
Recommended
More Related Content
What's hot
Similar to Unit7 jwfiles
Similar to Unit7 jwfiles (20)
More from mrecedu
More from mrecedu (20)
Recently uploaded
Recently uploaded (20)
Unit7 jwfiles
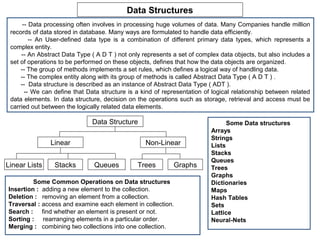
- 1. Data Structures -- Data processing often involves in processing huge volumes of data. Many Companies handle million records of data stored in database. Many ways are formulated to handle data efficiently. -- An User-defined data type is a combination of different primary data types, which represents a complex entity. -- An Abstract Data Type ( A D T ) not only represents a set of complex data objects, but also includes a set of operations to be performed on these objects, defines that how the data objects are organized. -- The group of methods implements a set rules, which defines a logical way of handling data. -- The complex entity along with its group of methods is called Abstract Data Type ( A D T ) . -- Data structure is described as an instance of Abstract Data Type ( ADT ). -- We can define that Data structure is a kind of representation of logical relationship between related data elements. In data structure, decision on the operations such as storage, retrieval and access must be carried out between the logically related data elements. Data Structure Some Data structures Arrays Strings Linear Non-Linear Lists Stacks Queues Linear Lists Stacks Queues Trees Graphs Trees Graphs Some Common Operations on Data structures Dictionaries Insertion : adding a new element to the collection. Maps Deletion : removing an element from a collection. Hash Tables Traversal : access and examine each element in collection. Sets Search : find whether an element is present or not. Lattice Sorting : rearranging elements in a particular order. Neural-Nets Merging : combining two collections into one collection.
- 2. Arrays – Linked Lists What is a Linked List Limitations of Arrays The elements of a linked list are not constrained to 1) Fixed in size : be stored in adjacent locations. The individual Once an array is created, the size of array elements are stored “somewhere” in memory, rather cannot be increased or decreased. like a family dispersed, but still bound together. The 2) Wastage of space : order of the elements is maintained by explicit links If no. of elements are less, leads to wastage of between them. space. 3) Sequential Storage : Array elements are stored in contiguous memory locations. At the times it might so happen that enough contiguous locations might not be available. Even though the total space The Linked List is a collection of elements called requirement of an array can be met through a nodes, each node of which stores two items of combination of non-contiguous blocks of information, i.e., data part and link field. memory, we would still not be allowed to create -- The data part of each node consists the data the array. record of an entity. 4) Possibility of overflow : -- The link field is a pointer and contains the If program ever needs to process more than address of next node. the size of array, there is a possibility of -- The beginning of the linked list is stored in a overflow and code breaks. pointer termed as head which points to the first 5) Difficulty in insertion and deletion : node. In case of insertion of a new element, each -- The head pointer will be passed as a parameter element after the specified location has to be to any method, to perform an operation. shifted one position to the right. In case of -- First node contains a pointer to second node, deletion of an element, each element after the second node contains a pointer to the third node and specified location has to be shifted one position so on. to the left. -- The last node in the list has its next field set to NULL to mark the end of the list.
- 3. struct node { int rollno; struct node *next; Creating a Singly Linked List }; /* deleting n2 node */ int main() { n1->next = n4; struct node *head,*n1,*n2,*n3,*n4; free(n2); /* creating a new node */ } n1=(struct node *) malloc(sizeof(struct node)); n1->rollno=101; 150 101 NULL n1->next = NULL; head 150 n1-node /* referencing the first node to head pointer */ 150 101 720 102 NULL head = n1; 720 150 /* creating a new node */ n1-node n2-node n2=(struct node *)malloc(sizeof(struct node)); 150 101 720 102 910 104 NULL n2->rollno=102; n2->next = NULL; 150 720 910 n1-node n2-node n3-node /* linking the second node after first node */ n1->next = n2; /* creating a new node * / 150 101 400 102 720 104 NULL n3=(struct node *)malloc(sizeof(struct node)); head 150 400 910 n3->rollno=104; n1-node n2-node 103 910 n3-node n3->next=NULL; 720 n4-node /* linking the third node after second node */ n2->next = n3; /* creating a new node */ 150 101 720 103 910 104 NULL n4=(struct node *)malloc (sizeof (struct node)); head 150 720 910 n4->rollno=103; n3-node n1-node n4-node n4->next=NULL; 102 720 /* inserting the new node between 400 second node and third node */ n2-node n2->next = n4;
- 4. Implementing Singly Linked List struct node { } int data; } struct node *next; void insert_after(struct node **h) { }; struct node *new,*temp; int k; struct node *createnode() { if(*h == NULL) return; struct node *new; printf("nEnter data of node after which node : "); new = (struct node *)malloc(sizeof(struct node)); scanf("%d",&k); printf("nEnter the data : "); temp = *h; scanf("%d",&new->data); while(temp!=NULL && temp->data!=k) new->next = NULL; temp = temp->next; return new; if(temp!=NULL) { } new=createnode(); void append(struct node **h) { new->next = temp->next; struct node *new,*temp; temp->next = new; new = createnode(); } if(*h == NULL) { } *h = new; void insert_before(struct node **h) { return; struct node *new,*temp,*prev ; } int k; temp = *h; if(*h==NULL) return; while(temp->next!=NULL) temp = temp->next; printf("nEnter data of node before which node : temp->next = new; "); } scanf("%d",&k); void display(struct node *p) { if((*h)->data == k) { printf("nContents of the List : nn"); new = createnode(); while(p!=NULL) { new->next = *h; printf("t%d",p->data); *h = new; return; p = p->next; } temp = (*h)->next; prev = *h;
- 5. Implementing Singly Linked List ( continued ) while(temp!=NULL && temp->data!=k) { if(temp!=NULL) { prev=temp; prev->next = temp->next; temp=temp->next; free(temp); } } if(temp!=NULL) { } new = createnode(); void search(struct node *h) { new->next = temp; struct node *temp; prev->next = new; int k; } if(h==NULL)return; } printf("nEnter the data to be searched : "); void delnode(struct node **h) { scanf("%d",&k); struct node *temp,*prev; temp=h; int k; while(temp!=NULL && temp->data!=k) if(*h==NULL) return; temp=temp->next; printf("nEnter the data of node to be removed : "); (temp==NULL)? scanf("%d",&k); printf("nt=>Node does not exist") : if((*h)->data==k) { printf("nt=>Node exists"); temp=*h; } *h=(*h)->next; void destroy(struct node **h) { free(temp); struct node *p; return; if(*h==NULL) return; } while(*h!=NULL) { temp=(*h)->next; p = (*h)->next; prev=*h; free(*h); while(temp!=NULL && temp->data!=k) { *h=p; prev=temp; } temp=temp->next; printf("nn ******Linked List is destroyed******"); } }
- 6. Implementing Singly Linked List ( continued ) int main() { /* function to sort linked list */ struct node *head=NULL; void sort(struct node *h) { int ch; struct node *p,*temp; while(1) { int i, j, n, t, sorted=0; printf("n1.Append"); temp=h; printf("n2.Display All"); for(n=0 ; temp!=NULL ; temp=temp->next) n++; printf("n3.Insert after a specified node"); for(i=0;i<n-1&&!sorted;i++) { printf("n4.Insert before a specified node"); p=h; sorted=1; printf("n5.Delete a node"); for(j=0;j<n-(i+1);j++) { printf("n6.Search for a node"); if ( p->data > ( p->next )->data ) { printf("n7.Distroy the list"); t=p->data; printf("n8.Exit program"); p->data =(p->next)->data; printf("nntEnter your choice : "); (p->next)->data = t; scanf("%d",&ch); sorted=0; switch(ch) { } case 1:append(&head);break; p=p->next; case 2:display(head);break; } case 3:insert_after(&head);break; } case 4:insert_before(&head);break; } case 5:delnode(&head);break; case 6:search(head);break; /* function to count number of node in the list */ case 7:destroy(&head);break; int count ( struct node *h) case 8:exit(0);break; { default : int i; printf( "Wrong Choice, Enter correct one : "); for( i=0 ; h!=NULL ; h=h->next) } i++; } return i; } }
- 7. Algorithm for adding two polynomials in linked lists Add_Polynomial( list p, list q ) set p, q to point to the two first nodes (no headers) initialize a linked list r for a zero polynomial while p != null and q != null if p.exp > q.exp create a node storing p.coeff and p.exp insert at the end of list r advance p else if q.exp > p.exp create a node storing q.coeff and q.exp insert at the end of list r advance q else if p.exp == q.exp if p.coeff + q.coeff != 0 create a node storing p.coeff + q.coeff and p.exp insert at the end of list r advance p, q end while if p != null copy the remaining terms of p to end of r else if q != null copy the remaining terms of q to end of r
- 8. Doubly Linked List Pitfalls encountered while using singly linked list : 1) A singly linked list allows traversal of the list in forward direction, but not in backward direction. 2) Deleting a node from a list requires keeping track of the previous node,. 3) In the list any node gets corrupted, the remaining nodes of the list become unusable. These problems of singly linked lists can be overcome by doubly linked list. A Doubly Linked List is a data structure having an ordered list of nodes, in which each node consists of two pointers. One pointer is to store the address of next node like in singly linked list. The second pointer stores the address of previous node. It is also known as two-way list. The specialty of DLL is that the list can be traversed in forward as well as backward directions. The concept of DLL is also used to representing tree data structures. head tail A B C /* a node in doubly linked list */ struct node B { struct node *prev; A D int data ; struct node *next; C } Tree structure using Doubly Linked List
- 9. Insertion of node in Doubly Linked List q A B D C p q A B C D Deletion of node in Doubly Linked List A B C p D A B C
- 10. Implementing Doubly Linked List struct node { void forward_display(struct node *p) struct node *prev; { int data; printf("nContents of the List : nn"); struct node *next; while(p!=NULL) }; { struct node *createnode() { printf("t%d",p->data); struct node *new; p = p->next; new = (struct node *)malloc(sizeof(struct node)); } printf("nEnter the data : "); printf("n"); scanf("%d",&new->data); } new->prev = NULL; void insert_after(struct node **h) { new->next = NULL; struct node *new,*temp; return new; int k; } if(*h == NULL) return; void append(struct node **h) { printf("nEnter data of node after which node : "); struct node *new,*temp; scanf("%d",&k); new = createnode(); temp = *h; if(*h == NULL) while(temp!=NULL && temp->data!=k) { temp = temp->next; *h = new; if(temp!=NULL) { return; new=createnode(); } new->next = temp->next; temp = *h; temp->next = new; while(temp->next!=NULL) new->prev = temp; temp = temp->next; if(new->next != NULL) temp->next = new; new->next->prev = new; new->prev = temp; } } }
- 11. Implementing Doubly Linked List ( continued ) void insert_before(struct node **h) void delnode(struct node **h) { { struct node *new,*temp; struct node *temp; int k; int k; if(*h==NULL) return; if(*h==NULL) printf("nEnter data of node before which node : "); return; scanf("%d",&k); printf("nEnter the data of node to be removed : "); if((*h)->data == k) { scanf("%d",&k); new = createnode(); if((*h)->data==k) new->next = *h; { new->next->prev=new; temp=*h; *h = new; *h=(*h)->next; return; (*h)->prev=NULL; } free(temp); temp = *h; return; while(temp!=NULL && temp->data!=k) } { temp=*h; temp=temp->next; while(temp!=NULL && temp->data!=k) } { if(temp!=NULL) temp=temp->next; { } new = createnode(); if(temp!=NULL) new->next = temp; { new->prev = temp->prev; temp->next->prev = temp->prev; new->prev->next = new; temp->prev->next = temp->next; temp->prev = new; free(temp); } } } }
- 12. Implementing Doubly Linked List ( continued ) void search(struct node *h) int main() { { struct node *head=NULL; struct node *temp; int ch; int k; while(1) { if(h==NULL) printf("n1.Append"); return; printf("n2.Display All"); printf("nEnter the data to be searched : "); printf("n3.Insert after a specified node"); scanf("%d",&k); printf("n4.Insert before a specified node"); temp=h; printf("n5.Delete a node"); while(temp!=NULL && temp->data!=k) printf("n6.Search for a node"); temp=temp->next; printf("n7.Distroy the list"); if (temp==NULL) printf("n8.Exit program"); printf("nt=>Node does not exist") printf("nntEnter your choice : "); else scanf("%d",&ch); printf("nt=>Node exists"); switch(ch) { } case 1:append(&head);break; void destroy(struct node **h) case 2:forward_display(head);break; { case 3:insert_after(&head);break; struct node *p; case 4:insert_before(&head);break; if(*h==NULL) return; case 5:delnode(&head);break; while(*h!=NULL) case 6:search(head);break; { case 7:destroy(&head);break; p = (*h)->next; case 8:exit(0);break; free(*h); default : *h=p; printf("Wrong Choice, Enter correct choice : } "); printf("nn ******Linked List is destroyed******"); } } } }
- 13. 910 101 400 102 720 103 910 104 150 Circular Singly tail Linked List 150 400 720 910 n1-node n2-node n3-node n4-node -- Singly Linked List has a major drawback. From a specified node, it is not possible to reach any of the preceding nodes in the list. To overcome the drawback, a small change is made to the SLL so that the next field of the last node is pointing to the first node rather than NULL. Such a linked list is called a circular linked list. -- Because it is a circular linked list, it is possible to reach any node in the list from a particular node. -- There is no natural first node or last node because by virtue of the list is circular. -- Therefore, one convention is to let the external pointer of the circular linked list, tail, point to the last node and to allow the following node to be the first node. -- If the tail pointer refers to NULL, means the circular linked list is empty. Circular Doubly Linked List prev data next prev data next prev data next prev data next -- A Circular Doubly Linked List ( CDL ) is a doubly linked list with first node linked to last node and vice-versa. -- The ‘ prev ’ link of first node contains the address of last node and ‘ next ’ link of last node contains the address of first node. -- Traversal through Circular Singly Linked List is possible only in one direction. -- The main advantage of Circular Doubly Linked List ( CDL ) is that, a node can be inserted into list without searching the complete list for finding the address of previous node. -- We can also traversed through CDL in both directions, from first node to last node and vice-versa.
- 14. Implementing Circular Singly Linked List struct node { void insert_after(struct node **t) int data; struct node *next; { }; struct node *new,*temp; struct node *createnode() { int k, found=0; struct node *new; if(*t == NULL) return; new = (struct node *)malloc(sizeof(struct node)); printf("nEnter data of node after which node : "); printf("nEnter the data : "); scanf("%d",&k); scanf("%d",&new->data); if((*t)->data==k) new->next = NULL; { return new; new = createnode(); } new->next = (*t)->next; void append(struct node **t) { (*t)->next = new; struct node *new,*head; *t=new; new = createnode(); return; if(*t == NULL) { } *t = new; new->next = *t; temp=(*t)->next; return; while(temp!=*t) } { head = (*t)->next; (*t)->next = new; if(temp->data == k) { new->next = head; *t = new; new = createnode(); } new->next = temp->next; void display(struct node *t) { temp->next = new; struct node *temp = t->next, *head=t->next; found=1; printf("nContents of the List : nn"); break; do { } printf("t%d",temp->data);temp = temp->next; temp=temp->next; }while(temp!=head); } printf(“n”); if(found==0) printf("nNode does not exist.."); } }
- 15. Implementing Circular Singly Linked List ( continued ) void insert_before(struct node **t) { void delnode(struct node **t) { struct node *new,*temp,*prev,*head; struct node *temp,*prev,*head; int k,found=0; int k,found=0; if(*t==NULL) return; if(*t==NULL) return; printf("nEnter data of node before which node : printf("nEnter the data of node to be removed : "); "); scanf("%d",&k); scanf("%d",&k); head=(*t)->next; head=(*t)->next; if(head->data == k) { if(head->data==k) { new = createnode(); temp=head; new->next = head; if(temp->next!=head) (*t)->next=head->next; (*t)->next = new; else *t = NULL; return; free(temp); } return; temp = head->next; } prev = head; temp=head->next; prev=head; while(temp!=head) { while(temp!=head) { if(temp->data==k) { if(temp->data == k) { new = createnode(); prev->next = temp->next; prev->next = new; if(temp==*t) *t = prev; new->next = temp; free(temp); found=1; found=1; break; break; } else { } else { prev=temp; prev=temp; temp=temp->next; temp=temp->next; } } } } if(found==0) printf("nNode does not exist.."); if(found==0) printf("nNode does not exist..");
- 16. Implementing Circular Singly Linked List ( continued ) int main() { struct node *tail=NULL; Types of Data Structures int ch; while(1) { printf("n1.Append"); Data structures are classified in several ways : printf("n2.Display All"); Linear : Elements are arranged in sequential printf("n3.Insert after a specified node"); fashion. Ex : Array, Linear list, stack, queue printf("n4.Insert before a specified node"); Non-Linear : Elements are not arranged in printf("n5.Delete a node"); sequence. Ex : trees, graphs printf("n6.Exit program"); Homogenous : All Elements are belongs to same printf("nntEnter your choice : "); data type. Ex : Arrays scanf("%d",&ch); Non-Homogenous : Different types of Elements switch(ch) are grouped and form a data structure. Ex: { classes case 1:append(&tail);break; Dynamic : Memory allocation of each element in case 2:display(tail);break; the data structure is done before their usage case 3:insert_after(&tail);break; using D.M.A functions Ex : Linked Lists case 4:insert_before(&tail);break; Static : All elements of a data structure are case 5:delnode(&tail);break; created at the beginning of the program. They case 6:exit(0);break; cannot be resized. Ex : Arrays default : printf(“ntWrong Choice… “); } } }
- 17. Stacks -- Stack is an ordered collection of data elements into which new elements may be inserted and from which elements may be deleted at one end called the “TOP” of stack. -- A stack is a last-in-first-out ( LIFO ) structure. -- Insertion operation is referred as “PUSH” and deletion operation is referred as “POP”. -- The most accessible element in the stack is the element at the position “TOP”. -- Stack must be created as empty. -- Whenever an element is pushed into stack, it must be checked whether the stack is full or not. -- Whenever an element is popped form stack, it must be checked whether the stack is empty or not. -- We can implement the stack ADT either with array or linked list. Stack ADT Applications of stack struct stackNode { int data; struct stackNode *next; Reversing Data series }; Conversion decimal to binary init_stack( ) Parsing into tokens push ( ) Backtracking the operations pop ( ) Undo operations in Text Editor isEmpty ( ) Page visited History in web browser display ( ) Tracking of Function calls peek ( ) Maintaining scope and lifetime of local variables in functions Infix to postfix conversion Evaluating postfix expression
- 18. Push(a) Push(b) Push(c) Pop( ) Push(d) Push(e) Pop( ) Pop( ) Pop( ) Pop( ) e c d d d b b b b b b b a a a a a a a a a Operations on Stack Operation Stack’s contents TOP value Output 1. Init_stack( ) <empty> -1 2. Push( ‘a’ ) a 0 3. Push( ‘b’ ) ab 1 4. Push( ‘c’ ) abc 2 5. Pop( ) ab 1 c 6. Push( ‘d’ ) abd 2 c 7. Push( ‘e’ ) abde 3 c 8. Pop( ) abd 2 ce 9. Pop( ) ab 1 ced 10. Pop( ) a 0 cedb 11. Pop( ) <empty> -1 cedba
- 19. Implementing Stack ADT using Array #define SIZE 50 int main() { int stack[SIZE]; int top; int choice,item; void init_stack() { init_stack(); top=-1; do } { void push( int n ) { printf("ntttMenunt1.Push.nt2.Pop."); if( top==SIZE-1) printf("nStack is full"); printf("nt3.Peek.nt4.Display.nt5.Exit.n"); else stack[++top]= n; printf("nYour Choice: "); } scanf("%d",&choice); int pop( ) { switch(choice) if(top== -1) { { printf("nStack is empty"); case 1:printf("nEnter the element to push : return -1; "); } else return stack[top--]; scanf("%d",&item); } push(item); break; void display( ) { case 2:item = pop(); int i; printf("nElement poped : %d",item); if(top== -1) printf("nStack is empty."); printf("nPress a key to continue..."); else { getche(); break; printf("nElements are : n"); case 3:item = peek(); for(i=0;i<=top;i++) printf("nElement at top : %d",item); printf("%5d ",stack[i]); printf("nPress a key to continue..."); } } getche(); break; int isEmpty( ) { case 4:display(); if ( top== -1 ) return 1; printf("nPress a key to continue..."); else return 0; getche(); break; } case 5:exit(0); int peek( ){ return stack[top]; } }
- 20. Implementing Stack ADT using Linked List struct s_node { while(temp!=NULL) { int data; printf("%dt",temp->data); struct s_node *link; temp=temp->link; } *stack; } void push(int j) { } struct s_node *m; void main() { m=(struct s_node*)malloc(sizeof(struct s_node)); int choice,num,i; m->data= j ; m->link=stack; while(1) { stack=m; return; printf("ntt MENUn1. Pushn2. Popn3. Peek"); } printf("n4. Elements in Stackn5. Exitn"); int pop( ) { printf("ntEnter your choice: "); struct s_node *temp=NULL; scanf("%d",&choice); if(stack==NULL) { switch(choice) { printf("nSTACK is Empty."); getch(); case 1: printf("nElement to be pushed:"); } else { scanf("%d",&num); int i=stack->data; push(num); break; temp = stack ; stack=stack->link; case 2: num=pop(); free(temp); return (i); printf("nElement popped: %d ",num); } getch(); break; } case 3: num=peek(); int peek( ) { printf("nElement peeked : %d ",num); if(stack==NULL) { getch(); break; printf("nSTACK is Empty."); getch(); case 4: printf("nElements present in stack : “ ): } else display();getch(); break; return (stack->data); case 5: exit(1); } default: printf("nInvalid Choicen"); break; void display() { } struct s_node *temp=stack; } }
- 21. Queues -- Queue is a linear data structure that permits insertion of new element at one end and deletion of an element at the other end. -- The end at which insertion of a new element can take place is called ‘ rear ‘ and the end at which deletion of an element take place is called ‘ front ‘. -- The first element that gets added into queue is the first one to get removed from the list, Hence Queue is also referred to as First-In-First-Out ( FIFO ) list. -- Queue must be created as empty. -- Whenever an element is inserted into queue, it must be checked whether the queue is full or not. -- Whenever an element is deleted form queue, it must be checked whether the queue is empty or not. -- We can implement the queue ADT either with array or linked list. Queue ADT 4 rear front struct queueNode { int data; struct queueNode *next; 3 6 8 2 5 }; init_queue( ) addq (4) delq ( ) addq ( ) 7 delq ( ) isEmpty ( ) printQueue ( ) Applications of Queues Types of Queues Execution of Threads Job Scheduling circular queues Event queuing priority queues Message Queueing double-ended queues
- 22. Implementing Queue ADT using Array int queue[10] ,front, rear ; printf("nElements are : n"); void init_queue() { for (i=front;i<=rear;i++) front = rear = -1 ; printf("%5d",queue[i]); } } void addq ( int item ){ } if ( rear == 9 ) { int main() { printf("nQueue is full"); int ch,num; return ; init_queue(); } do rear++ ; { queue [ rear ] = item ; printf("ntMENUnn1. Add to Queue”); if ( front == -1 )front = 0 ; printf(“n2. Delete form Queue"); } printf("n3. Display Queuen4. Exit."); int delq( ){ printf("nntYour Choice: "); int data ; scanf("%d",&ch); if ( front == -1 ) { switch(ch) printf("nQueue is Empty"); { return 0; case 1: printf("nEnter an element : "); } scanf("%d",&num); data = queue[front] ; addq(num);break; queue[front] = 0 ; case 2: num=delq(); if ( front == rear ) front = rear = -1 ; printf("nElement deleted : %d",num); else front++ ; break; return data ; case 3: display(); break; } case 4: exit(0); void display() { default: printf("nInvalid option.."); int i; } if(front==-1) printf("nQueue is empty."); }while(1); else { }
- 23. Implementing Queue ADT using Liked List struct q_node { else { int data; struct q_node *next; printf("nElements in Queue :n"); }*rear,*front; while(temp!=NULL) { void init_queue() { printf("%5d",temp->data); rear=NULL; front=NULL; temp=temp->next; } } void addq(int item) { } struct q_node *t; } t=(struct q_node*)malloc(sizeof(struct q_node)); int main() { t->data=item; t->next=NULL; int ch,num; if(front==NULL) rear=front=t; init_queue(); else { do { rear->next=t; rear=rear->next; printf("ntMENUnn1. Addn2. Delete"); } printf("n3. Display Queuen4. Exit."); } printf("nntYour Choice: "); int delq() { scanf("%d",&ch); struct q_node *temp; switch(ch) { if(front==NULL) { case 1: printf("nEnter an element : "); printf("nQueue is empty."); return 0; scanf("%d",&num); } else { addq(num);break; int num = front->data; case 2: num=delq(); temp = front; front=front->next; printf("nElement deleted : %d",num); break; free(temp); return num; case 3: display(); break; } case 4: exit(0); } default:printf("nInvalid option.."); void display() { } struct q_node *temp=front; }while(1); if(front==NULL) printf("nQueue is empty."); }
- 24. --Arithmetic Expressions are represented using three notations infix, prefix and postfix. The prefixes ‘pre’, ‘post’, and ‘in’ refer to position of operators with respect to two operands. -- In infix notation, the operator is placed between the two operands. Ex: A + B A*B+C (A * B) + (C * D) -- In Prefix notation, the operator is placed before the two operands. Ex: +AB *A+BC +*AB*CD -- In Postfix notation, the operator is placed after the two operands. Ex: AB+ ABC+* AB*CD*+ Algorithm to Infix to Postfix Conversion In-To-Post ( infix-expression ) Scan the Infix expression left to right If the character x is an operand Output the character into the Postfix Expression If the character x is a left or right parenthesis If the character is “( Push it into the stack If the character is “)” Repeatedly pop and output all the operators/characters until “(“ is popped from the stack. If the character x is a is a regular operator Check the character y currently at the top of the stack. If Stack is empty or y is ‘(‘ or y is an operator of lower precedence than x, then Push x into stack. If y is an operator of higher or equal precedence than x, Pop and output y and push x into the stack. When all characters in infix expression are processed repeatedly pop the character(s) from the stack and output them until the stack is empty.
- 25. In-Fix To Post-Fix convertion #define STACKSIZE 20 y=pop(&s) ; typedef struct { while(y != '(') { int top; char items[STACKSIZE]; printf("%c",y); }STACK; y=pop(&s) ; /*pushes ps into stack*/ } void push(STACK *sptr, char ps) { } else { if(sptr->top == STACKSIZE-1) { if(s.top ==-1 || s.items[s.top] == '(') printf("Stack is fulln"); exit(1); push(&s ,x); } else else { sptr->items[++sptr->top]= ps; /* y is the top operator in the stack*/ } y = s.items[s.top]; char pop(STACK *sptr) { /* precedence of y is higher/equal to x*/ if(sptr->top == -1) { if( y=='*' || y=='/'){ printf("Stack is emptyn"); exit(1); printf("%c", pop(&s)); } else push(&s ,x); return sptr->items[sptr->top--]; } else if ( y=='+' || y=='-') } /* precedence of y is equal to x*/ int main() { if( x=='+' || x=='-') { int i; STACK s; char x, y, E[20] ; printf("%c", pop(&s)); s.top = -1; /* Initialize the stack is */ push(&s ,x); printf("Enter the Infix Expression:"); } scanf("%s",E); /* precedence of y is less than x*/ for(i=0;E[i] != '0';i++) { else x= E[i]; push(&s ,x); /* Consider all lowercase letter } from a to z are operands */ } if(x<='z' && x>='a') printf("%c",x); } else if(x == '(') push(&s ,x); while(s.top != -1) printf("%c",pop(&s)); else if( x == ')‘ ){ }
- 26. Evaluation of Post-Fix Expression #include<stdio.h> case '*':push(op1*op2);break; #include<ctype.h> case '/':push(op1/op2);break; #include<math.h> case '^':push(pow(op1,op2)); float stack[10]; break; int top=-1; } void push(char c) } { j++; stack[++top]=c; } } return pop(); float pop() { } float n; int main() { n=stack[top--]; int j=0; return (n); char expr[20]; } float number[20],result; float evaluate(char expr[], float data[]) printf("nEnter a post fix expression : "); { gets(expr); int j=0; while(expr[j]!='0') float op1=0,op2=0; { char ch; if(isalpha(expr[j])) while(expr[j]!='0') { { ch = expr[j]; fflush(stdin); if(isalpha(expr[j])) { printf("nEnter number for %c : ",expr[j]); push(data[j]); scanf("%f",&number[j]); } else { } op2=pop(); j++; op1=pop(); } switch(ch) { result = evaluate(expr,number); case '+':push(op1+op2);break; printf("nThe result of %s is %f",expr,result); case '-':push(op1-op2);break; }
- 27. www.jntuworld.com • For More Materials, Text Books, Previous Papers & Mobile updates of B.TECH, B.PHARMACY, MBA, MCA of JNTU-HYD,JNTU- KAKINADA & JNTU-ANANTAPUR visit www.jntuworld.com