YAPC::Asia 2008 Tokyo - Pathtraq - building a computation-centric web service
The talk describes the architecture of Pathtraq, one of Japan's largest web access statistics service, covering from database compression techniques to embedded SQL in perl.
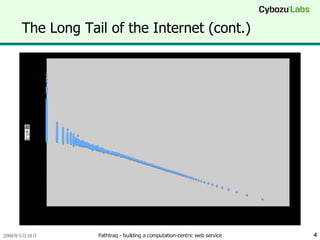
The Long Tailof the Internet (cont.) y=C ・ x -0.44 Number of pages with 1/10 hits: ×2.75 ヒット数が 1/10 のページは 2.75 倍存在
6.
Introduction of Pathtraq(Pathtraq の紹介 ) Alexa-like web access stats service Alexa のようなウェブアクセス統計サービス Per-page, realtime stats ページ単位のリアルタイム統計 Extracts and displays what is hot ホットな情報を抽出して表示
Introduction of Pathtraq(cont.) Active sample users: 6,300 サンプルユーザー数 : 6,300 # of accesses collected: 100M (1M/day) アクセスの収集数 : 1 億件 (100 万件 / 日 ) # of URLs stored: >40M 保存されている URL の個数 : 4000 万以上 Data Size: 100GB データサイズ : 100GB
9.
To Scale Outor Not ( スケールアウトの是非 ) Depends on CPU / storage cost CPU やストレージのコストに依存する Overhead of scaling out depends on app. アプリケーションによってはスケールアウトによるオーバーヘッドが発生 32GB-64GB per server is today’s sweet spot for memory intensive services メモリインテンシヴなサービスではサーバあたり 32GB-64GB のメモリ容量が最安
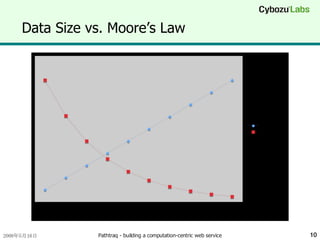
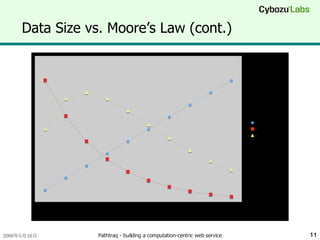
Data Size vs.Moore’s Law (cont.) Assume data size is proportional to years of operation データサイズが運用年数に比例する場合 Software-based optimization is only necessary for first three years 最適化は最初の3年間だけ考えればいい After then, Moore’s Law becomes dominant その後はムーアの法則が支配的になる
13.
Scaling: Our ChoiceRequirement of first year: 24GB mem. 初年度の必要メモリ量 : 24GB Overhead expected if scaled out ↓ No distributed database データベースの分割は行わない Export some tasks to other servers タスク単位で別サーバへ移動
14.
Hardware of PathtraqMain Server (1U) Opteron 2218 x2, 32GB Mem, 500GB HDD MySQL 5.1, Apache, etc. Helper Servers Web Content Analysis (Web コンテンツの分析 ) Full-text Search ( 全文検索 )
15.
Technical Problems ofPathtraq Compression for size & speed 圧縮による省メモリ化 と高速化 Log analysis requires fast random access 高速なランダムアクセスが必要 HDD is toooooo slow ( 〜 3MB/sec.) HDD はランダムアクセスが遅すぎる Main tables need to be on memory 主要テーブルはオンメモリが MUST
16.
Technical Problems ofPathtraq (cont.) Query caching Log analysis is heavy task ログ分析は重たい Need for sophisticated cache control 高度なキャッシュコントロールが必要 Fast and trustable message queues 高速で信頼できるメッセージキュー
Facts re Compression( 圧縮関連の現状) # of access logs stored: 100M 保存されているアクセスログ : 約1億件 A single access log: (url,referer,when) アクセスログ : (url,referer, 日時 ) Average length of URL: 70byes URL の平均バイト数 : 70 バイト
19.
URL Compression (URLの圧縮 ) URLs can be compressed URL は圧縮可能 http://www. example .com/ foobar .html But too short for gzip (deflate) gzip (deflate) には短すぎる Need for a compression algorithm using prior knowledge 事前知識を使用した圧縮アルゴリズムが必要
20.
URL Compression (cont.)Should be searchable in compressed-form, or we cannot use indexes 圧縮状態のまま、インデックスを利用して検索できる必要がある
21.
URL Compression: StaticPPM PPM: Prediction by Partial Matching Used by 7-zip, etc. (7-zip 等で使用 ) Use range coder as backend Original collation order can be preserved レンジコーダと組み合わせることで文字集合の順序を保ったまま圧縮できる
22.
URL Compression inPathtraq Impl. as MySQL UDFs MySQL UDF として実装 Original Query: url like “http://example.com/%” Query for compressed URL: compress(“http://…/”)<=curl and curl<compress(“http://…0”) Search in compressed form is faster 圧縮版の方が高速に検索可能
Using Together withInnoDB Plugin InnoDB Plugin released May 2008 (2008 年 5 月リリース ) supports per-page compression using deflate Deflate を使用した DB のページ単位圧縮を実現 mainly for optimizing disk-based databases ディスクベースのデータベース最適化に好適
25.
Using Together withInnoDB Plugin (cont.) Table size becomes smallest when both compressions are applied 両者の併用で高率の圧縮が可能 33% using both 50% InnoDB compression 57% URL compression 100% N/A Ratio Compression
26.
Counter Compression (カウンタの圧縮 ) Counter is a list of (hit_count,time) カウンタは ( ヒット数 , 日時 ) のリスト Time granularity is 1 hour 日時の分解能は1時間 Compressed as a sparse array, stored as a blob in DB スパースアレイとして圧縮し、 blob として DB に保存
27.
Counter Compression (cont.)Accessors impl. as MySQL UDFs MySQL UDF としてアクセサを実装 Accessors decompress sparse arrays and perform vector operations within MySQL アクセサは粗行列を展開して MySQL 内でベクタ演算を実行 Fewer rows lead to smaller footprint and faster speed 行数の減少による省メモリ化と高速化
Facts re QueryCaching Log analysis is aggregation ログ分析は集約演算 Aggregation is heavy task 集約演算は重たい Some queries are repeated very often 一部のクエリが頻発
30.
KeyedMutex An interprocessmutex impl’ed as a tiny server/client system プロセス間 Mutex を実現するサーバ Used to prevent equiv. queries from being sent to MySQL at the same time MySQL へ同時に同一クエリを行わないために利用 Query results shared using Cache::Swifty クエリ結果は Cache::Swifty で共有
31.
Cache::Swifty A veryfast cache using mmap’ed files, optimized for read performance mmap されたファイル群を利用する高速キャッシュ、特に read が速い Lock-free reads, flock’ed writes lock-free の読み込みと flock を利用した書き込み Robust futexes might be usable to optimize write performance on recent linux kernels Robust futexes を使えば書込パフォーマンスも上がるかも
32.
Cache::Swifty (cont.) 70times faster for 16 bytes reads than Cache::Memcached 16 バイトの読込だと Cache::Memcached の 70 倍速 Suitable for caching data on a single server without re-designing the app. 単一サーバ上でデータをキャッシュする際に簡単に利用できる(透過的に追加できる )
33.
Cache::Swifty (cont.) Hasa feature that notifies a single client to update requested cached data sometime before the cached entry actually expires キャッシュエントリがエクスパイヤする前に、クライアントのうちひとつだけに対して更新を推奨できる Prevents thundering herd upon cache expiration エクスパイヤに伴うブロックを抑制
34.
Filter::SQL Pathtraq isheavily dependent on SQL Pathtraq の開発においては SQL が中心 Perl code is basically a glue Perl コードは glue としての役割が大きい DBI (and others) is too complicated for writing glue code DBI その他はグルーコードを書くには複雑すぎる
35.
Filter::SQL (cont.) EmbeddedSQL in perl style Perl で書きやすい形の埋め込み SQL EXEC INSERT INTO speakers (surname,firstname) VALUES (’oku’, ’ kazuho’); $sn = ‘oku’; for my $r (SELECT firstname FROM speakers WHERE surname=$sn;) { print “$r->[0]\n”; # kazuho }
Facts re MessageQueues Used for transferring content analysis requests and responses コンテンツ解析処理を委譲するために使用 Polling a 40M row table is heavy 4000 万行のテーブルを poll するのは重たい Need for a proper message queue ちゃんとしたメッセージキューが必要
38.
Q4M A PluggableStorage Engine for MySQL 5.1 MySQL 5.1 のプラガブルストレージエンジン Looks like an ordinal SQL table, has a special mode to operate as MQ 一見通常の SQL テーブルだが、 MQ として動作するモードがある
39.
Features of Q4MTrustable ( 高信頼性 ) Every operation is fsync’ed to disk すべての操作がディスクへ fsync される Fast ( 高速性 ) >10,000 mess./sec. on Opteron 2218 x 2 Trustable forwarding between queues キュー間の信頼できる転送機能 no losses or duplicates on network failure ネットワーク障害時にもデータロスや複製が発生しない
40.
Q4M: Sample CodeQueue Submission: INSERT INTO mq (mess) VALUES (‘hello’); Queue Subscription: while (1) { next unless SELECT ROW queue_wait(‘mq’);; my $mess = SELECT ROW mess FROM mq;; … . SELECT ROW queue_end(‘mq’);; }
41.
Q4M: Sample Code(cont.) A wrapper module (Queue::Q4M) is available as well ラッパーモジュール (Queue::Q4M) もあります
42.
Q4M in PathtraqUsed for transferring content analysis requests and responses コンテンツ解析処理を委譲するために使用 Exchanging data between servers located in different iDCs, over SSL-encrypted MySQL connection, between ruby and perl 異なる iDC 間でのデータ交換に、 SSL 暗号化された MySQL 接続を使い、 ruby と perl 間でデータ交換
Thanks to Forall the code we use CPAN modules authors and OSS developers The Developers of Senna and Tritonn Daisuke Maki-san (CPAN ID: dmaki) for Gungho and Queue::Q4M Members of Cybozu Labs Others who gave us advises and lastly but mostly, to the users of Pathtraq (Pathtraq のユーザーのみなさん、ありがとうございます )
































![Filter::SQL (cont.) Embedded SQL in perl style Perl で書きやすい形の埋め込み SQL EXEC INSERT INTO speakers (surname,firstname) VALUES (’oku’, ’ kazuho’); $sn = ‘oku’; for my $r (SELECT firstname FROM speakers WHERE surname=$sn;) { print “$r->[0]\n”; # kazuho }](https://image.slidesharecdn.com/pathtraq2008yapc-1210929382831552-8/85/YAPC-Asia-2008-Tokyo-Pathtraq-building-a-computation-centric-web-service-35-320.jpg)



































































































