The document presents a study on Unbiased Markov Chain Monte Carlo (MCMC) methods, focusing on a proposed methodology involving coupled chains to achieve unbiased estimators for Bayesian inference. It discusses the implementation of MCMC algorithms, specifically the Metropolis-Hastings method, and highlights the importance of maximizing coupling to improve efficiency and reduce bias. Additionally, the paper includes applications in neuroscience, showcasing its relevance in estimating parameters using particle filters and controlled sequential Monte Carlo methods.

![Setting
• Target distribution
⇡(dx) = ⇡(x)dx, x 2 Rd
• For Bayesian inference, target is the posterior distribution of
parameters x given data y
⇡(x) = p(x|y) / p(x)
|{z}
prior
p(y|x)
| {z }
likelihood
• Objective: compute expectation
E⇡ [h(X)] =
Z
Rd
h(x)⇡(x)dx
for some test function h : Rd ! R
• Monte Carlo method: sample X0, . . . , XT ⇠ ⇡ and compute
1
T + 1
TX
t=0
h(Xt) ! E⇡ [h(X)] as T ! 1
Jeremy Heng Unbiased MCMC 2/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-2-2048.jpg)
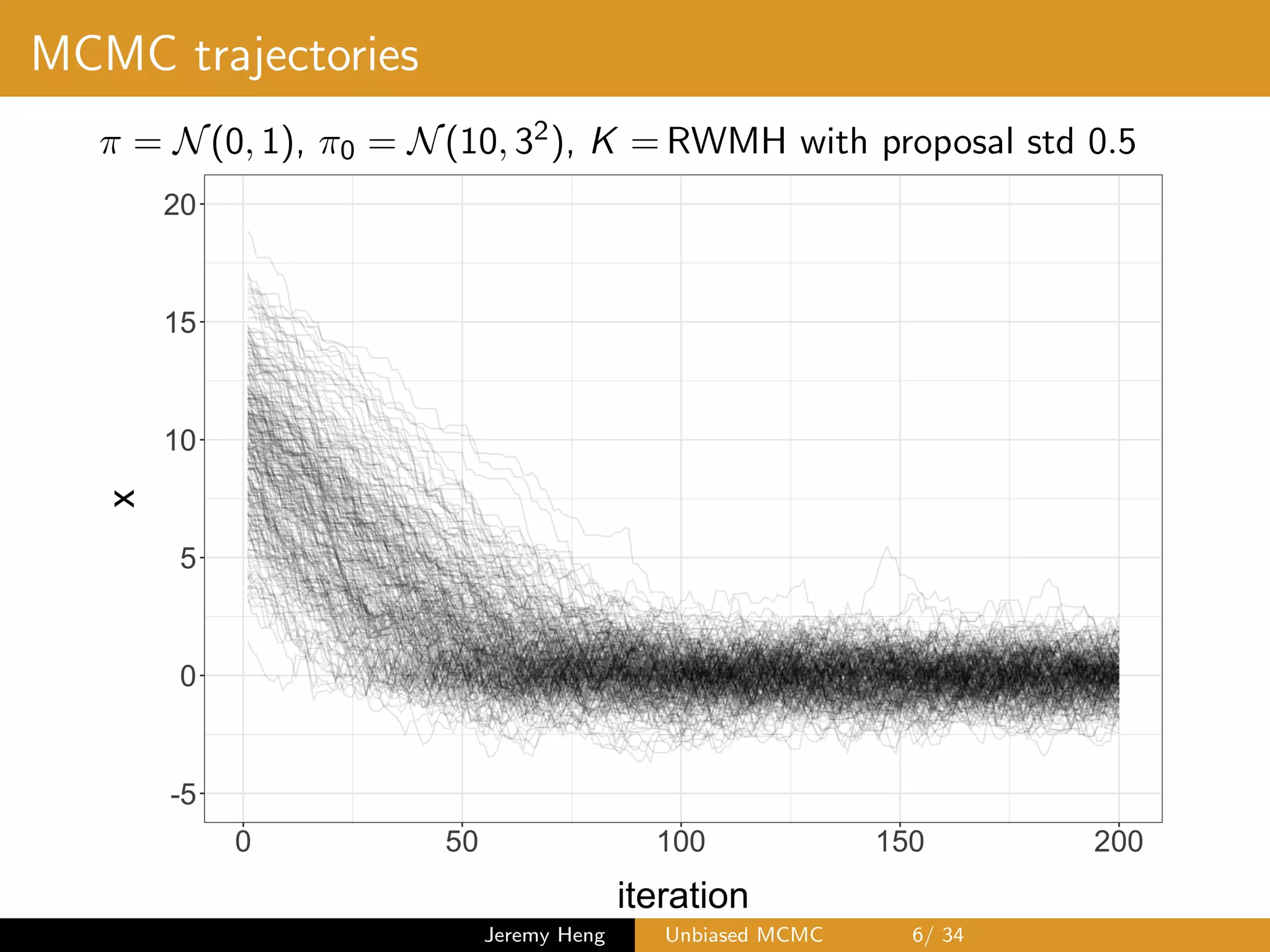
![Markov chain Monte Carlo (MCMC)
• MCMC algorithm defines ⇡-invariant Markov kernel K
• Initialize X0 ⇠ ⇡0 6= ⇡ and iterate
Xt ⇠ K(Xt 1, ·) for t = 1, . . . , T
• Compute
1
T b + 1
TX
t=b
h(Xt) ! E⇡ [h(X)] as T ! 1
where b 0 iterations are discarded as burn-in
• Estimator is biased for any fixed b and T since ⇡0 6= ⇡
• Therefore averaging over independent copies does not
provide a consistent estimator of E⇡ [h(X)] as copies ! 1
Jeremy Heng Unbiased MCMC 3/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-3-2048.jpg)
![Metropolis–Hastings (kernel K)
At iteration t, Markov chain at state Xt
1 Propose X? ⇠ q(Xt, ·), e.g. random-walk X? ⇠ N(Xt, 2Id ),
2 Sample U ⇠ U([0, 1])
3 If
U min
⇢
1,
⇡(X?)q(X?, Xt)
⇡(Xt)q(Xt, X?)
,
set Xt+1 = X?, otherwise set Xt+1 = Xt
Jeremy Heng Unbiased MCMC 4/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-4-2048.jpg)


![Proposed methodology
• Each processor runs two
coupled chains X = (Xt) and
Y = (Yt)
• Terminates at some random
time which involves their
meeting time
• Returns unbiased estimator
Hk:m of E⇡ [h(X)]
• Average over independent
copies to consistently estimate
E⇡ [h(X)] as copies ! 1
• E ciency depends on
expected compute cost and
variance of Hk:m
Parallel MCMC
processors
1
Jeremy Heng Unbiased MCMC 8/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-8-2048.jpg)


![Debiasing idea
Glynn & Rhee. Exact estimation for Markov chain equilibrium
expectations (2014)
• Writing limit as telescopic sum (starting from k 0)
E⇡ [h(X)] = lim
t!1
E [h(Xt)] = E [h(Xk)]+
1X
t=k+1
E [h(Xt) h(Xt 1)]
• Since Xt has the same distribution as Yt for all t 0
E⇡ [h(X)] = E [h(Xk)] +
1X
t=k+1
E [h(Xt) h(Yt 1)]
• If interchanging summation and expectation is valid
E⇡ [h(X)] = E
"
h(Xk) +
1X
t=k+1
h(Xt) h(Yt 1)
#
Jeremy Heng Unbiased MCMC 11/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-11-2048.jpg)
![Debiasing idea
• Truncate infinity sum since Xt = Yt 1 for t ⌧
E⇡ [h(X)] = E
"
h(Xk) +
⌧ 1X
t=k+1
h(Xt) h(Yt 1)
#
with the convention
P⌧ 1
t=k+1{·} = 0 if k + 1 > ⌧ 1
• Unbiased estimator for any k 0
Hk(X, Y ) = h(Xk) +
⌧ 1X
t=k+1
{h(Xt) h(Yt 1)}
• First term h(Xk) is biased; second term corrects for bias
Jeremy Heng Unbiased MCMC 12/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-12-2048.jpg)
![Unbiased estimators
Jacob et al. Unbiased Markov chain Monte Carlo with couplings
(2019)
For any k 0, Hk(X, Y ) is an unbiased estimator of E⇡ [h(X)],
with finite variance and expected cost if
1 Convergence of marginal chain:
lim
t!1
E [h(Xt)] = E⇡ [h(X)] and sup
t 0
E|h(Xt)|2+
< 1, > 0
2 Meeting time ⌧ = inf{t 1 : Xt = Yt 1} has geometric or
polynomial tails:
3 Faithfulness: Xt = Yt 1 for t ⌧
Jeremy Heng Unbiased MCMC 13/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-13-2048.jpg)



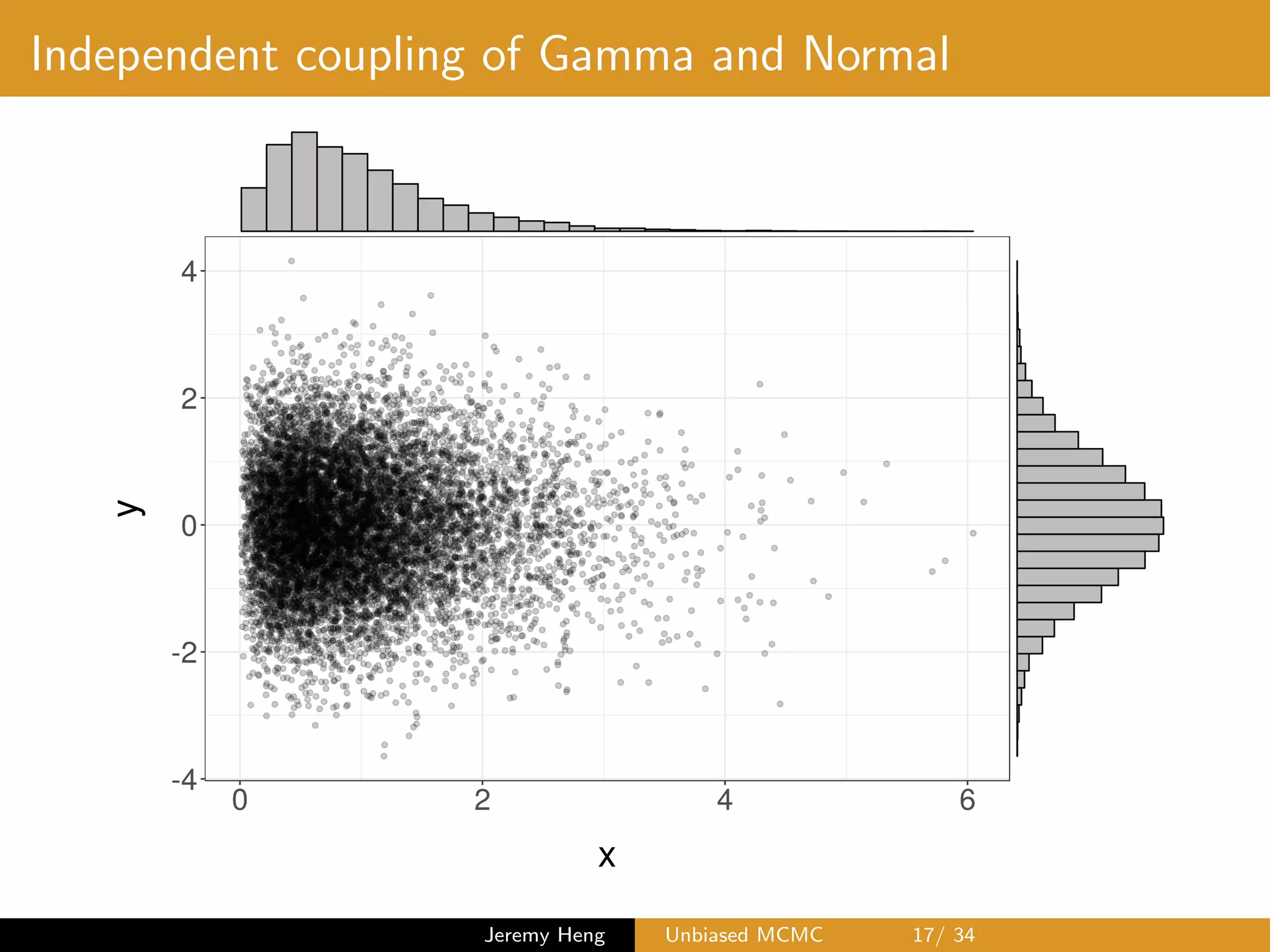
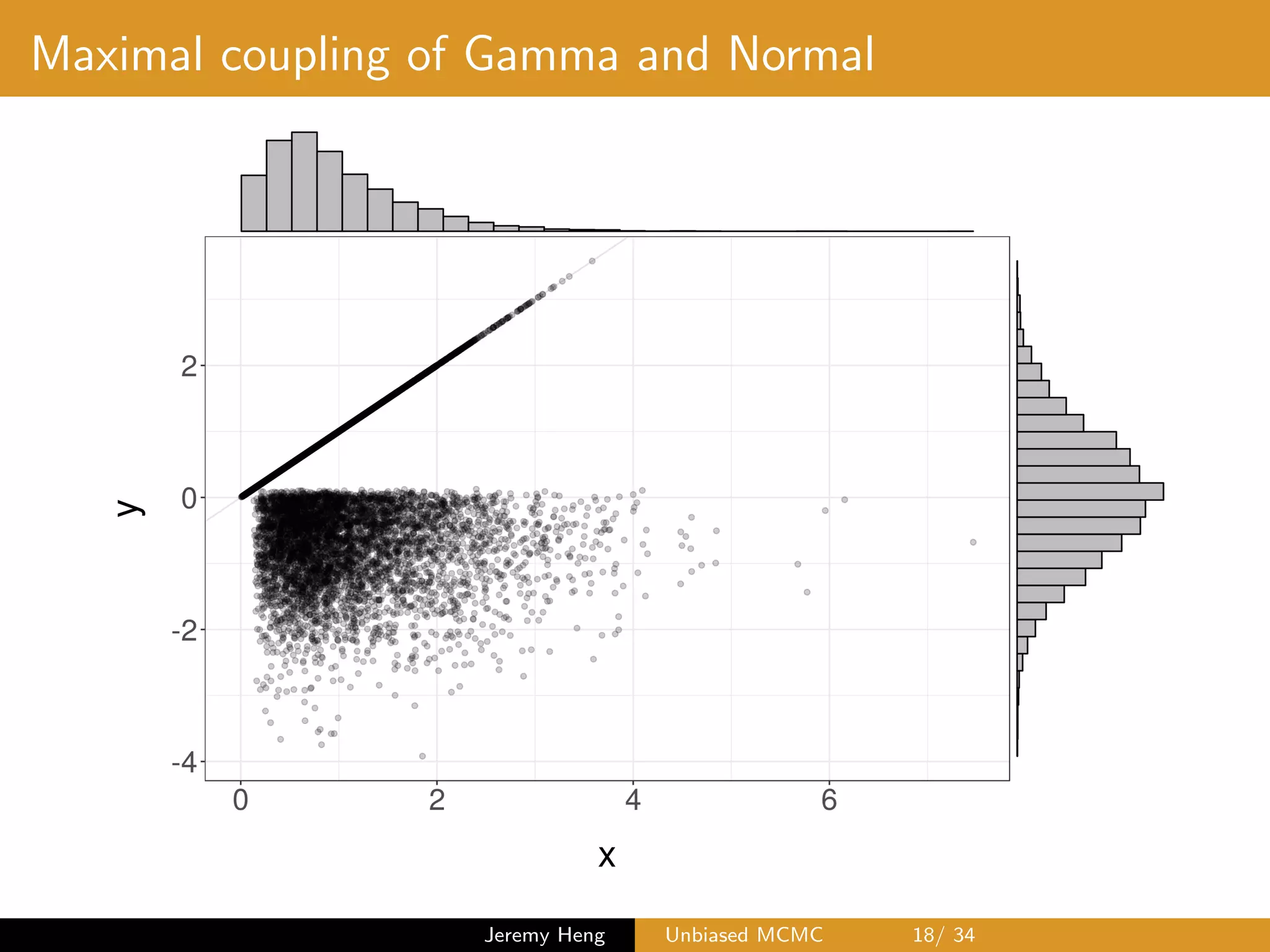
![Maximal coupling: algorithm
Sampling (X, Y ) from maximal coupling of p and q
1 Sample X ⇠ p and U ⇠ U([0, 1])
If U q(X)/p(X), output (X, X)
2 Otherwise, sample Y ? ⇠ q and
U? ⇠ U([0, 1])
until U? > p(Y ?)/q(Y ?), and
output (X, Y ?)
Normal(0,1)
Gamma(2,2)
0.0
0.2
0.4
0.6
0.8
−5.0 −2.5 0.0 2.5 5.0
space
density
Jeremy Heng Unbiased MCMC 19/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-19-2048.jpg)

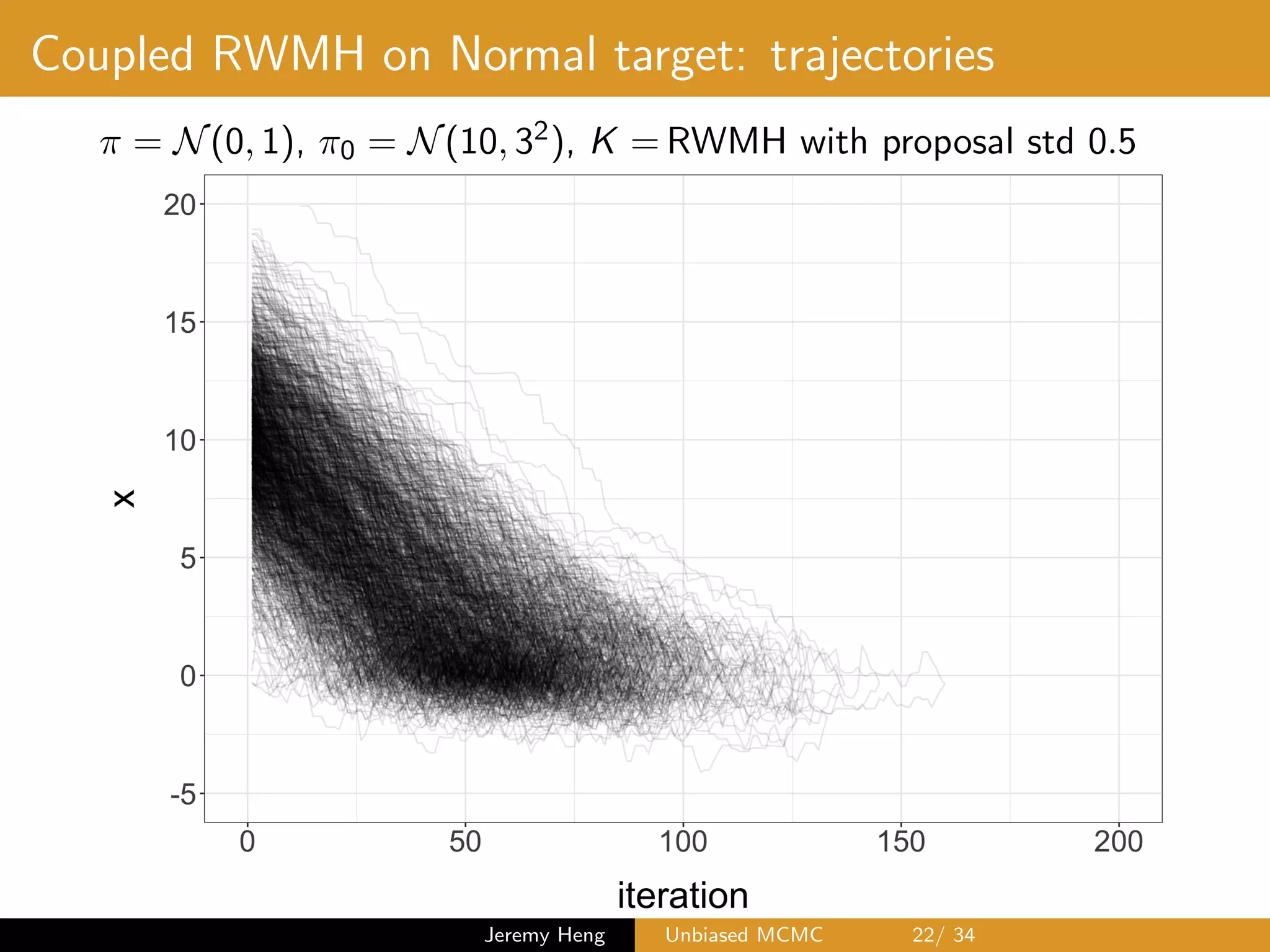
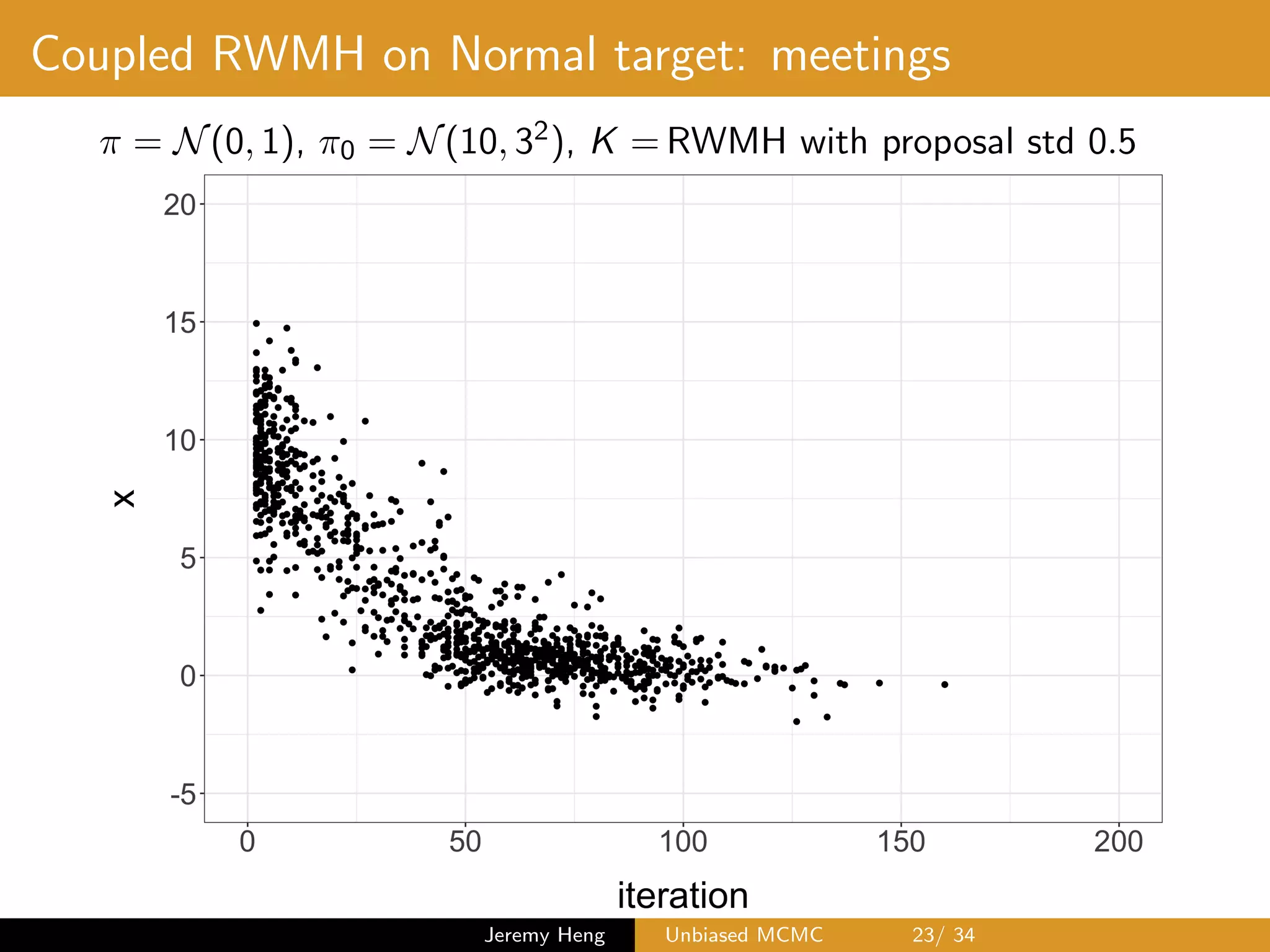
![Coupled Metropolis–Hastings (kernel ¯K)
At iteration t, two Markov chains at states Xt and Yt 1
1 Propose (X?, Y ?) from maximal coupling of q(Xt, ·) and
q(Yt 1, ·)
2 Sample U ⇠ U([0, 1])
3 If
U min
⇢
1,
⇡(X?)q(X?, Xt)
⇡(Xt)q(Xt, X?)
,
set Xt+1 = X?, otherwise set Xt+1 = Xt
If
U min
⇢
1,
⇡(Y ?)q(Y ?, Yt 1)
⇡(Yt 1)q(Yt 1, Y ?)
,
set Yt = Y ?, otherwise set Yt = Yt 1
Jeremy Heng Unbiased MCMC 21/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-21-2048.jpg)

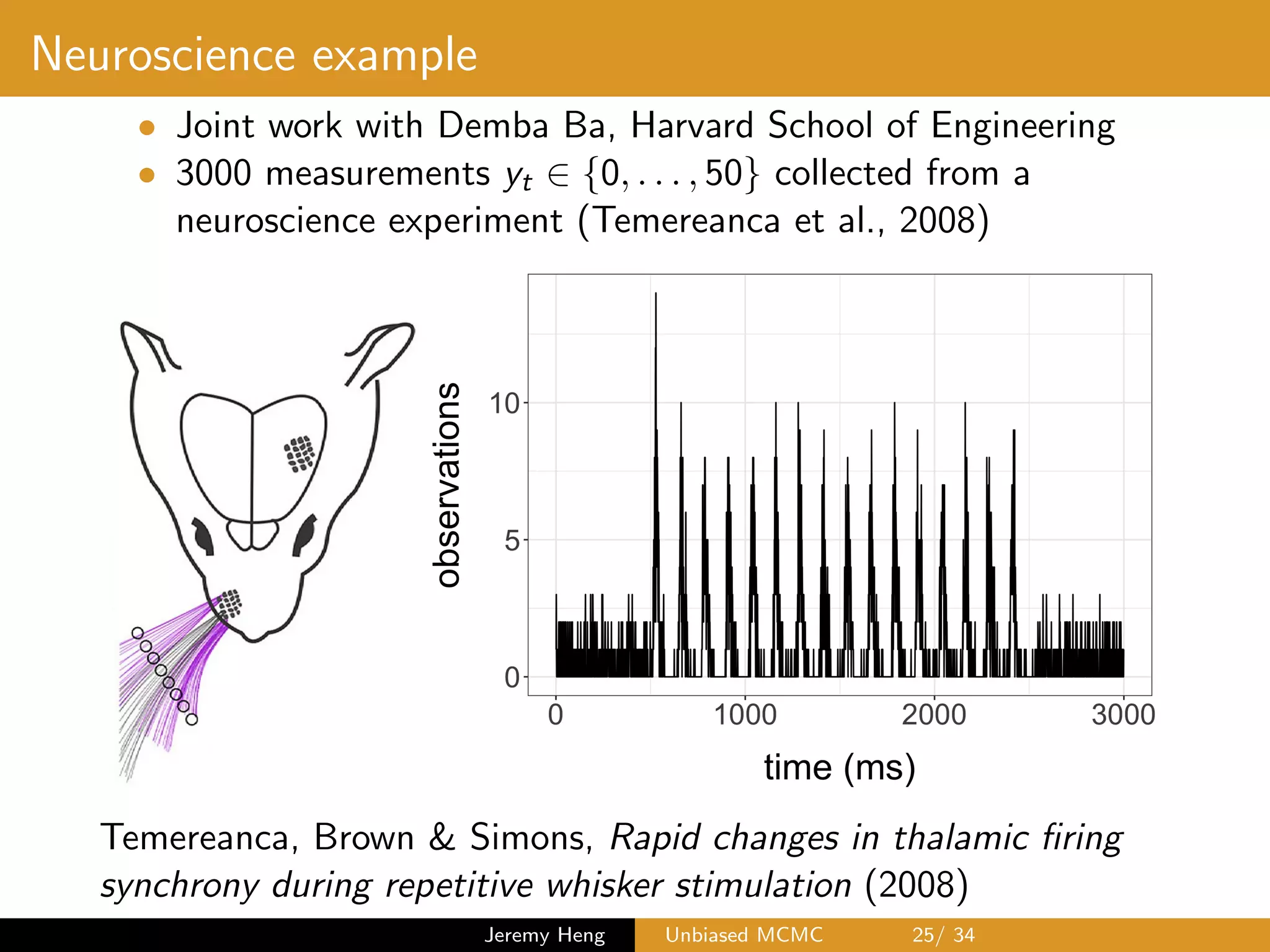
![Neuroscience example
• Observation model
Yt|Xt ⇠ Binomial 50, (1 + exp( Xt)) 1
• Latent Markov chain
X0 ⇠ N(0, 1), Xt|Xt 1 ⇠ N(aXt 1, 2
X )
• Unknown parameters are (a, 2
X ) 2 [0, 1] ⇥ (0, 1)
• Particle marginal Metropolis–Hastings (PMMH) to sample
p(a, 2
X |y0:T ) / p(a, 2
X )p(y0:T |a, 2
X )
and particle filters to unbiasedly estimate the likelihood
p(y0:T |a, 2
X ) =
Z
RT+1
p(x0:T , y0:T |a, 2
X ) dx0:T
Andrieu, Doucet & Holenstein. Particle Markov chain Monte
Carlo methods (2010)
Jeremy Heng Unbiased MCMC 26/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-26-2048.jpg)



![Choice of proposal standard deviation
Meeting times of coupled PMMH chains initialized independently
from ⇡0 = U([0, 1]2)
Figure: Right plot uses 5 times the proposal standard deviation of left plot
Jeremy Heng Unbiased MCMC 30/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-30-2048.jpg)

![Choice of particle filter
Meeting times of coupled PMMH chains initialized independently
from ⇡0 = U([0, 1]2)
Figure: cSMC (left) and BPF (right) with N = 4, 096 to match compute
time
Jeremy Heng Unbiased MCMC 32/ 34](https://image.slidesharecdn.com/smcfinanceworkshop-191019102228/75/Unbiased-Markov-chain-Monte-Carlo-32-2048.jpg)















































![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)

