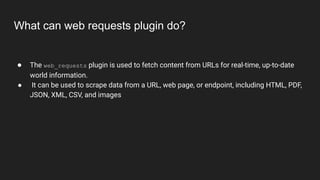
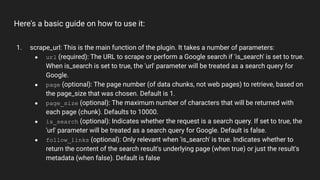
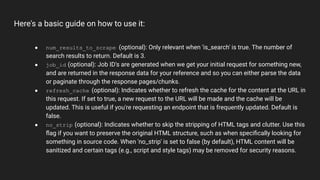
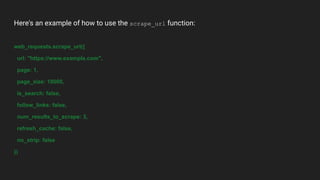
The web_requests plugin allows fetching content from URLs. It can scrape data from web pages, endpoints, HTML, PDFs, JSON, XML, CSVs and images. The scrape_url function is used to scrape a URL and accepts parameters like the URL, page number, page size, whether it's a search query, number of results to return, and options for caching and stripping HTML. An example shows calling scrape_url to fetch content from a URL.