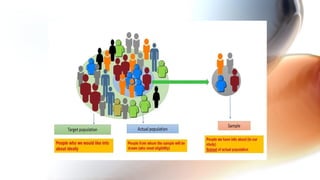
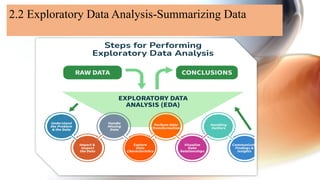
The document presents an overview of data science focusing on statistical inference and exploratory data analysis (EDA), emphasizing their importance in understanding data characteristics, patterns, and relationships. Key aspects of EDA include data distribution analysis, outlier detection, correlation analysis, and handling missing values, often employing Python libraries like Pandas and Matplotlib. The document outlines systematic steps for conducting EDA, including data inspection, transformation, visualization, and effective communication of insights.