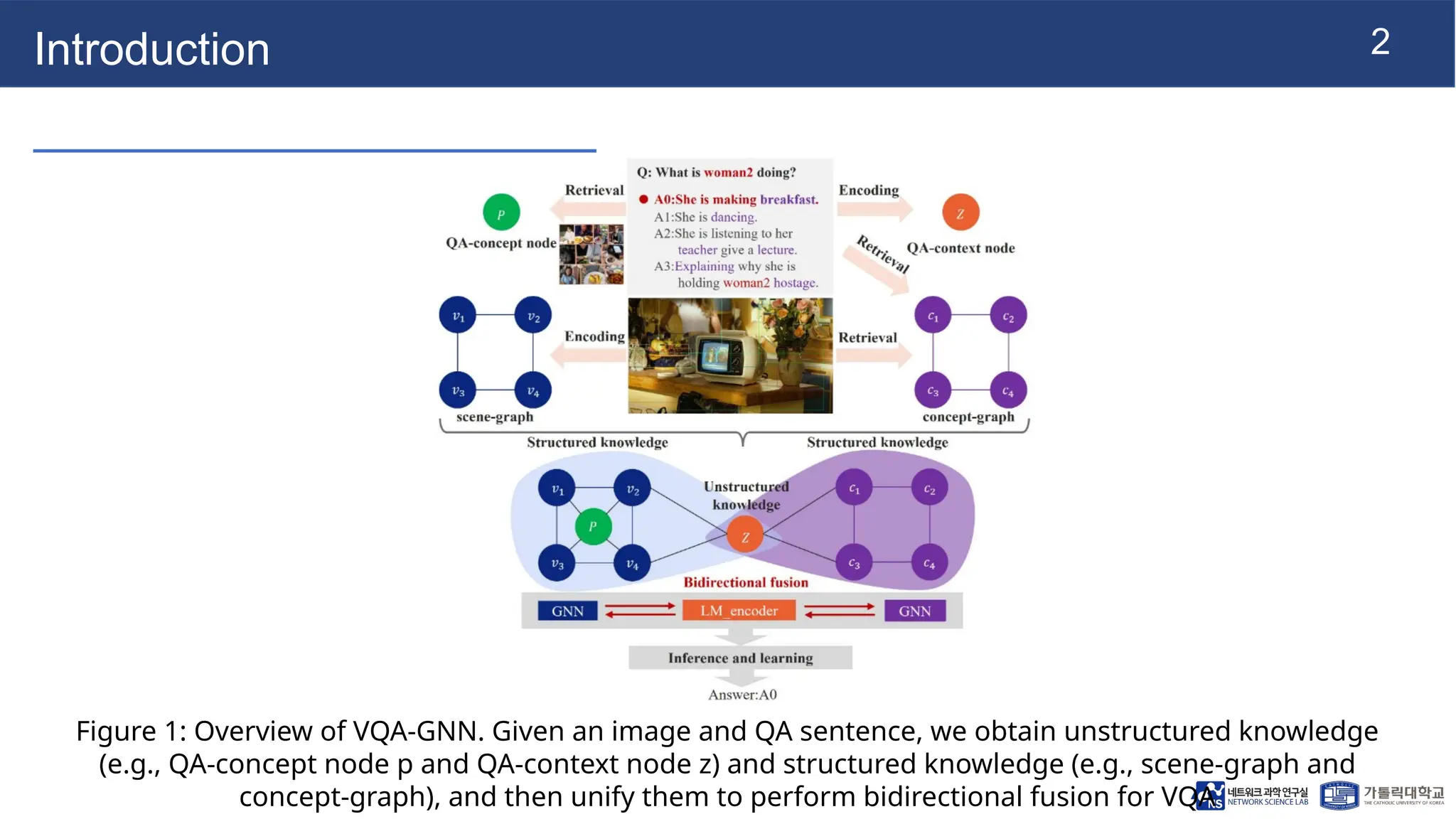
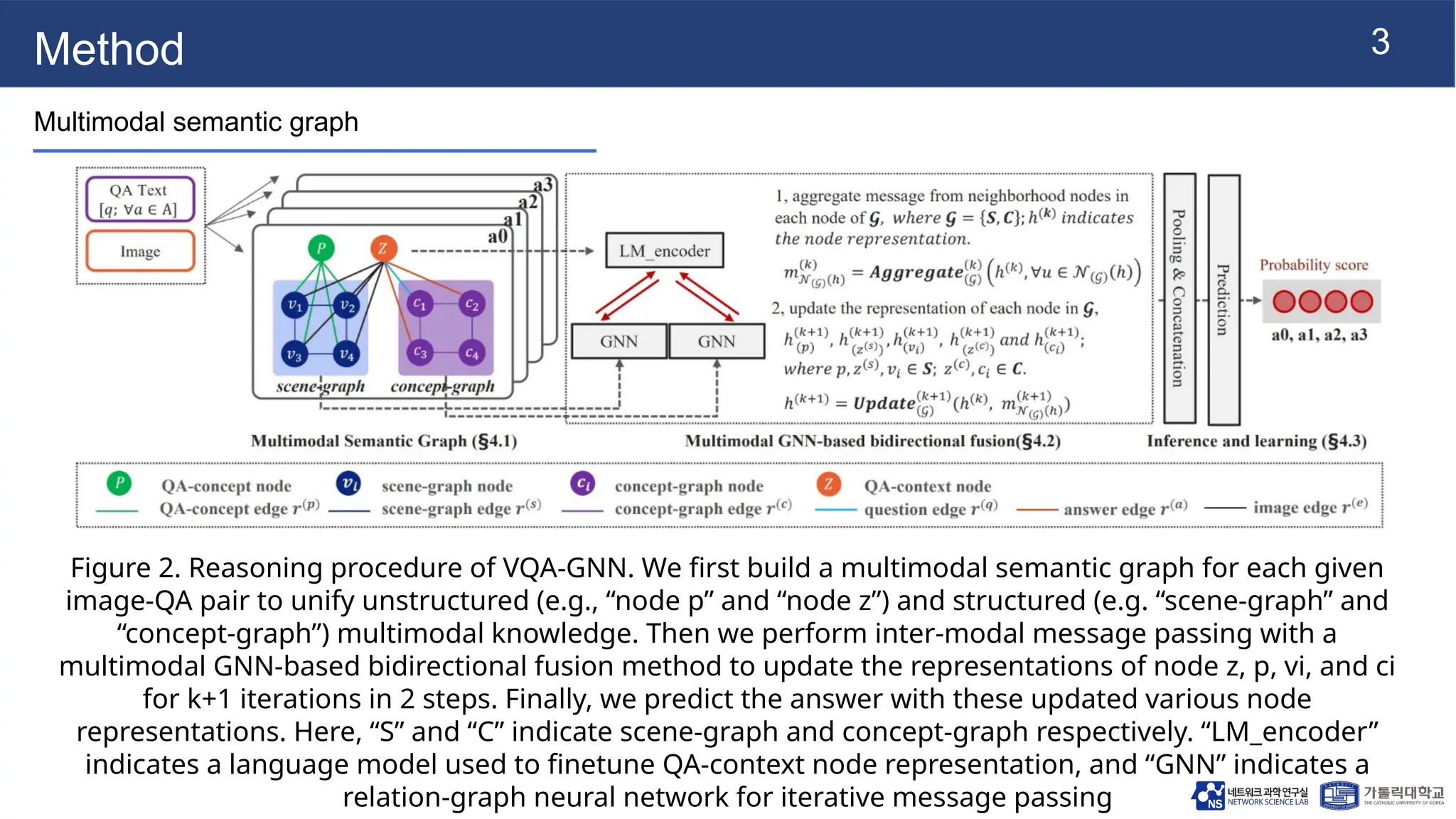
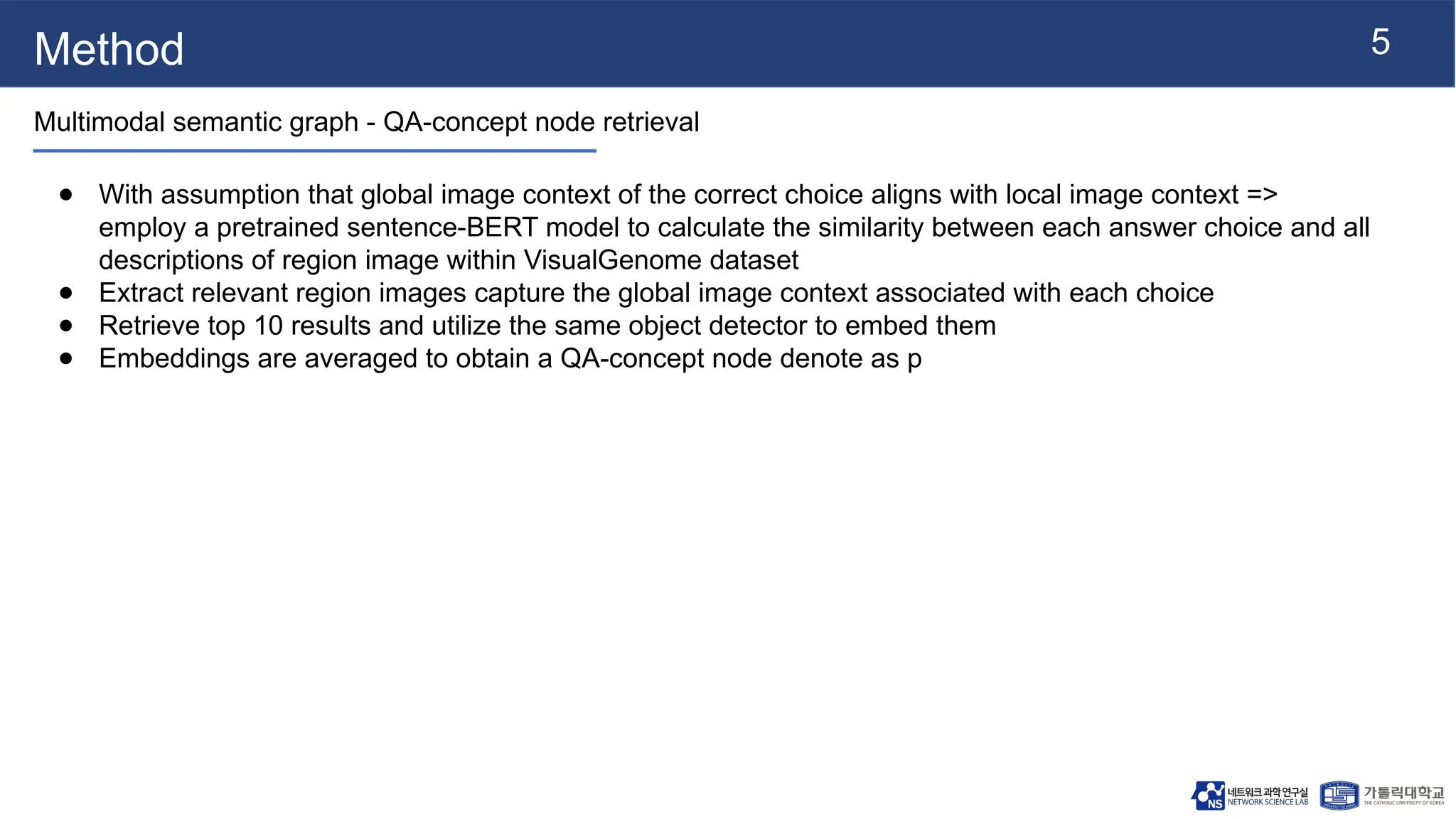
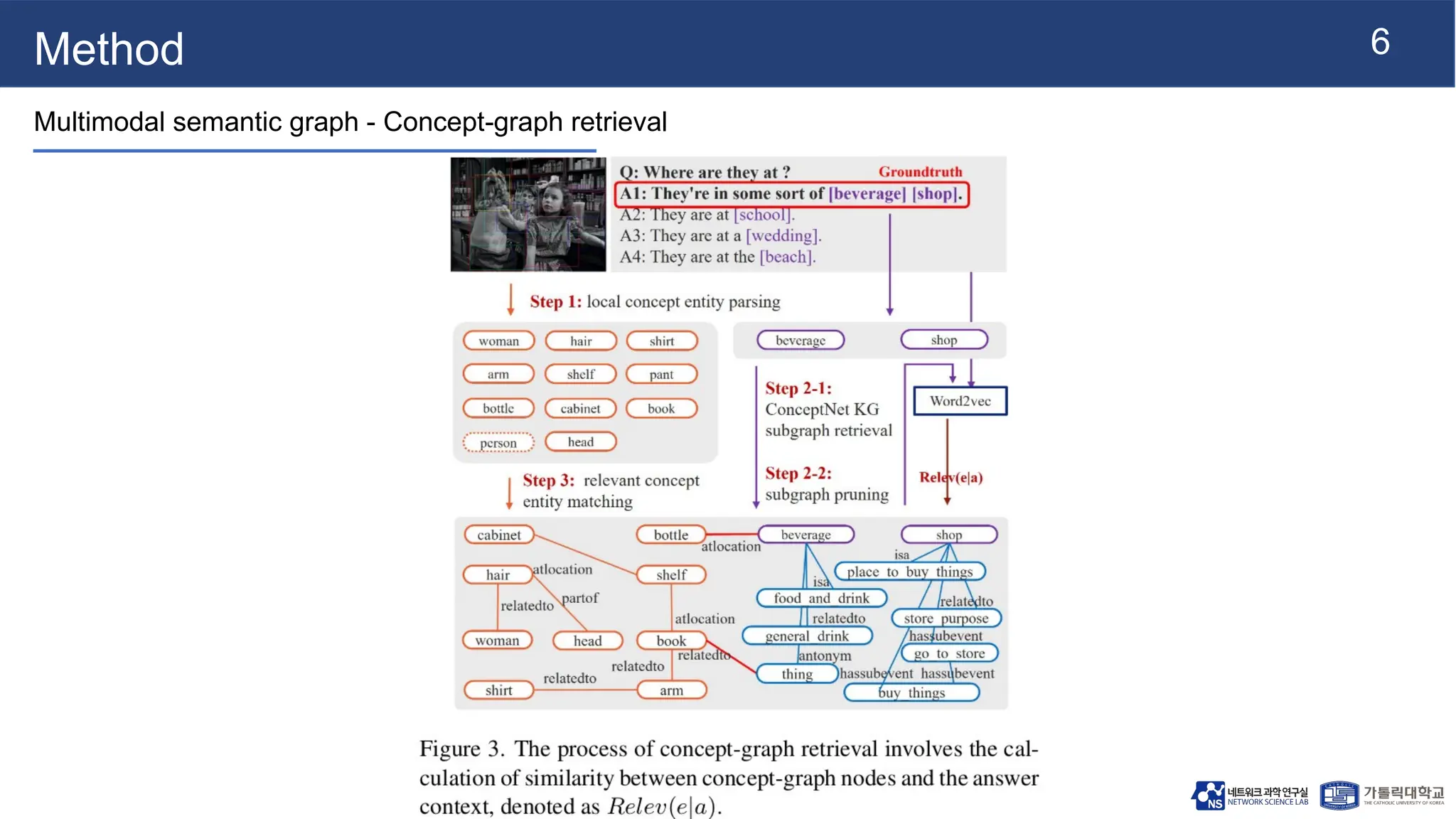
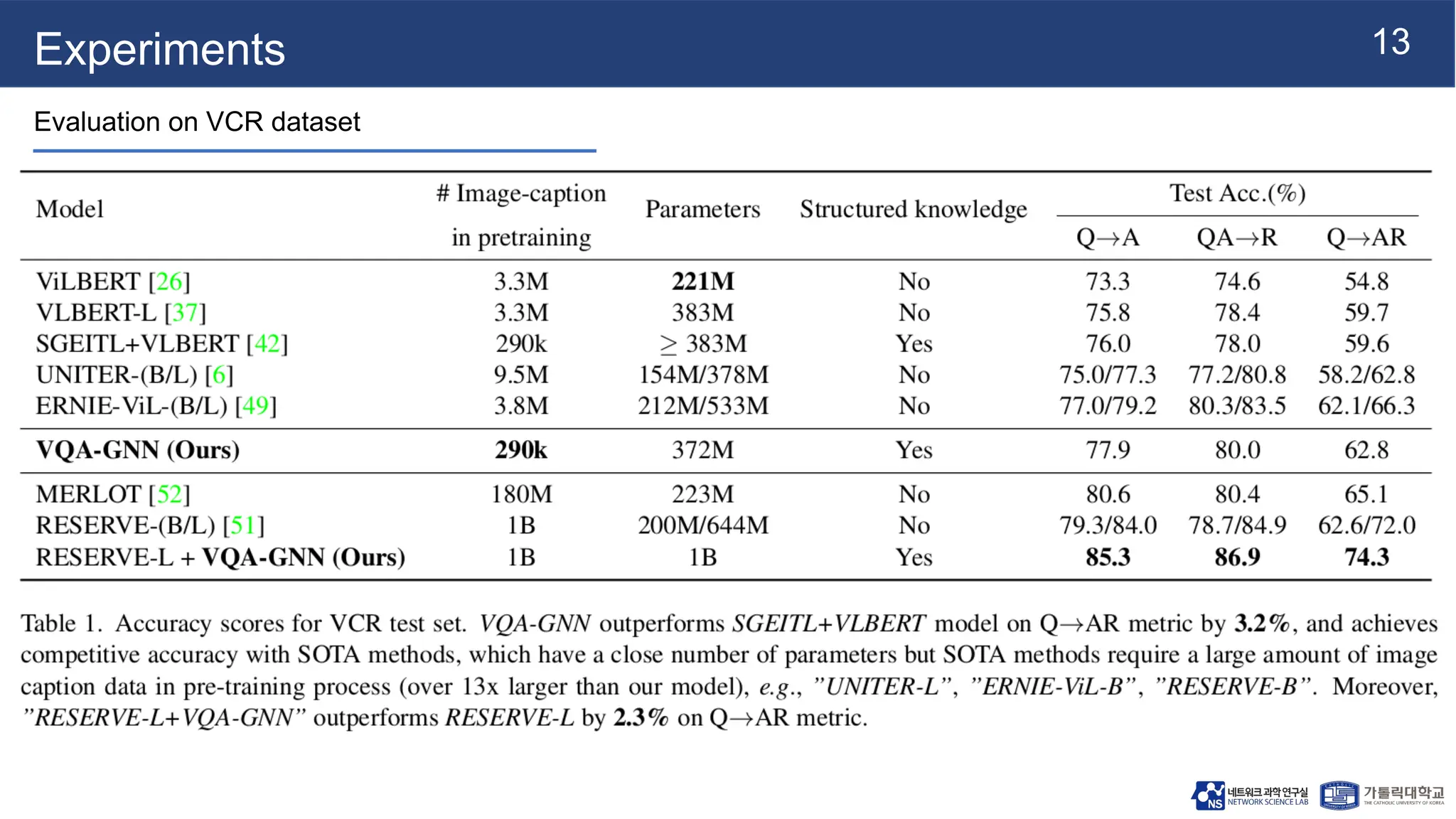
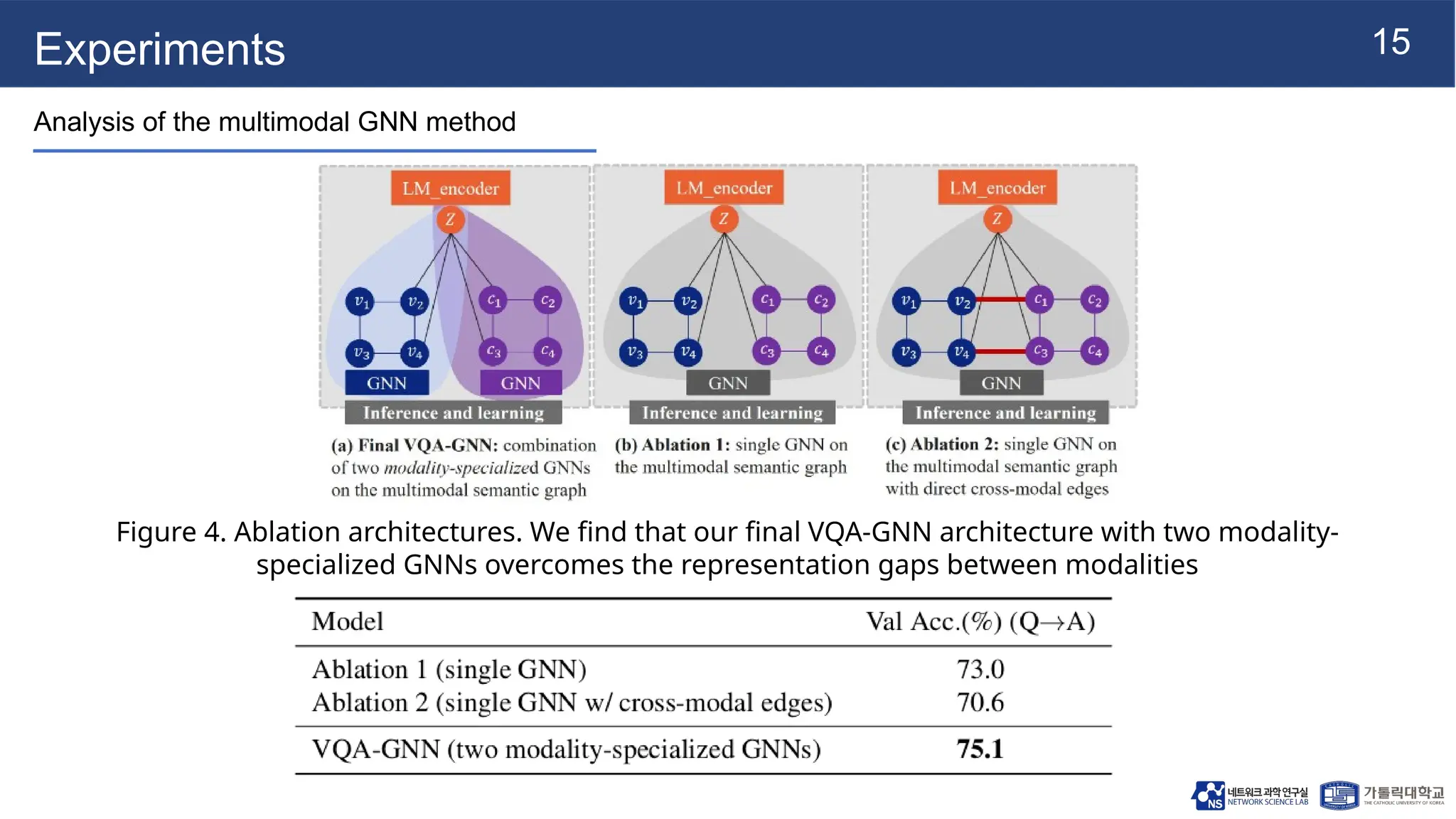
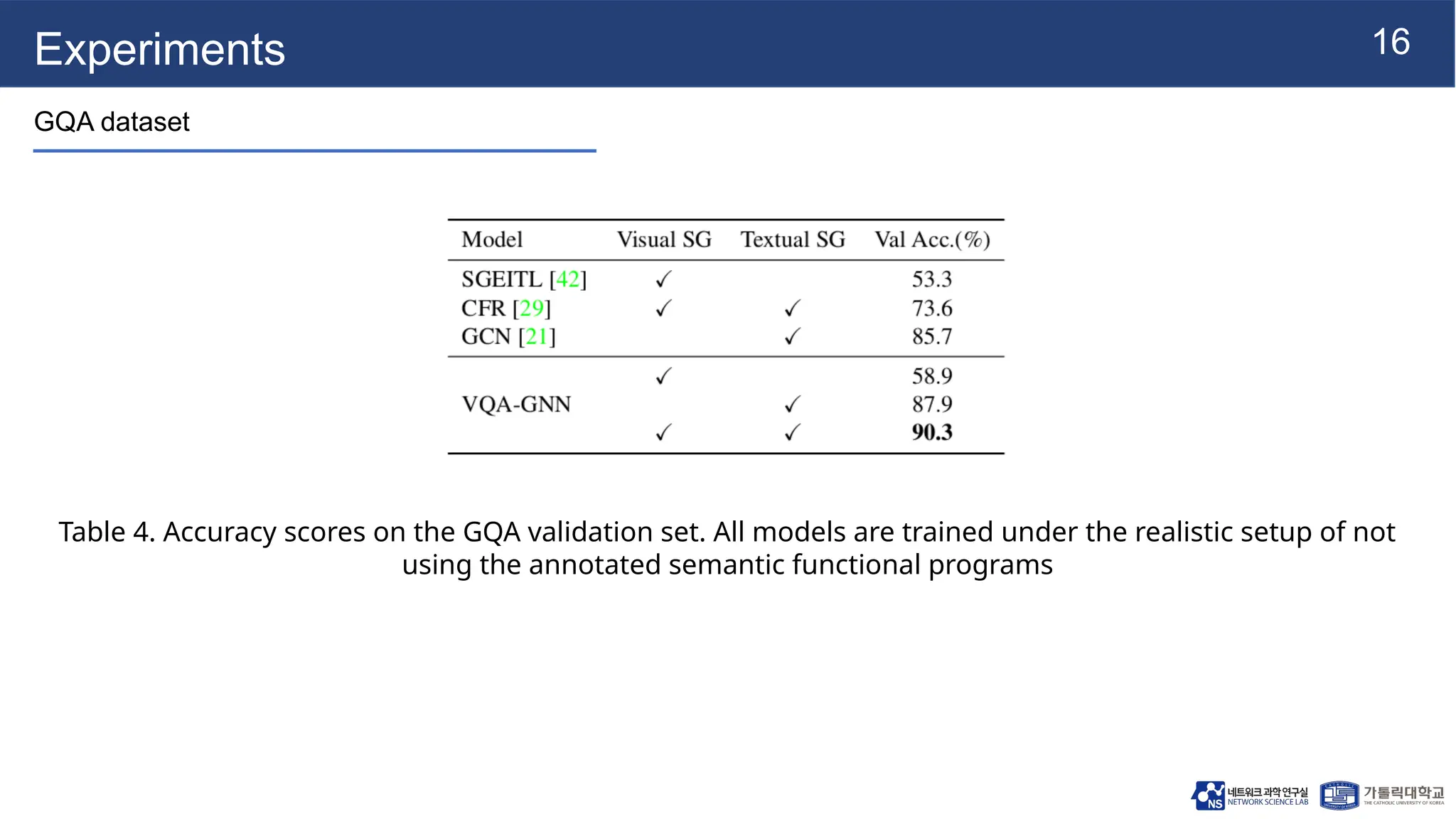
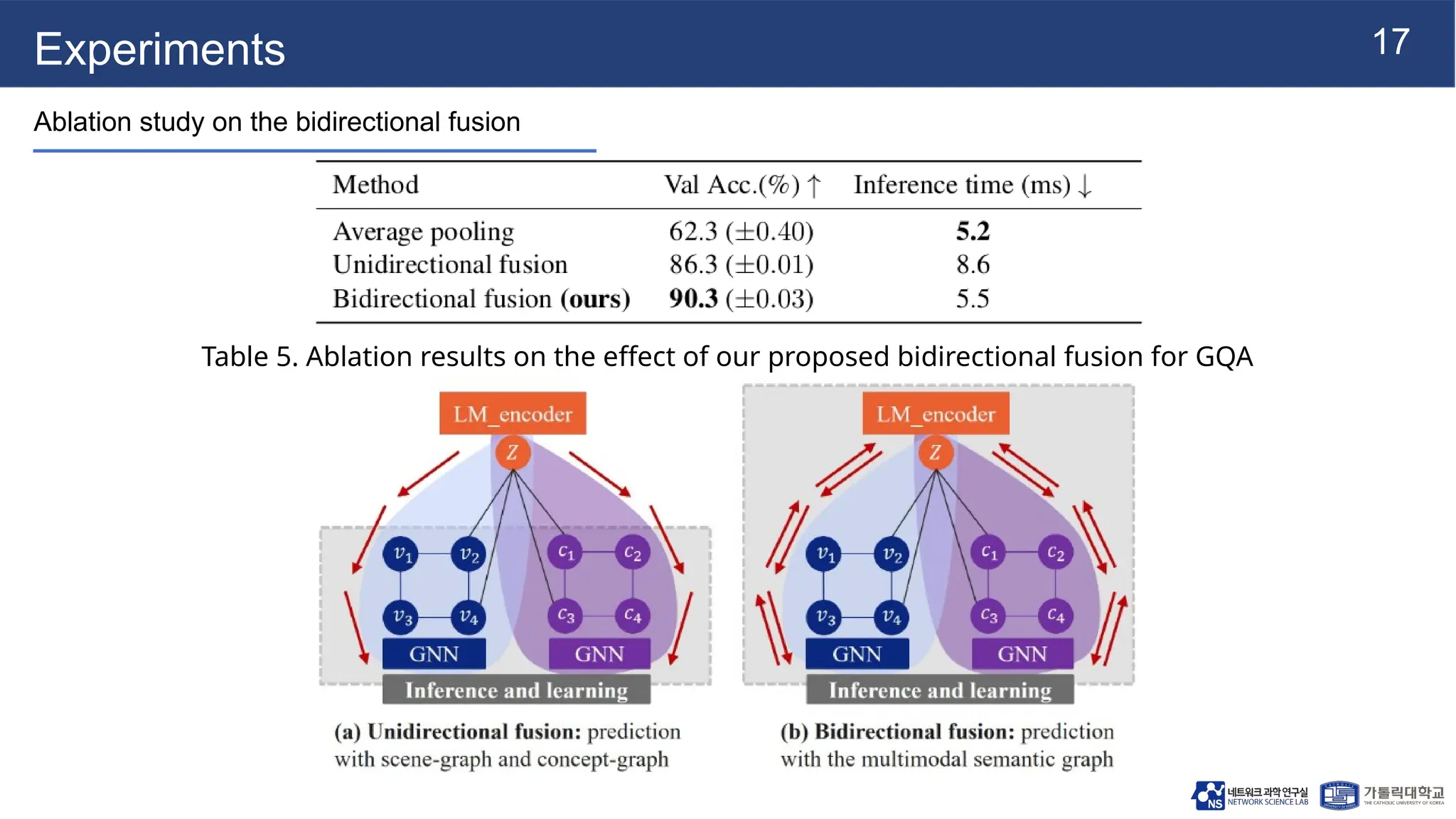
The document presents vqa-gnn, a method that integrates unstructured and structured multimodal knowledge using graph neural networks for visual question answering tasks. It details the construction of multimodal semantic graphs, the application of various graph encodings, and the use of bidirectional fusion to enhance reasoning capabilities. Experimental results indicate that vqa-gnn outperforms traditional VQA methods by significant margins, demonstrating its effectiveness in concept-level reasoning.











![[NS][Lab_Seminar_250224]GraphAdapter.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250224graphadapter-250224130027-8504e9dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_250407]AlignmentLearning.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250407alignmentlearning-250407124309-1acb59f1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_250414]Geometry Sensitive Cross-Modal Reasoning for Composed...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250414gs-ima-250414115119-7dc3e69d-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[NS][Lab_Seminar_251027]From Pixels to Graphs: Open-Vocabulary Scene Graph Ge...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251027pgsg-251027105020-631aebf6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_251110]ControlMLLM.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251110controlmllm-251110090012-39bbf00d-thumbnail.jpg?width=640&height=640&fit=bounds)
![251124_Thanh_LabSeminar[Hyper-YOLO].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124thanhlabseminarhyper-yolo-251124113258-535062b4-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_Thanh_LabSeminar[One Last Attention for Your Vision-Language Model].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thanhlabseminarrada-251103113308-f66fee0b-thumbnail.jpg?width=640&height=640&fit=bounds)
![251124_Thuy_Labseminar[Vision GNN: An Image is Worth Graph of Nodes].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124thuylabseminar-251124113257-025487fe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NS][Lab_Seminar_251020]HyperGLM: HyperGraph for Video Scene Graph Generation...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251020hyperglm-251020095526-46c0e264-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_Thuy_Labseminar[Grounded Language-Image Pre-training].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thuylabseminar-251103113311-941d56eb-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_SH_LabSeminar[Expressiveness of Graph Neural Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103shlabseminarppgn-251103113317-1094e696-thumbnail.jpg?width=640&height=640&fit=bounds)


![251124_HW_LabSeminar[Multimodal-SCM].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124hwlabseminarmultimodal-scm-251124113300-6fad72e4-thumbnail.jpg?width=640&height=640&fit=bounds)

![251110_HW_LabSeminar[WHAT TO ALIGN IN MULTIMODAL CONTRASTIVE LEARNING?].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251110hwlabseminarcomm-251110103747-14b1b798-thumbnail.jpg?width=640&height=640&fit=bounds)
![251027_Thuy_Labseminar[Scaling Language-Image Pre-training via Masking].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251027thuylabseminar-251027105015-a1b9f3e8-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NS][Lab_Seminar_251013]Multimodal Cancer Survival Analysis via Hypergraph Le...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251013mrepath-251013100245-bdfbf8e7-thumbnail.jpg?width=640&height=640&fit=bounds)



















