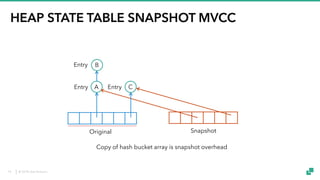
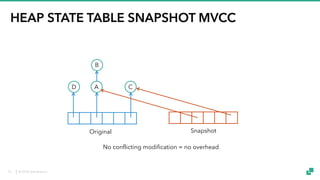
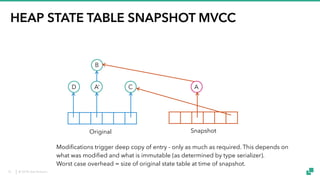
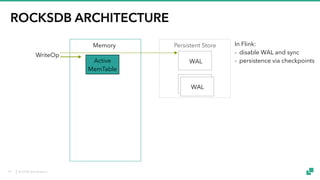
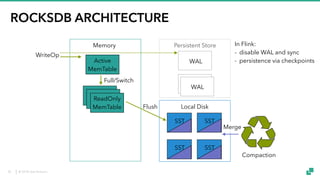
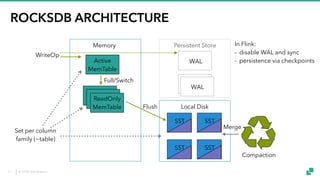
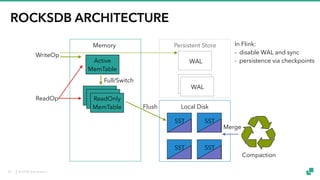
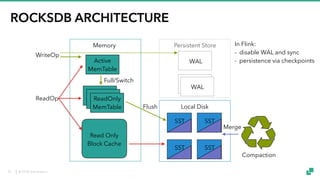
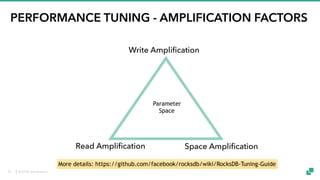
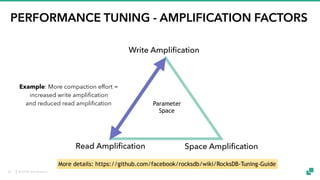
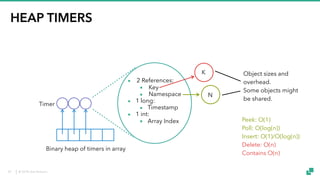
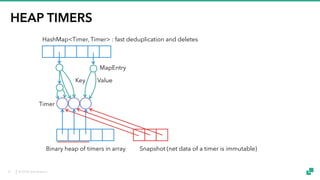
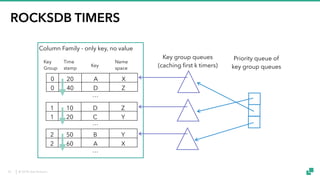
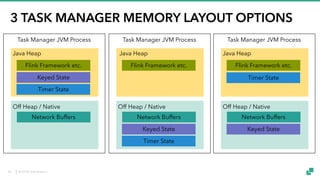
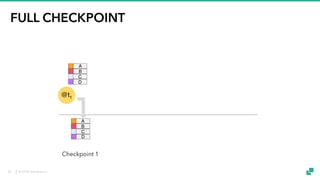
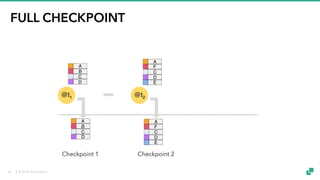
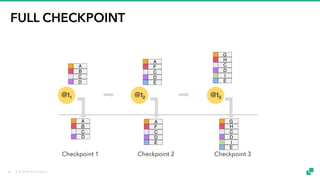
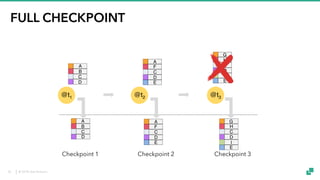
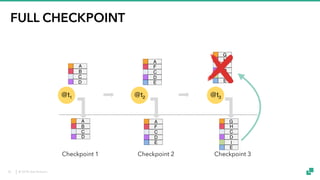
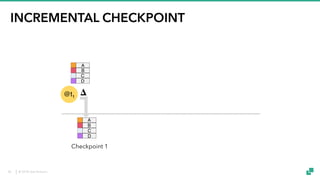
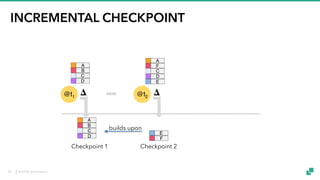
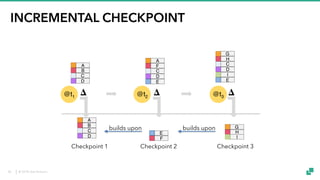
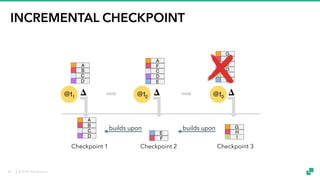
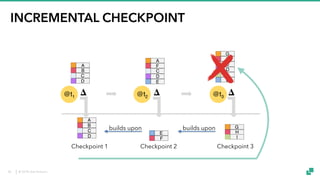
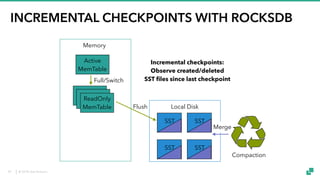
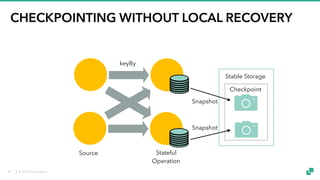
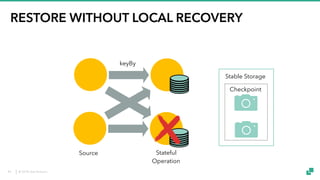
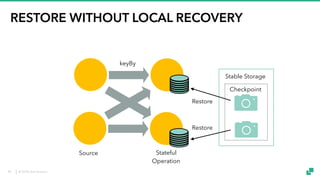
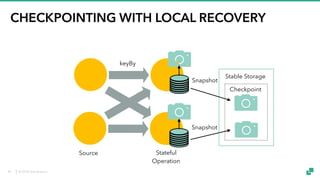
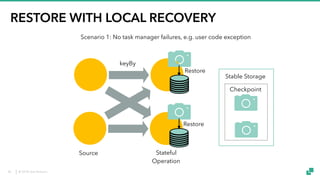
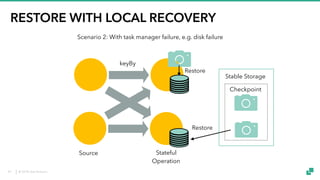
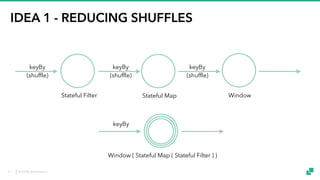
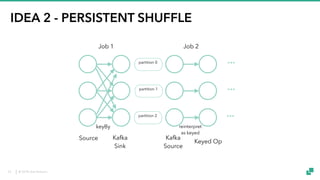
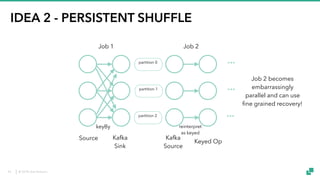
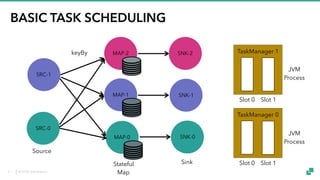
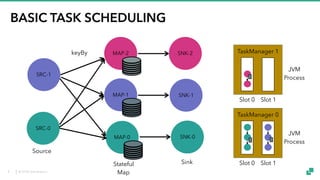
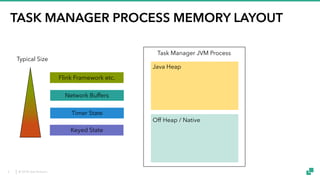
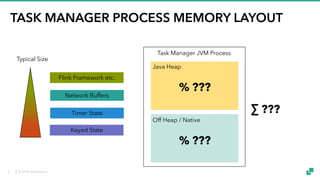
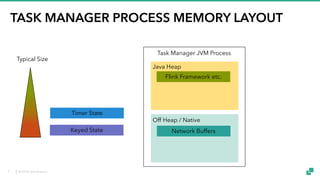
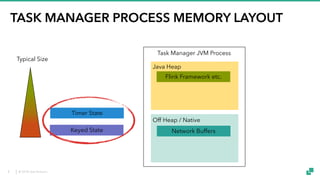
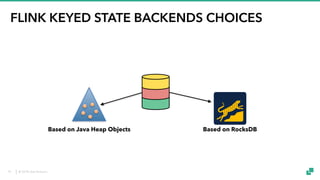
The document provides an overview of tuning Apache Flink for improved robustness and performance, focusing on memory management, task scheduling, and state backends. It details the characteristics and trade-offs of heap and RocksDB keyed state backends, including memory management, snapshots, and checkpointing strategies. Additionally, it discusses performance tuning considerations and offers insights on managing resource consumption, along with examples of optimizing task execution.





![© 2018 data Artisans
HEAP STATE TABLE ARCHITECTURE
- Hash buckets (Object[]), 4B-8B per slot
- Load factor <= 75%
- Incremental rehash
Entry
Entry
Entry
12](https://image.slidesharecdn.com/ff18b-180919132318/85/Tuning-Flink-For-Robustness-And-Performance-12-320.jpg)
![© 2018 data Artisans
HEAP STATE TABLE ARCHITECTURE
- Hash buckets (Object[]), 4B-8B per slot
- Load factor <= 75%
- Incremental rehash
Entry
Entry
Entry
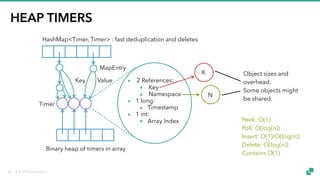
▪ 4 References:
▪ Key
▪ Namespace
▪ State
▪ Next
▪ 3 int:
▪ Entry Version
▪ State Version
▪ Hash Code
K
N
S
4 x (4B-8B)
+3 x 4B
+ ~8B-16B (Object overhead)
Object sizes and
overhead.
Some objects might
be shared.
13](https://image.slidesharecdn.com/ff18b-180919132318/85/Tuning-Flink-For-Robustness-And-Performance-13-320.jpg)