Download to read offline





































![*Secret-key cryptography is often referred to as symmetric
cryptography, whereas public-key cryptography is referred to as
asymmetric because the keys used for encryption and decryption are
different.
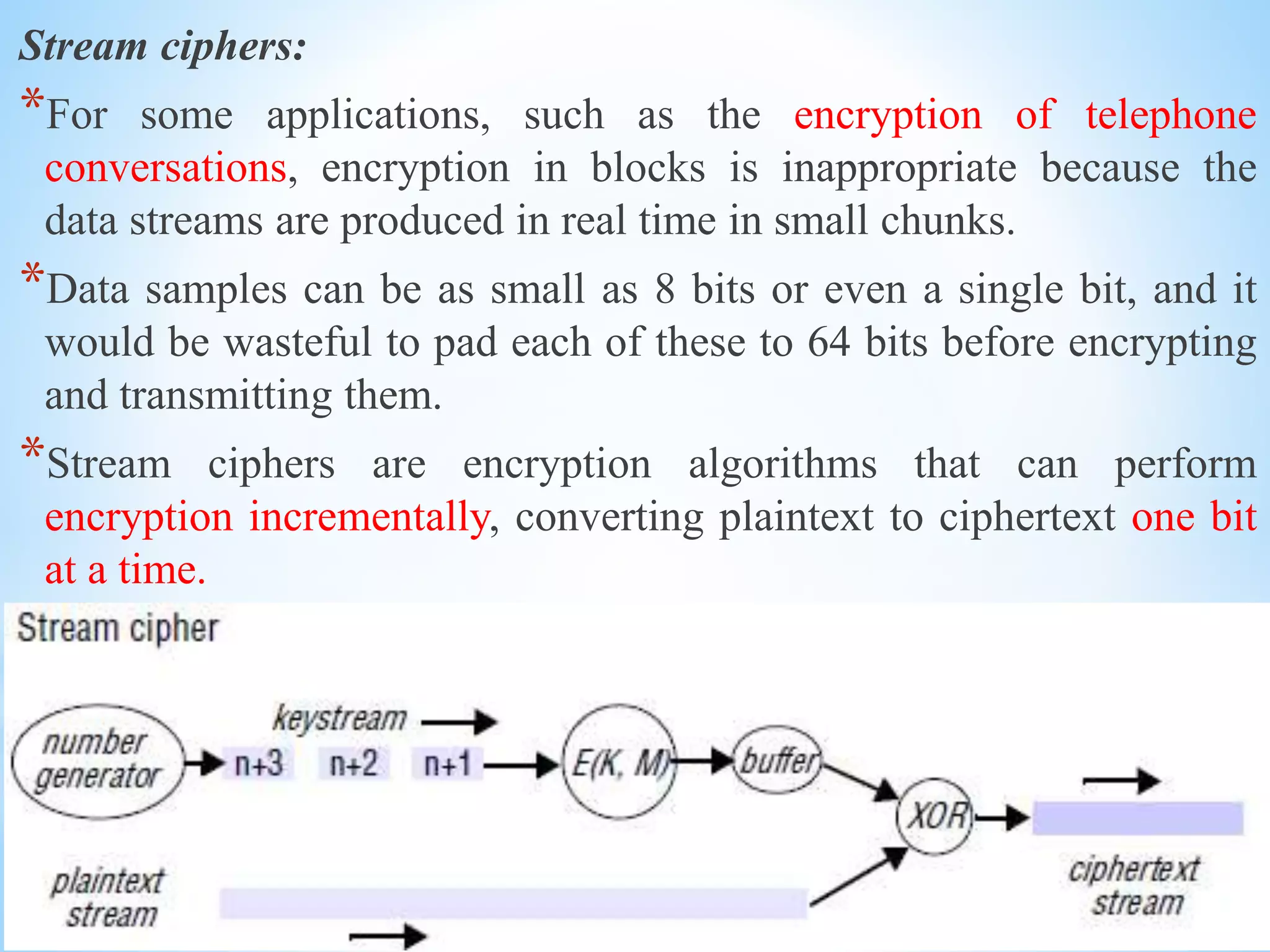
Symmetric algorithms:
*If we remove the key parameter from consideration by defining
FK([M]) = E(K,M) , then it is a property of strong encryption
functions that FK([M]) is relatively easy to compute, whereas the
inverse, FK
–1([M]) , is so hard to compute that it is not feasible.
Such functions are known as one-way functions.
*The brute force approach is to run through all possible values of K,
computing E (K, M) until the result matches the value of {M}K that
is already known.
*If K has N bits then such an attack requires 2 N – 1 iterations on
average, and a maximum of 2N iterations, to find K. Hence the time
to crack K is exponential in the number of bits in K.](https://image.slidesharecdn.com/unitivdis-230802171825-1aa0ff31/75/UNIT-IV-DIS-pptx-39-2048.jpg)
![Asymmetric algorithms:
*When a public/private key pair is used, one-way functions are
exploited in another way.
*The feasibility of a public-key scheme was first proposed by Diffie
and Hellman [1976] as a cryptographic method that eliminates the
need for trust between the communicating parties.
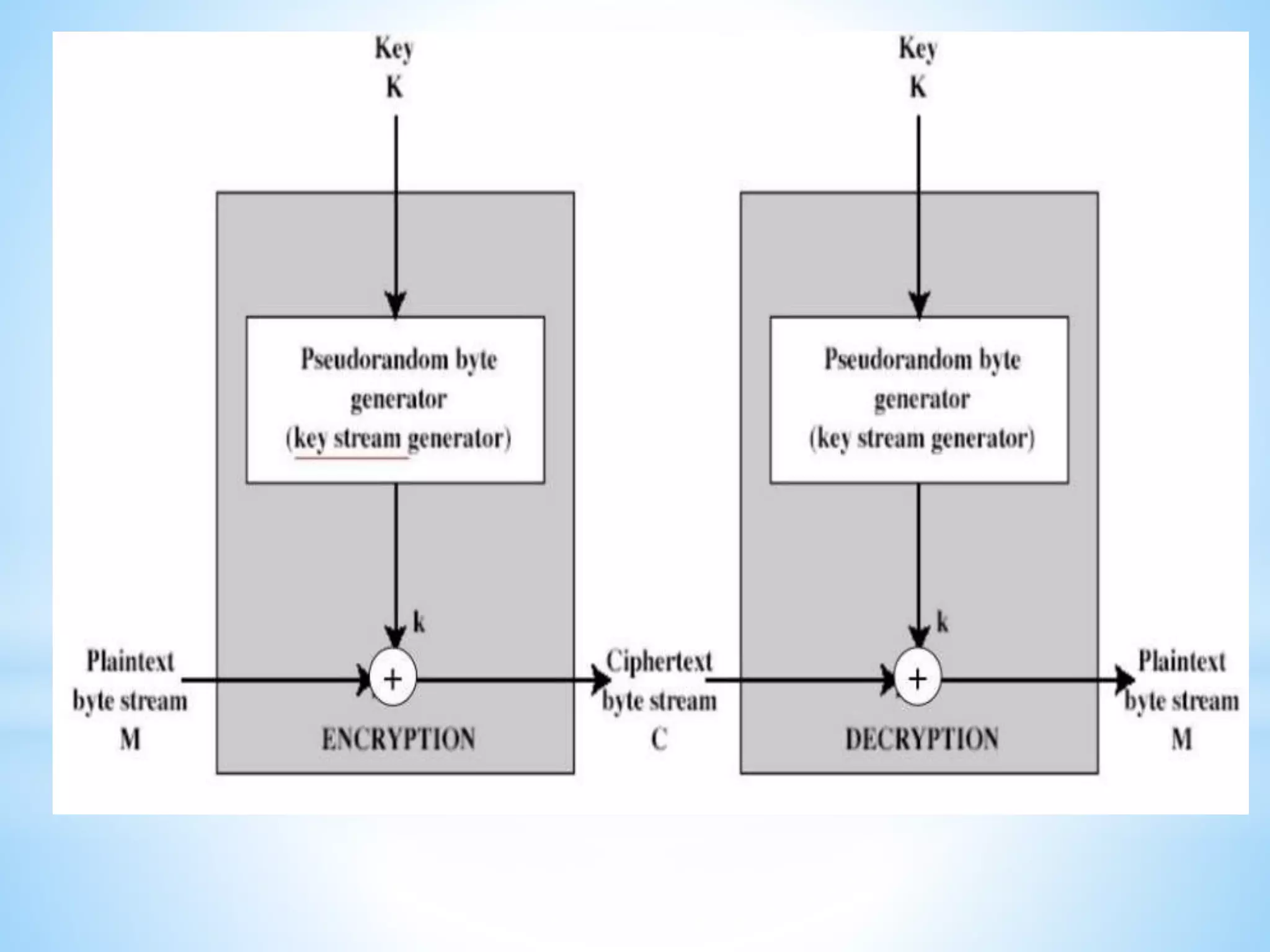
Block ciphers:
*Most encryption algorithms operate on fixed-size blocks of data; 64
bits is a popular size for the blocks.
*A message is subdivided into blocks, the last block is padded to the
standard length if necessary and each block is encrypted
independently.
*The first block is available for transmission as soon as it has been
encrypted.](https://image.slidesharecdn.com/unitivdis-230802171825-1aa0ff31/75/UNIT-IV-DIS-pptx-40-2048.jpg)

![Tiny Encryption Algorithm:
*The TEA algorithm uses rounds of integer addition, XOR (the ^ operator) and
bitwise logical shifts (<< and >>) to achieve diffusion and confusion of the
bit patterns in the plaintext.
*The plaintext is a 64-bit block represented as two 32-bit integers in the vector
text[]. The key is 128 bits long, represented as four 32-bit integers.
*The decryption function is the inverse of that for encryption.](https://image.slidesharecdn.com/unitivdis-230802171825-1aa0ff31/75/UNIT-IV-DIS-pptx-44-2048.jpg)


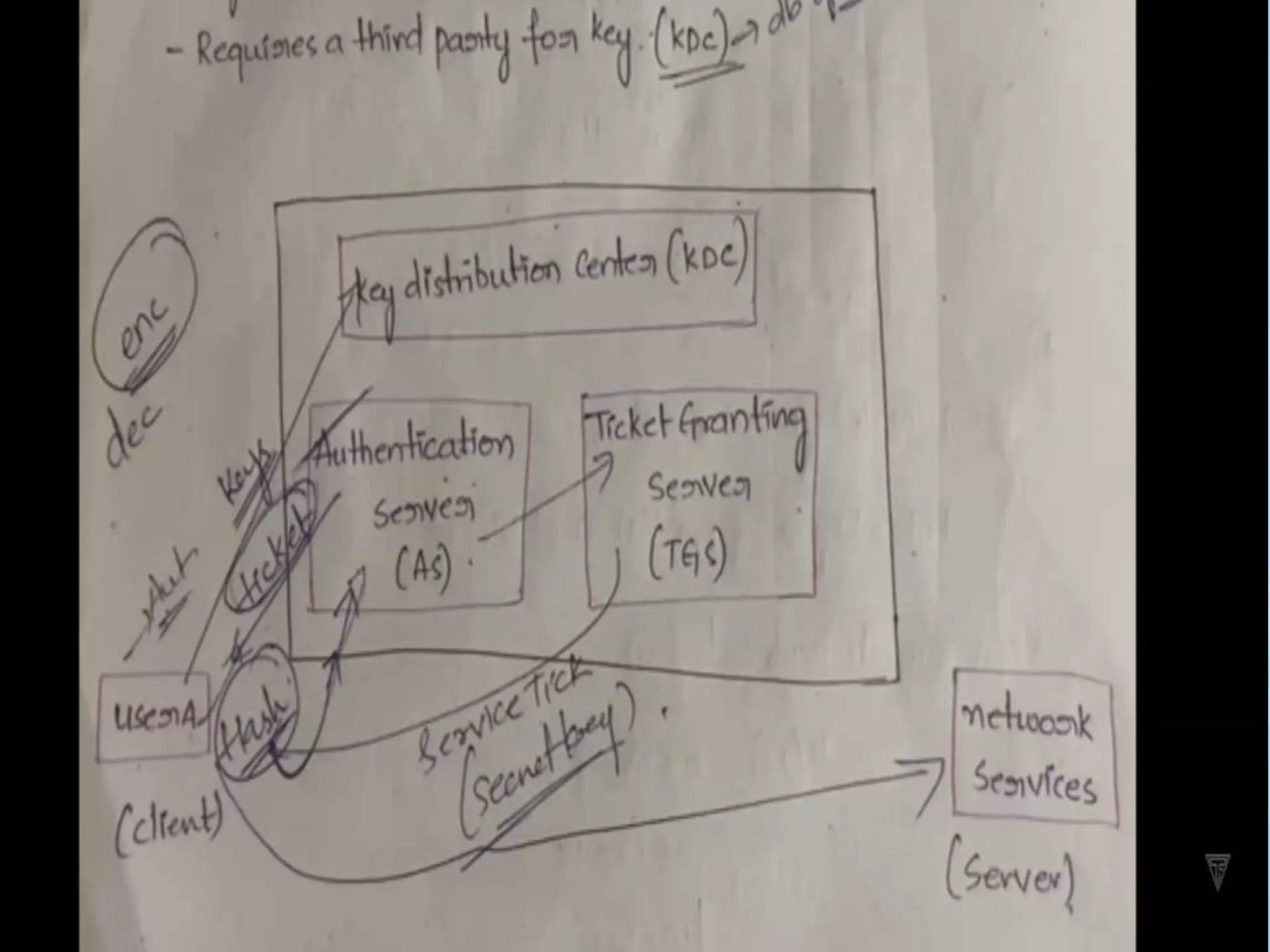

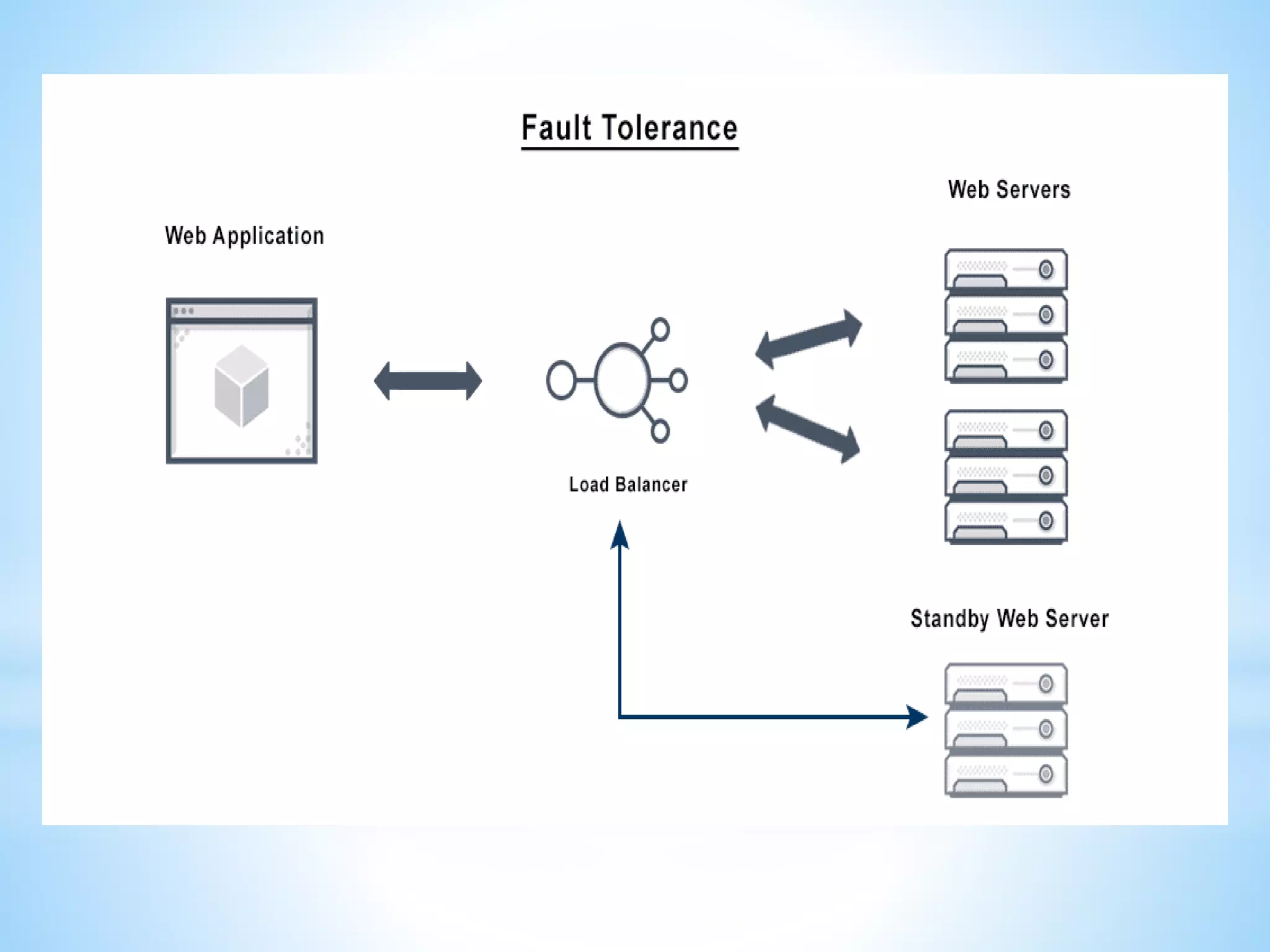
This document provides an overview of fault tolerance and security techniques. It discusses fault tolerance services including passive and active replication models. It covers atomic commit protocols, concurrency control, distributed deadlocks, and transaction recovery methods like two-phase commit. It also summarizes security techniques such as access control, cryptography algorithms, and the Kerberos authentication system.
























































