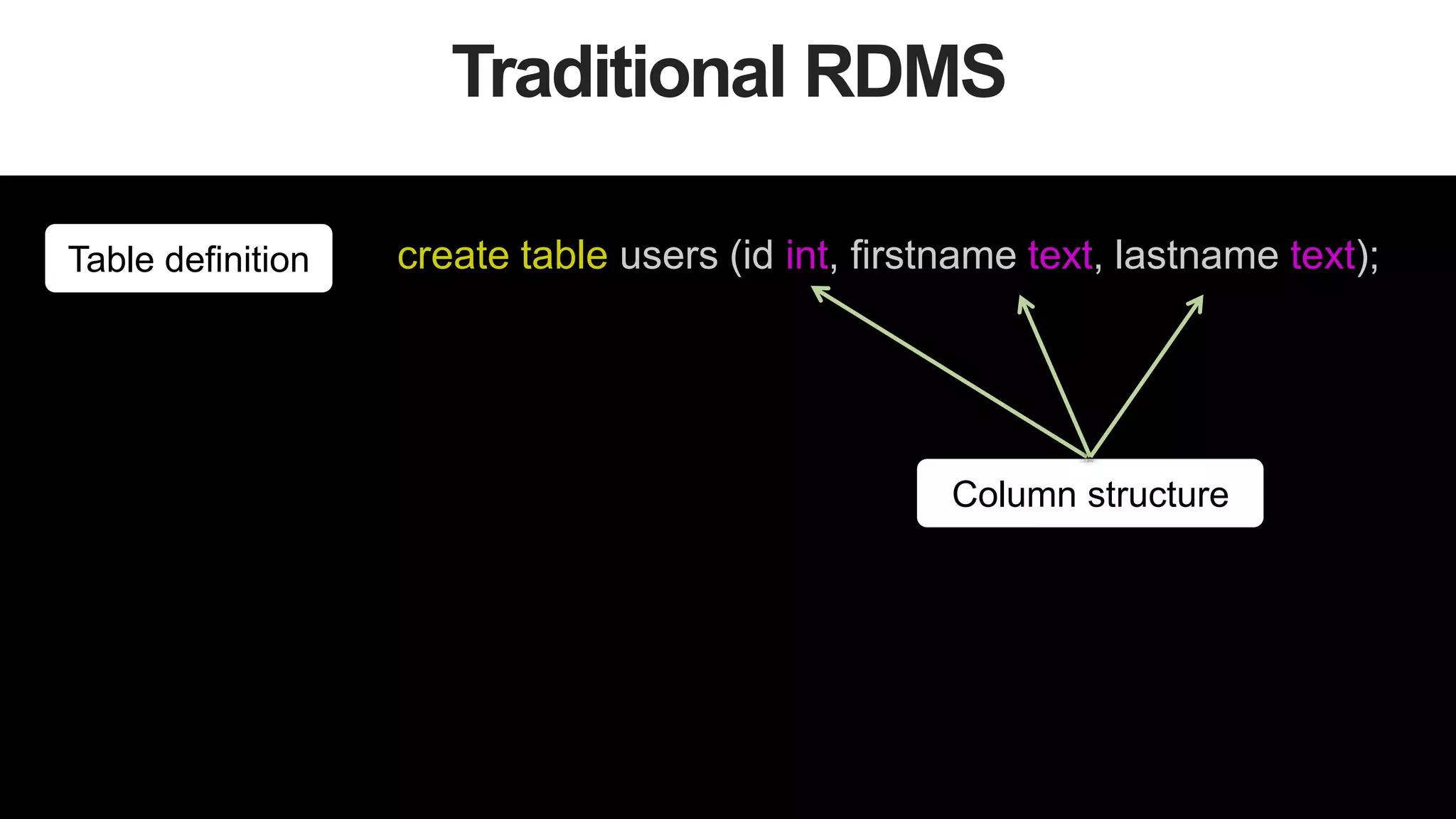
We start from code
public class CatPicture {
int size;
byte[] blob;
}
public class User {
int id;
String firstname;
String lastname;
CatPicture[] cat_pictures;
}](https://image.slidesharecdn.com/stronglytypedlanguagesdynamicdatabases-150805162502-lva1-app6892/75/Webinar-Strongly-Typed-Languages-and-Flexible-Schemas-13-2048.jpg)
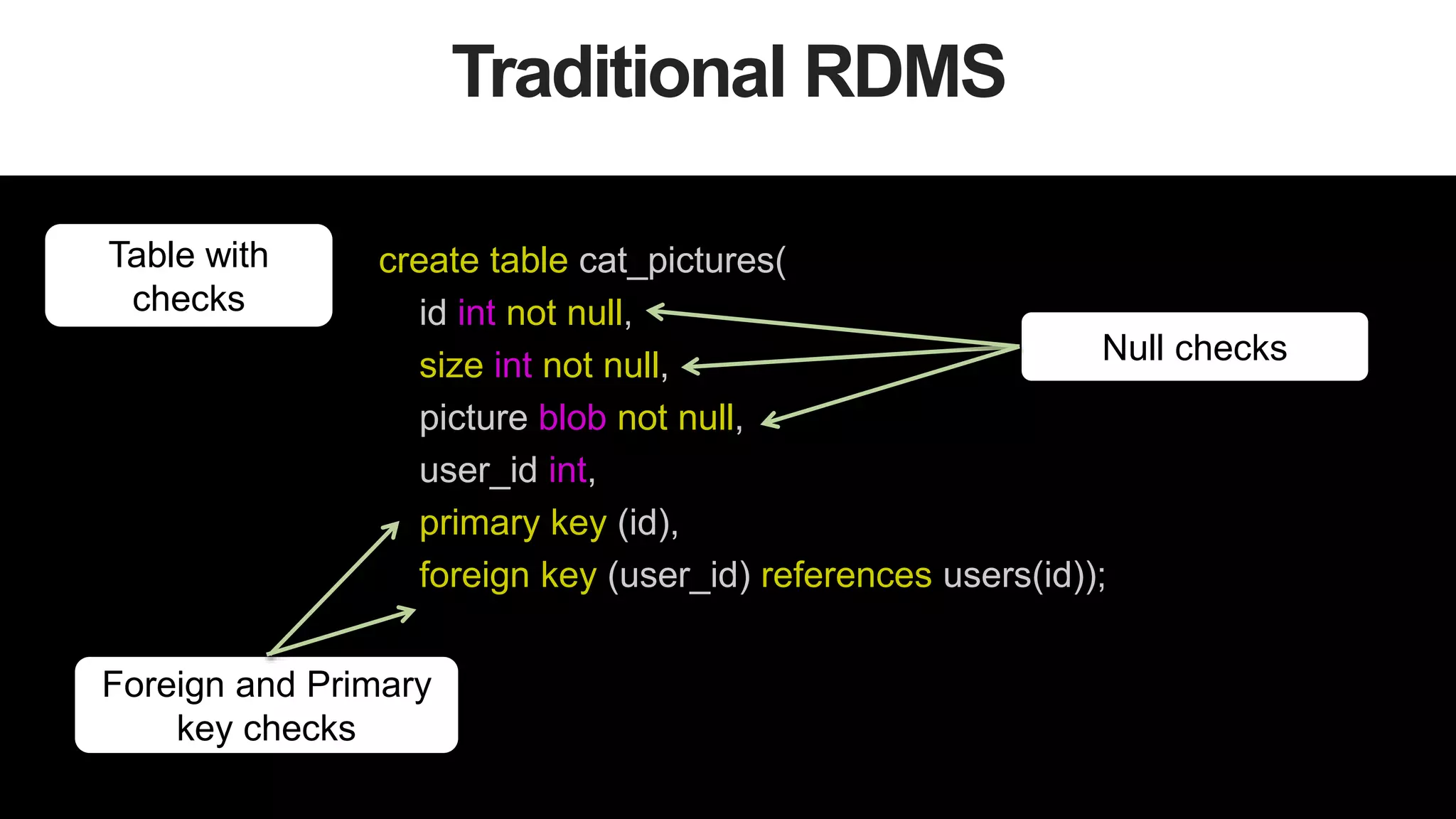
![14
Document Structure
{
_id: 1234,
firstname: 'Juan',
lastname: 'Olivo',
cat_pictures: [ {
size: 10,
picture: BinData("0x133334299399299432"),
}
]
}
Rich Data Types
Embedded
Documents](https://image.slidesharecdn.com/stronglytypedlanguagesdynamicdatabases-150805162502-lva1-app6892/75/Webinar-Strongly-Typed-Languages-and-Flexible-Schemas-14-2048.jpg)

![16
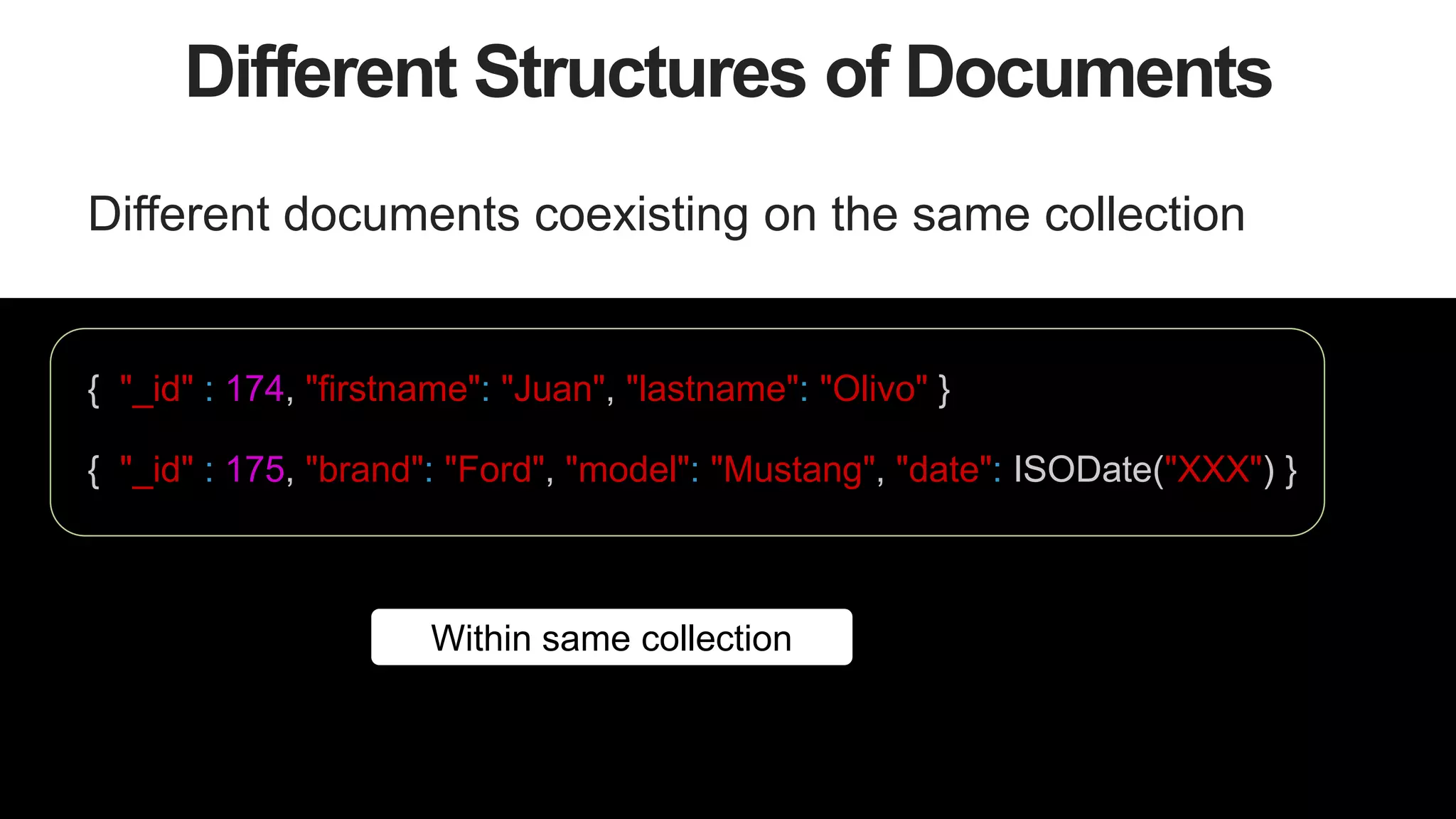
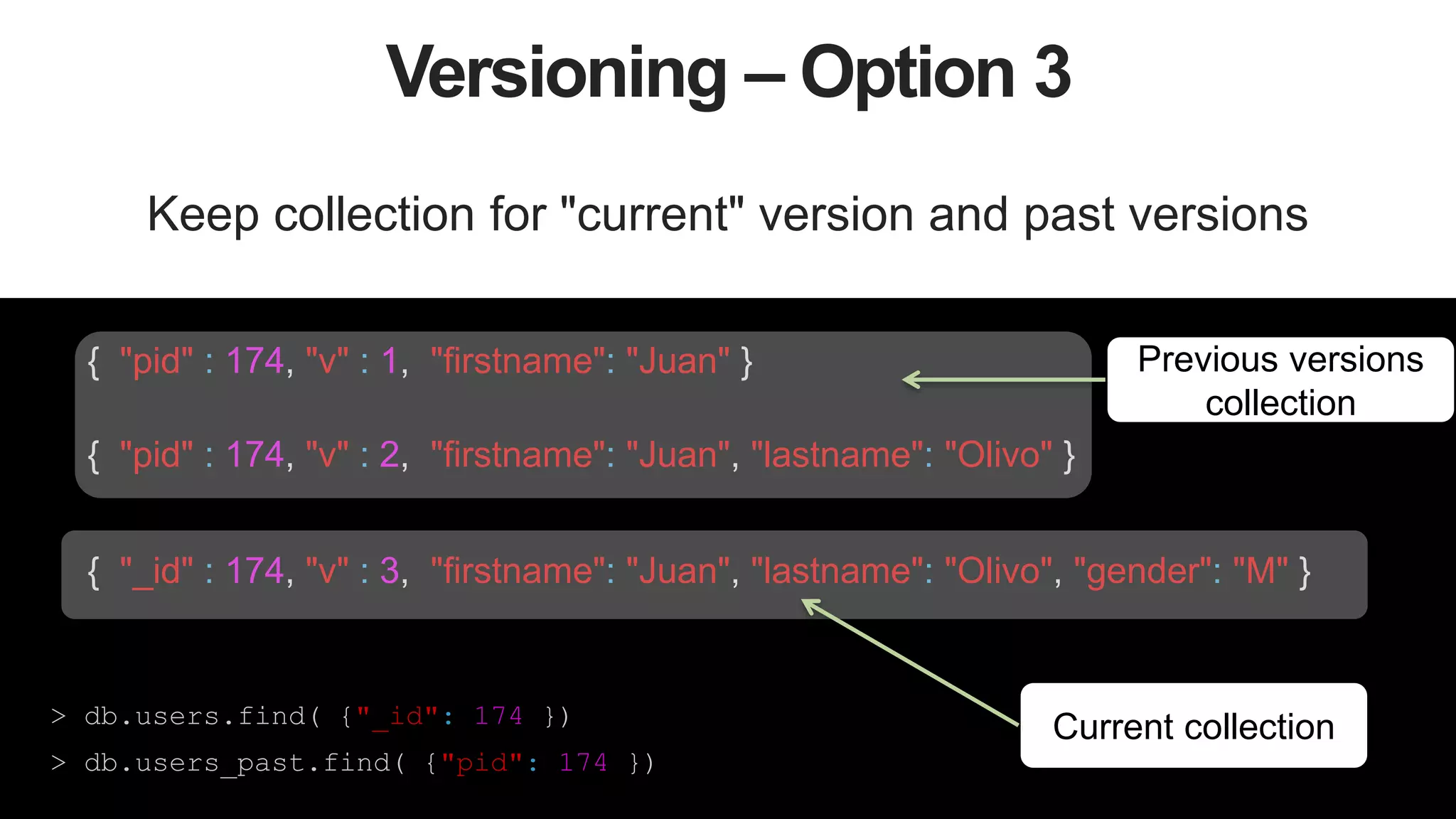
Different Versions of Documents
Same document across time suffers changes on how it
represents data
{ "_id" : 174, "firstname": "Juan" }
{ "_id" : 174, "firstname": "Juan", "lastname": "Olivo" }
First Version
Second Version
{ "_id" : 174, "firstname": "Juan", "lastname": "Olivo" , "cat_pictures":
[{"size": 10, picture: BinData("0x133334299399299432")}]
}
Third Version](https://image.slidesharecdn.com/stronglytypedlanguagesdynamicdatabases-150805162502-lva1-app6892/75/Webinar-Strongly-Typed-Languages-and-Flexible-Schemas-16-2048.jpg)

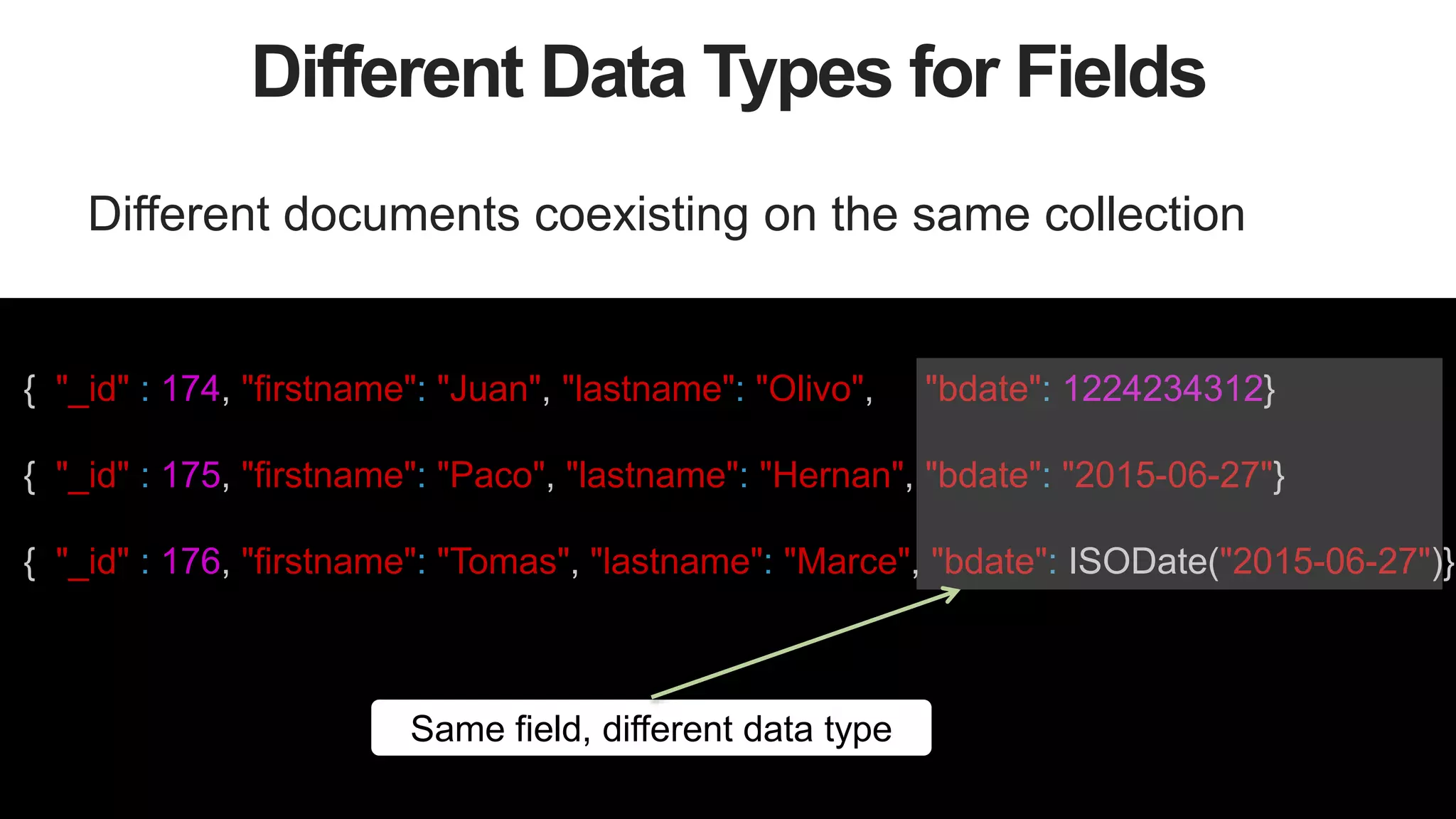











![33
Spring Data Document Structure
{
"_id": 1,
"first_name": "first",
"lastname": "last",
"catpictures": [
{
"size": 10,
"blob": BinData(0, "Kr3AqmvV1R9TJQ==")
},
]
}](https://image.slidesharecdn.com/stronglytypedlanguagesdynamicdatabases-150805162502-lva1-app6892/75/Webinar-Strongly-Typed-Languages-and-Flexible-Schemas-33-2048.jpg)


![36
Morphia Document Structure
{
"_id": 1,
"className": "examples.odms.morphia.pojos.User",
"firstname": "first",
"lastname": "last",
"catpictures": [
{
"size": 10,
"blob": BinData(0, "Kr3AqmvV1R9TJQ==")
},
]
}
Class Definition](https://image.slidesharecdn.com/stronglytypedlanguagesdynamicdatabases-150805162502-lva1-app6892/75/Webinar-Strongly-Typed-Languages-and-Flexible-Schemas-36-2048.jpg)





![42
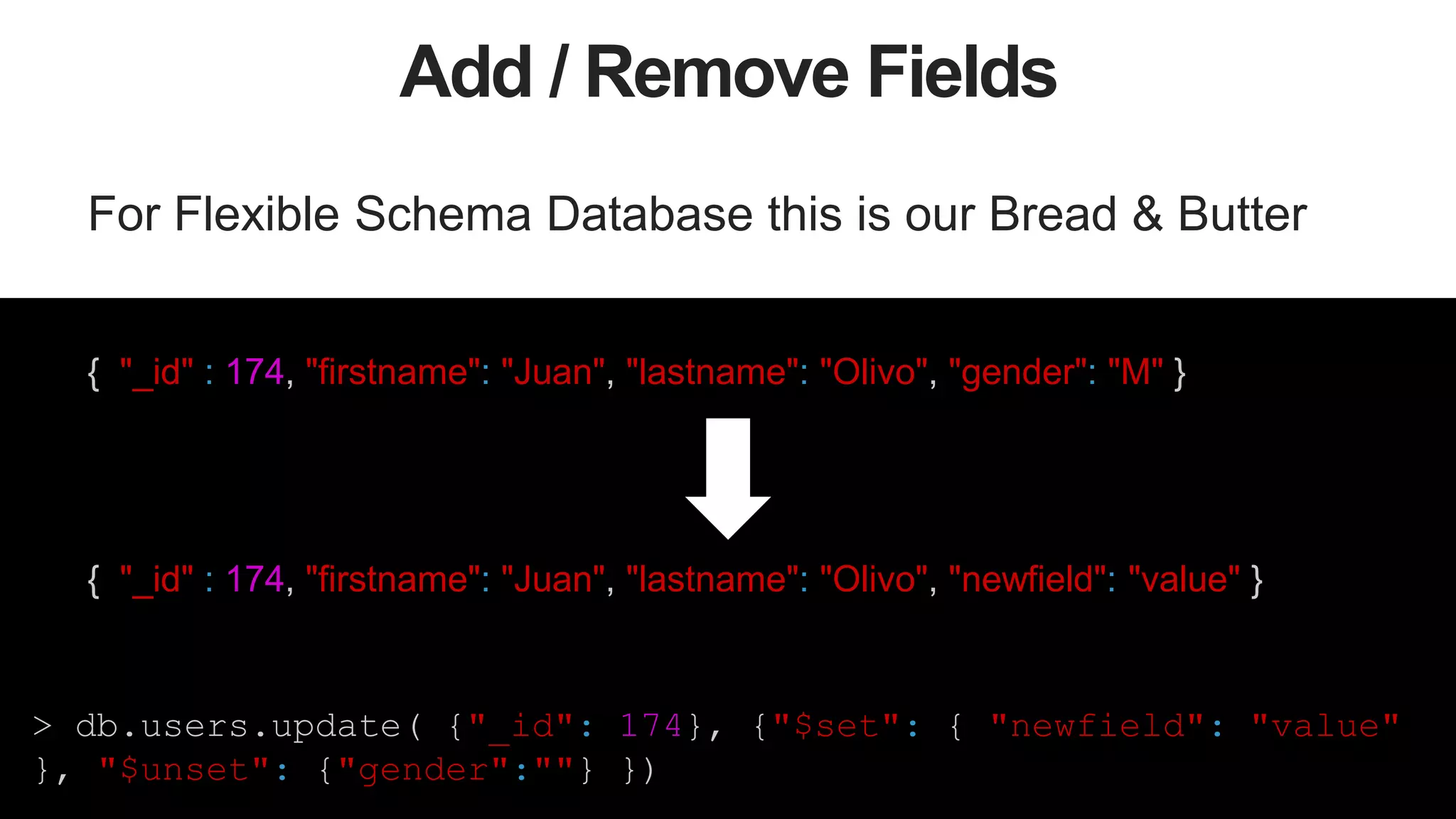
Versioning – Option 2
Store all document versions inside a single document.
> db.users.update( {"_id": 174 } , { {"$set" :{ "current": ... },
{"$inc": { "current.v": 1 }}, {"$addToSet": {"prev": {... }}} } )
Current value
{ "_id" : 174, "current" : { "v" :3, "attr1": 184, "attr2" : "A-1" },
"prev" : [
{ "v" : 1, "attr1": 165 },
{ "v" : 2, "attr1": 165, "attr2": "A-1" }
]
}
Previous values](https://image.slidesharecdn.com/stronglytypedlanguagesdynamicdatabases-150805162502-lva1-app6892/75/Webinar-Strongly-Typed-Languages-and-Flexible-Schemas-42-2048.jpg)






![53
Extract Document into Collection
Normalize your schema
{"size": 10, picture: BinData("0x133334299399299432")}
{ "_id" : 174, "firstname": "Juan",
"lastname": "Olivo",}
> db.users.aggregate( [
{$unwind: "$cat_pictures"},
{$project: { "_id":0, "uid":"$_id", "size": "$cat_pictures.size",
"picture": "$cat_pictures.picture"}},
{$out:"cats"}])
{ "_id" : 174, "firstname": "Juan", "lastname": "Olivo" , "cat_pictures":
[{"size": 10, picture: BinData(0, "m/lhLlLmoNiUKQ==")}]
}
{"size": 10, "picture": BinData(0, "m/lhLlLmoNiUKQ==")}](https://image.slidesharecdn.com/stronglytypedlanguagesdynamicdatabases-150805162502-lva1-app6892/75/Webinar-Strongly-Typed-Languages-and-Flexible-Schemas-53-2048.jpg)

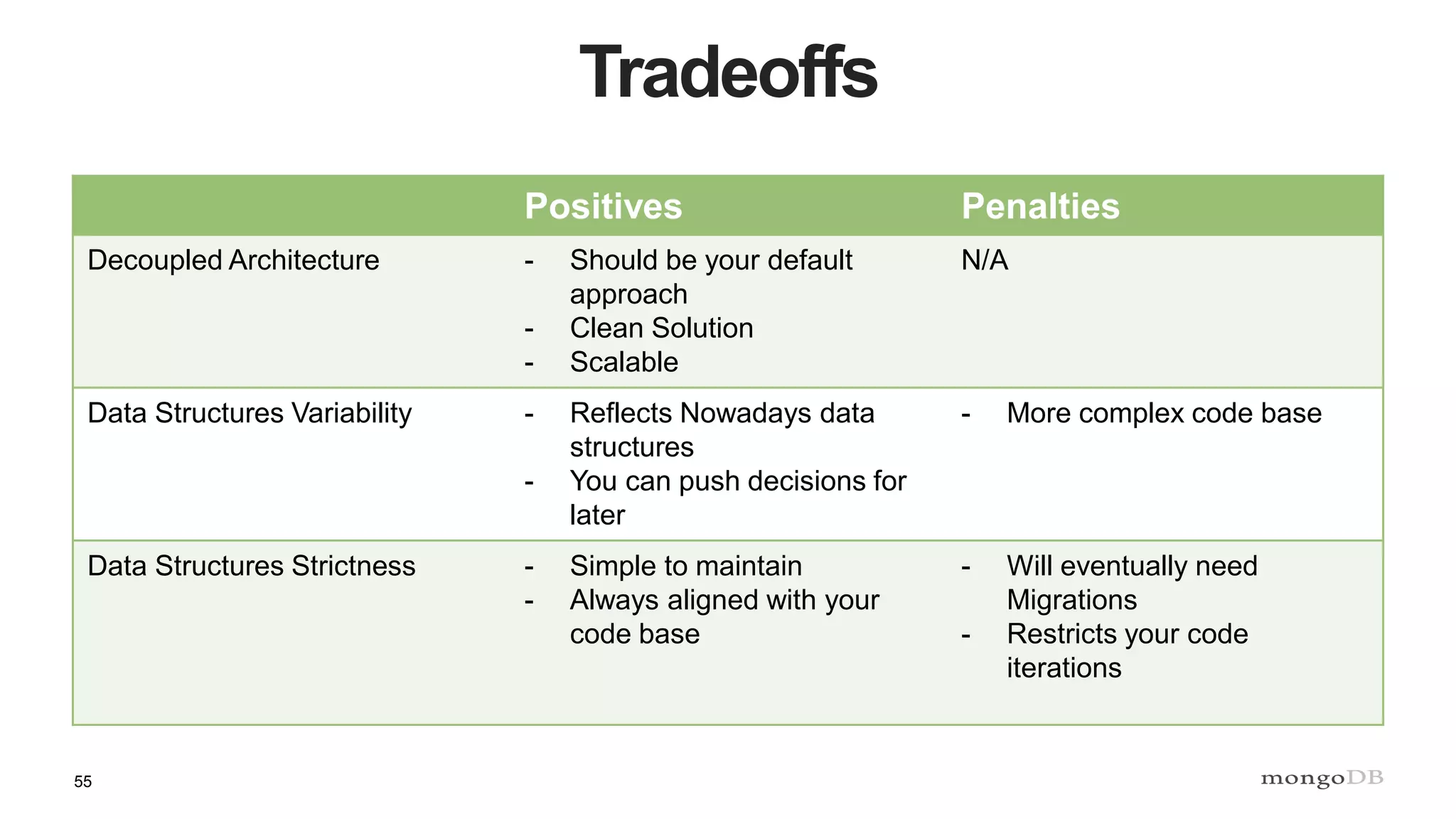






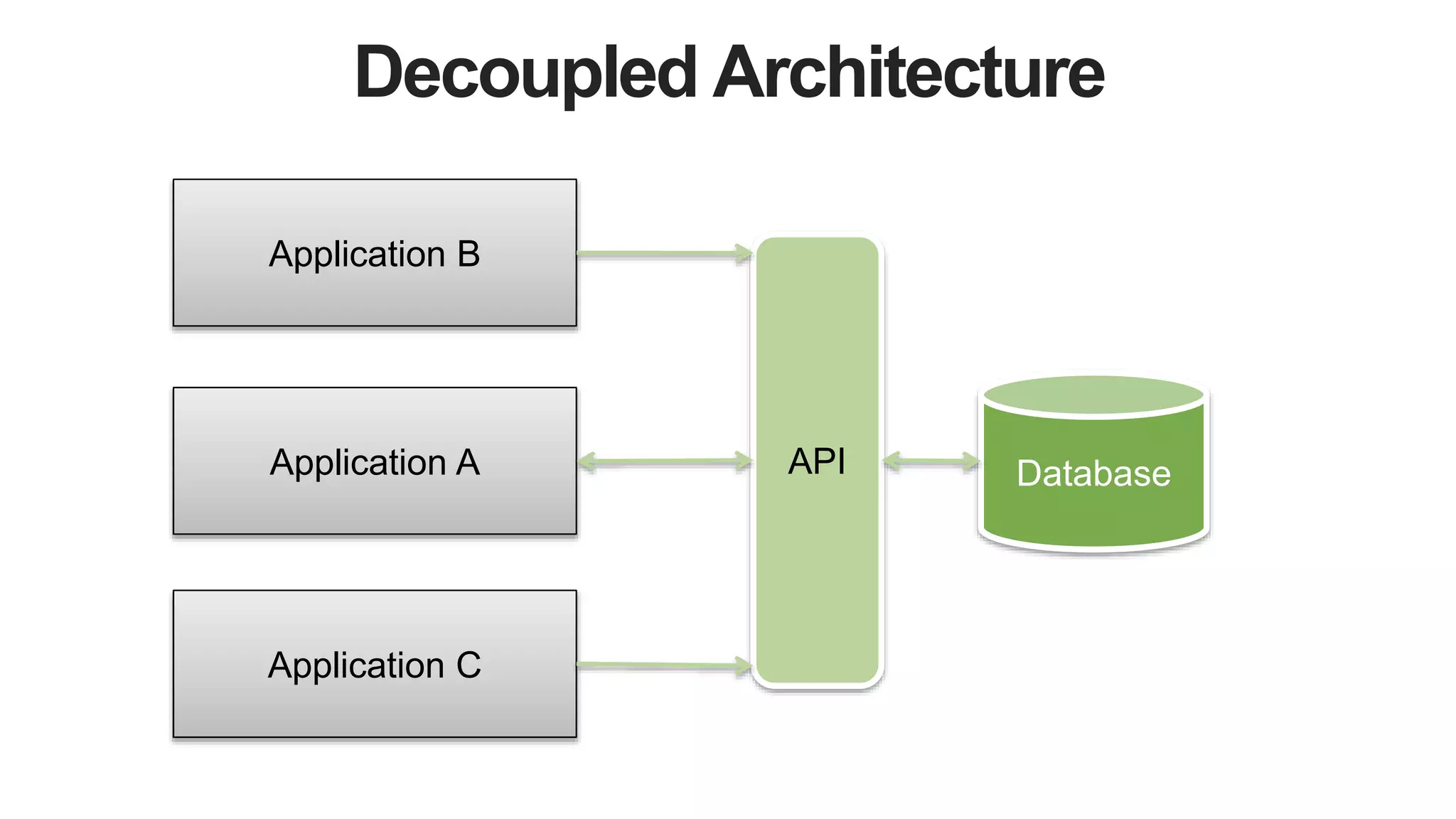
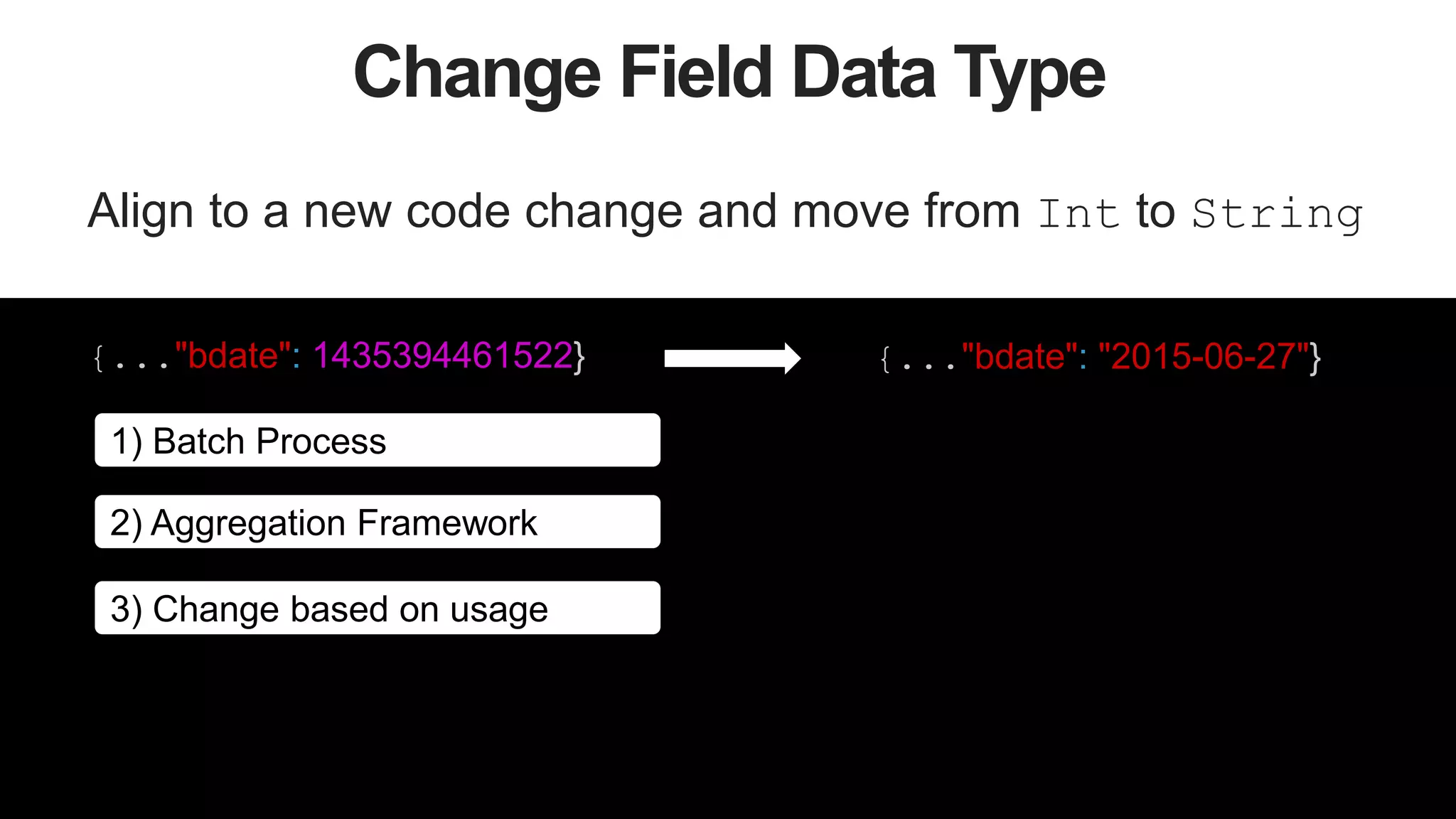
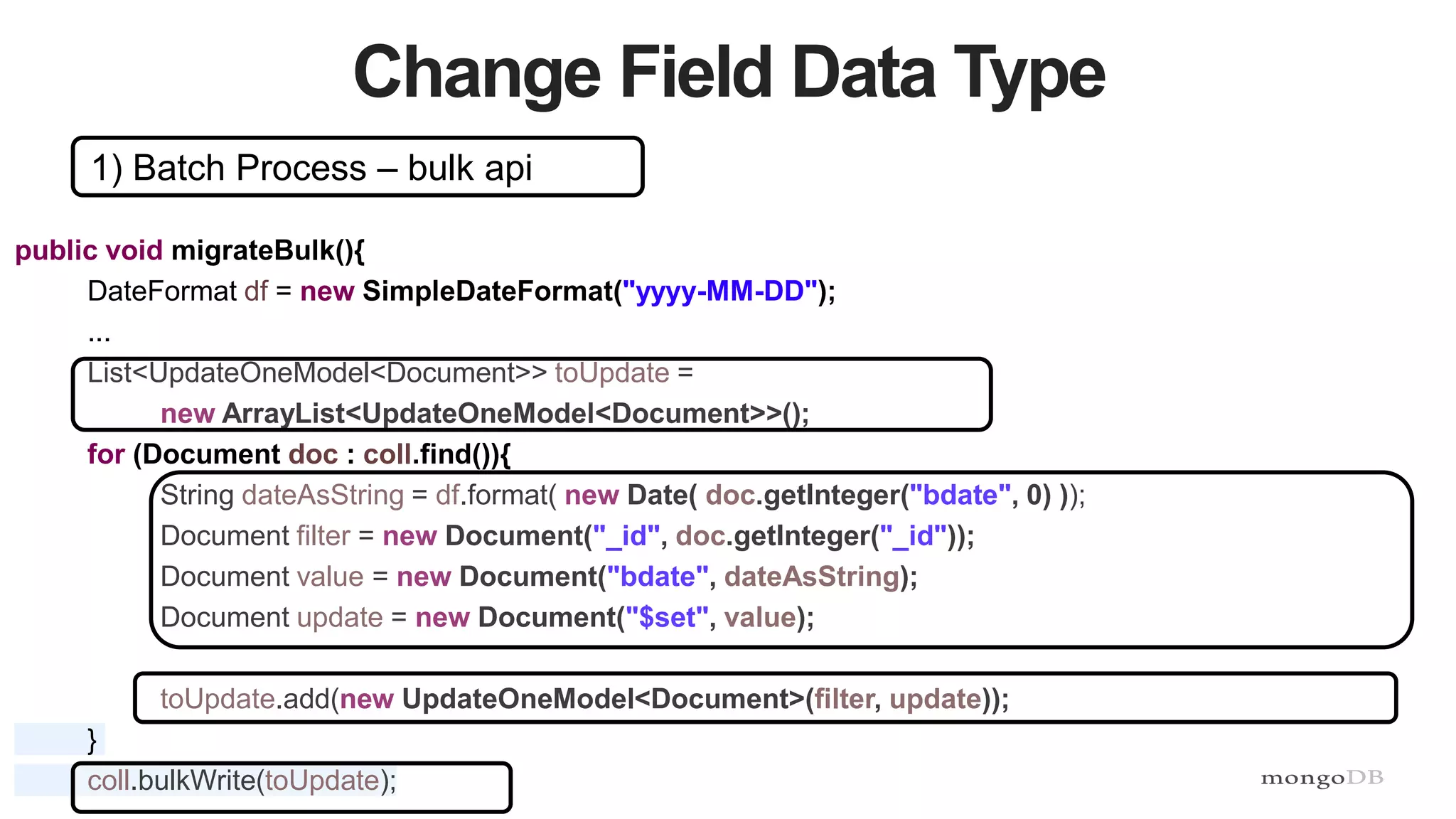
This document discusses strategies for managing flexible schemas in strongly typed languages and databases, including decoupled architectures, object-document mappers (ODMs), versioning, and data migrations. It describes how decoupled architectures allow business logic and data storage to evolve independently. ODMs like Spring Data and Morphia reduce impedance mismatch and handle mapping between objects and database documents. Versioning strategies include incrementing fields, storing full documents, or maintaining separate collections for current and past versions. Migrations involve adding/removing fields, changing names/data types, or extracting embedded documents. The document outlines tradeoffs between these approaches.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)





























