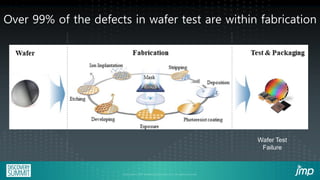
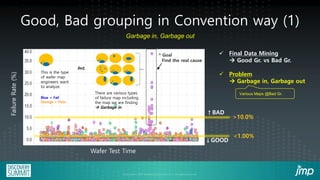
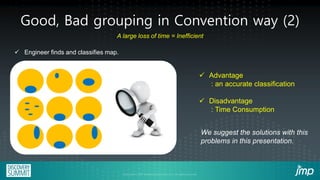
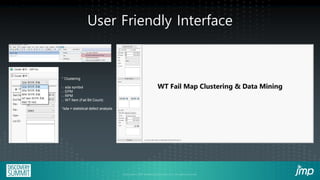
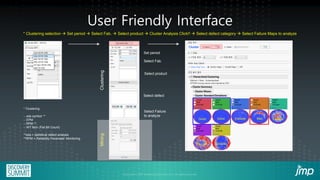
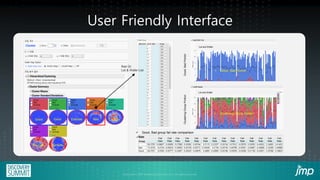
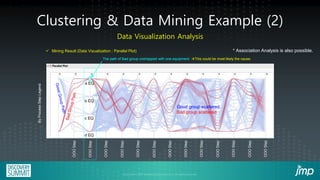
The document discusses the use of JMP add-ins for semiconductor wafer test failure map clustering and data mining, highlighting methods to classify defects efficiently. It emphasizes the importance of user-friendly interfaces and accurate classification to reduce engineers' time spent on repetitive tasks. Key advantages include a faster, more accurate process for classifying failure maps and the accessibility of the tool for all users.










![WF Count Human [min] AI [min]
100 6 0.03
1000 60 0.16
3000 180 5
Clustering Process Time [ Human vs AI ]
Human
[min]
AI
[min]
AI
180min
5min
Human
Wafer Count
✓ Dramatically reduces time consumption for engineer](https://image.slidesharecdn.com/track3-1skhynixtl-231115020454-911dd250/85/3-1-Semiconductor-Wafer-Test-Fail-Map-Clustering-and-Data-Mining-using-JMP-Add-In-17-320.jpg)






























































