Download as PDF, PPTX



![Problem Description
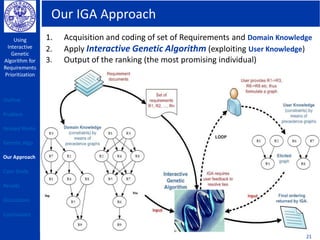
Using
Interactive
Genetic
Algorithm for
Requirements
Prioritization
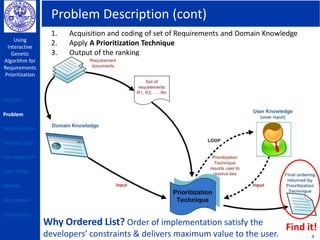
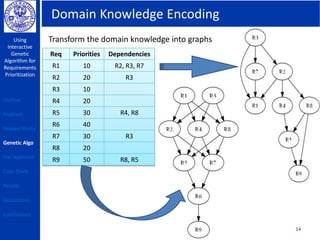
Problem: [Prioritization of Requirements] To find the best ordering of
requirements in each successive release to ensure quality & value of
the delivered system, trade-off constraints & end-user satisfaction. 3
Outline
Problem
Related Works
Genetic Algo
Our Approach
Case Study
Results
Discussions
Conclusions
Do Trade-off between user needs & real constraints
Now, highest quality &
best valued system!](https://image.slidesharecdn.com/francis-160415203753/85/Using-Interactive-Genetic-Algorithm-for-Requirements-Prioritization-3-320.jpg)
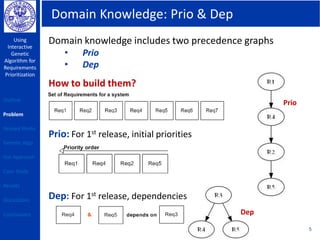




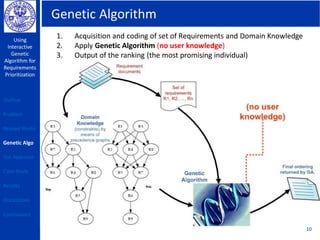

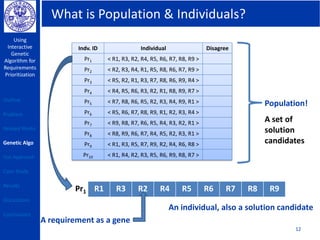

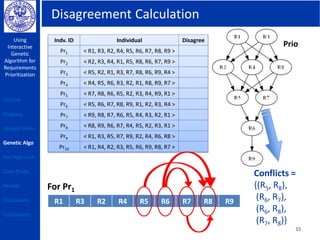
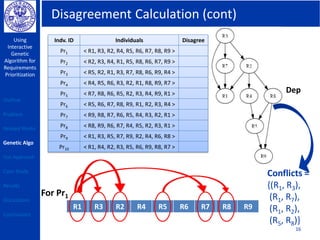

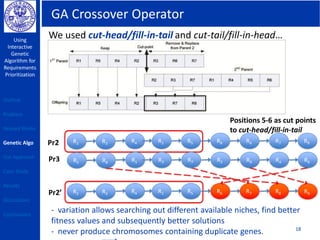


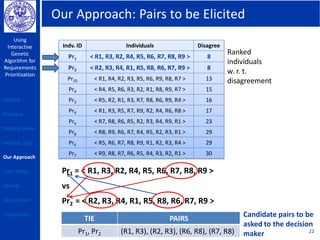
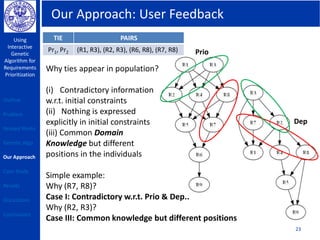
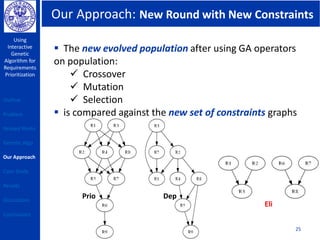




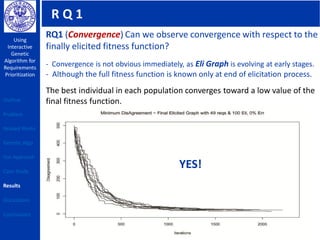
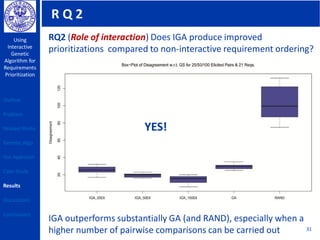
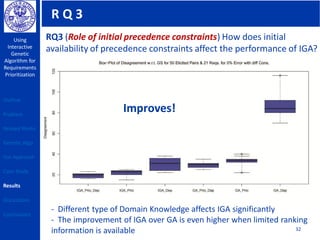





This document describes using a genetic algorithm to prioritize requirements. It begins with an outline and introduction to the problem of prioritizing software requirements. It then discusses related prioritization techniques from literature and how they have limitations like poor scalability. The document proposes using a genetic algorithm to prioritize requirements, leveraging domain knowledge graphs representing priority and dependencies. It describes representing potential solutions as individuals in a population, calculating fitness by counting disagreements with domain knowledge, and using genetic operators like crossover to evolve better solutions over generations. The goal is to find a prioritized requirements list that best satisfies constraints and delivers value to users.









![[WI 2014]Context Recommendation Using Multi-label Classification](https://cdn.slidesharecdn.com/ss_thumbnails/slidewic2014context-140805210546-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













































































