More Related Content

PPTX
Talking about Microsoft On-premises Data Gateway 
PPTX

PDF
階層ベイズでプロ野球各球団の「本当の強さ」を推定してみる 
PDF

PDF

PDF

PPTX
a story about an application that uses a real quantum computer 
PDF
Introduction to Quantum Programming Studio Viewers also liked

PDF

PDF
SQL Developerって必要ですか? 株式会社コーソル 河野 敏彦 
PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました― 
PDF

PPTX

PDF
グラフデータベース「Neo4j」の 導入の導入(続き)-Cypherの基本のキ- 
PDF
『オープンソースで学ぶ社会ネットワーク分析』1章 イントロダクション 
PDF

PDF

PDF
本当に知ってる!? リアルなデータ分析の世界~サイカのエンジニアが語る、話題の技術の「いま」と「未来」~ 
PDF
大学生のTwitter利用に関する定量分析―利用目的とサービス設計の関係― 
PDF
第1回「データ解析のための統計モデリング入門」読書会 オープニング 
PDF
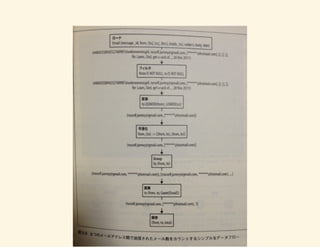
『アジャイルデータサイエンス』2章 データ
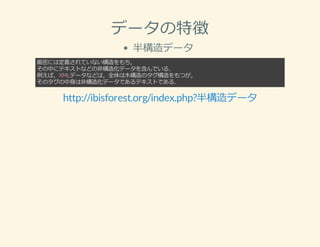
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.