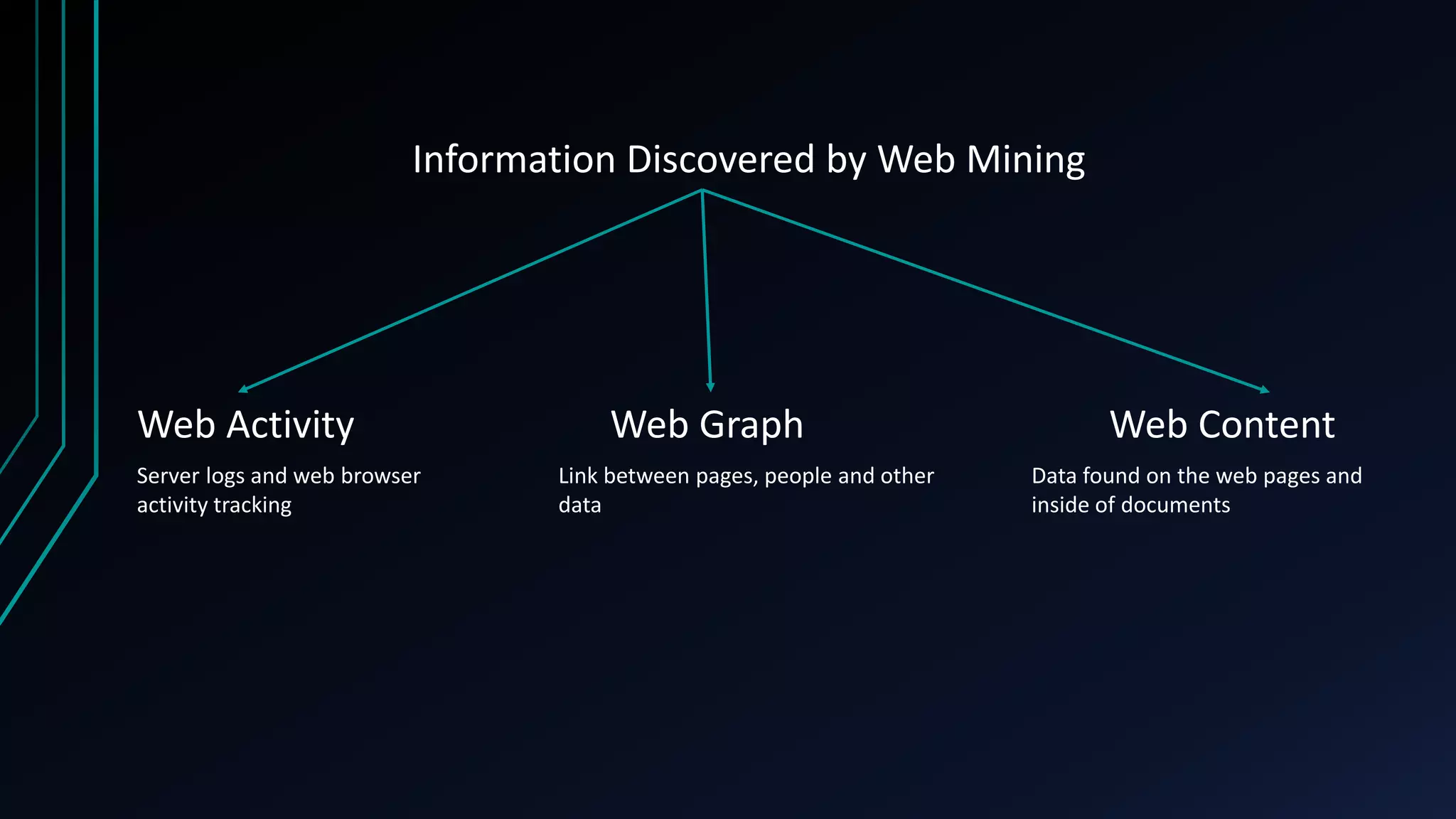
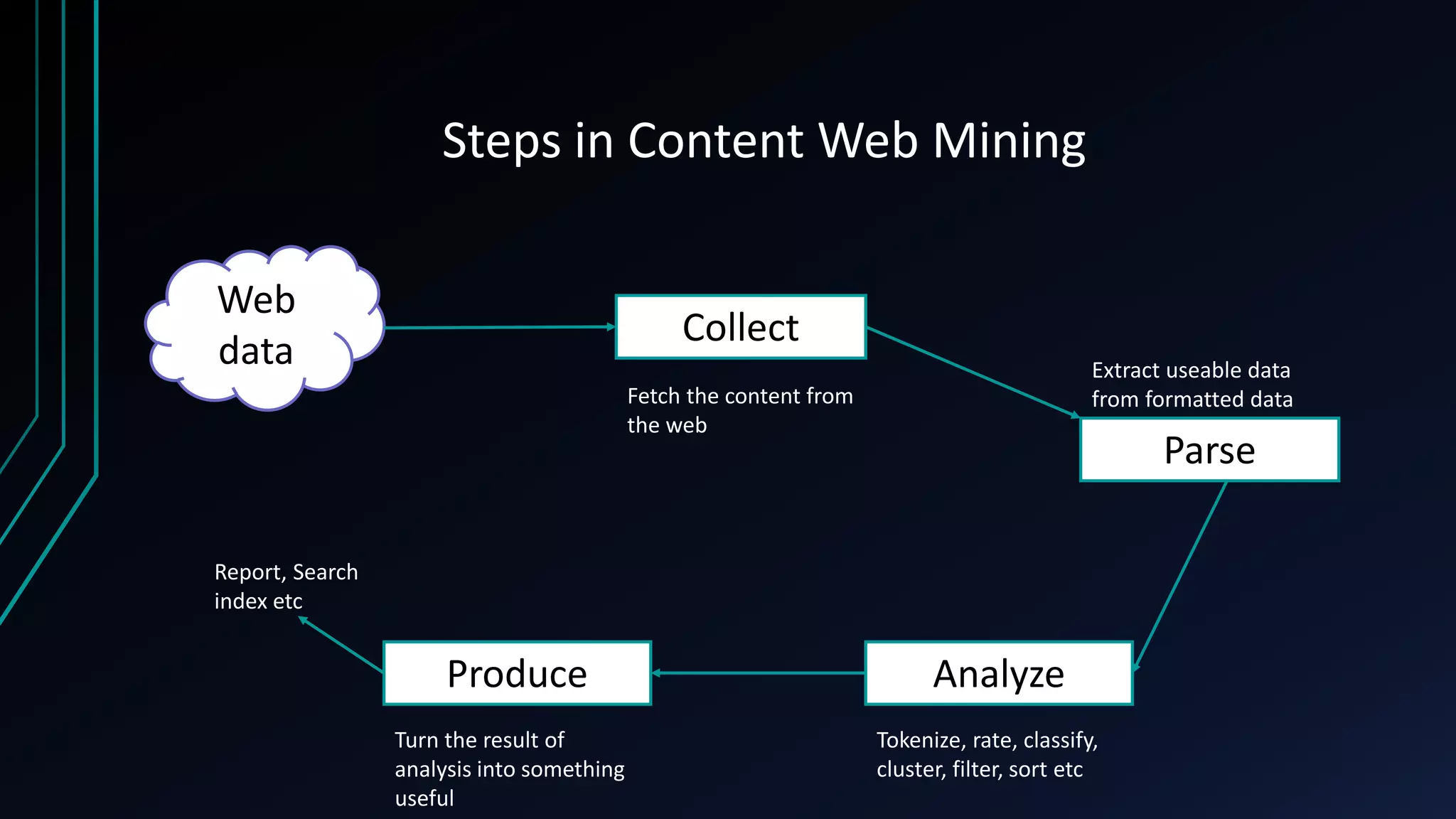
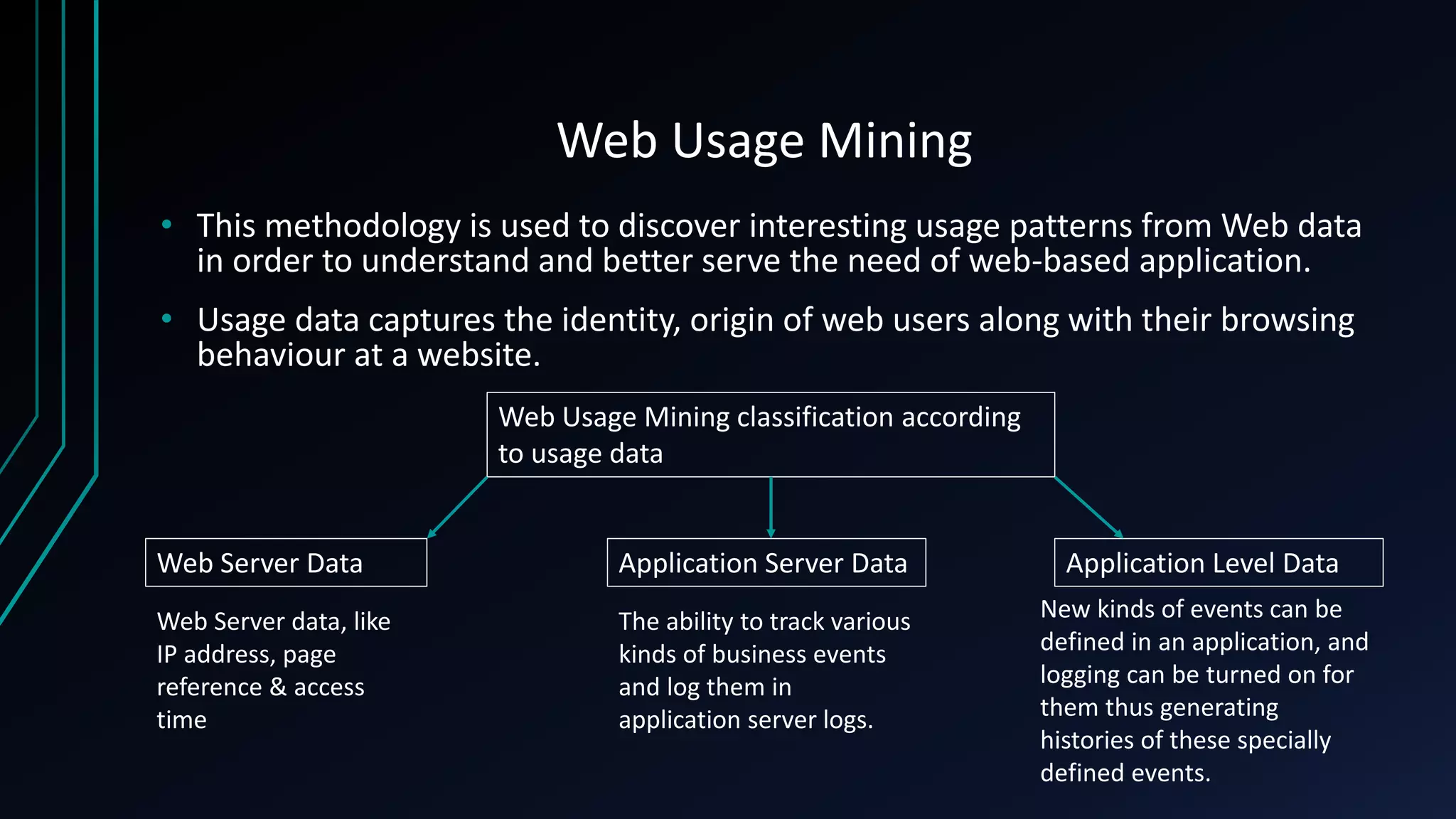
The document provides an overview of web mining, describing it as the process of extracting patterns and insights from web data using various algorithms and methodologies. It outlines different types of web mining, including web usage, web content, and web structure mining, along with their specific techniques and applications. Additionally, it distinguishes between web mining and traditional data mining, highlighting differences in data access and structure.