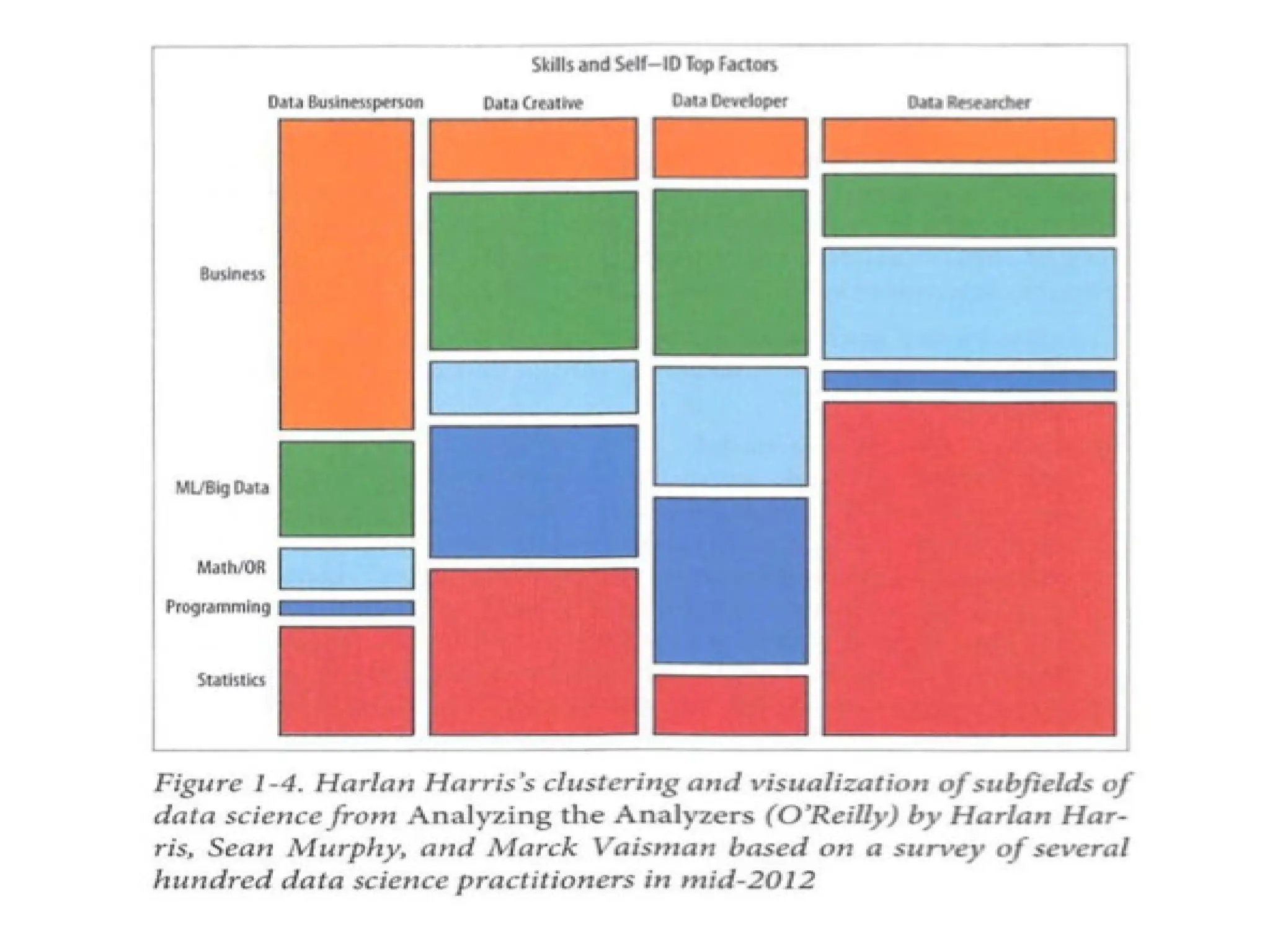
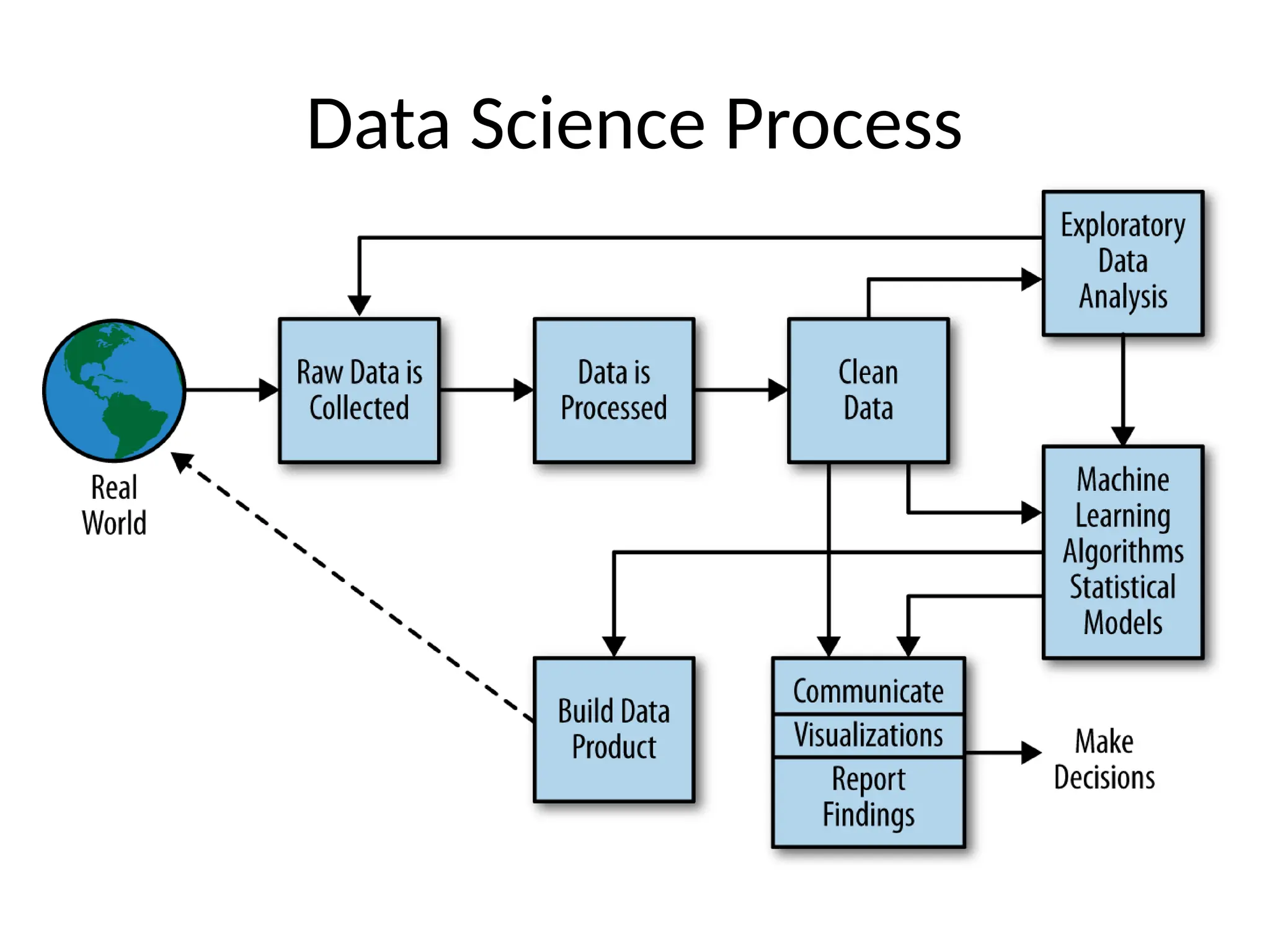
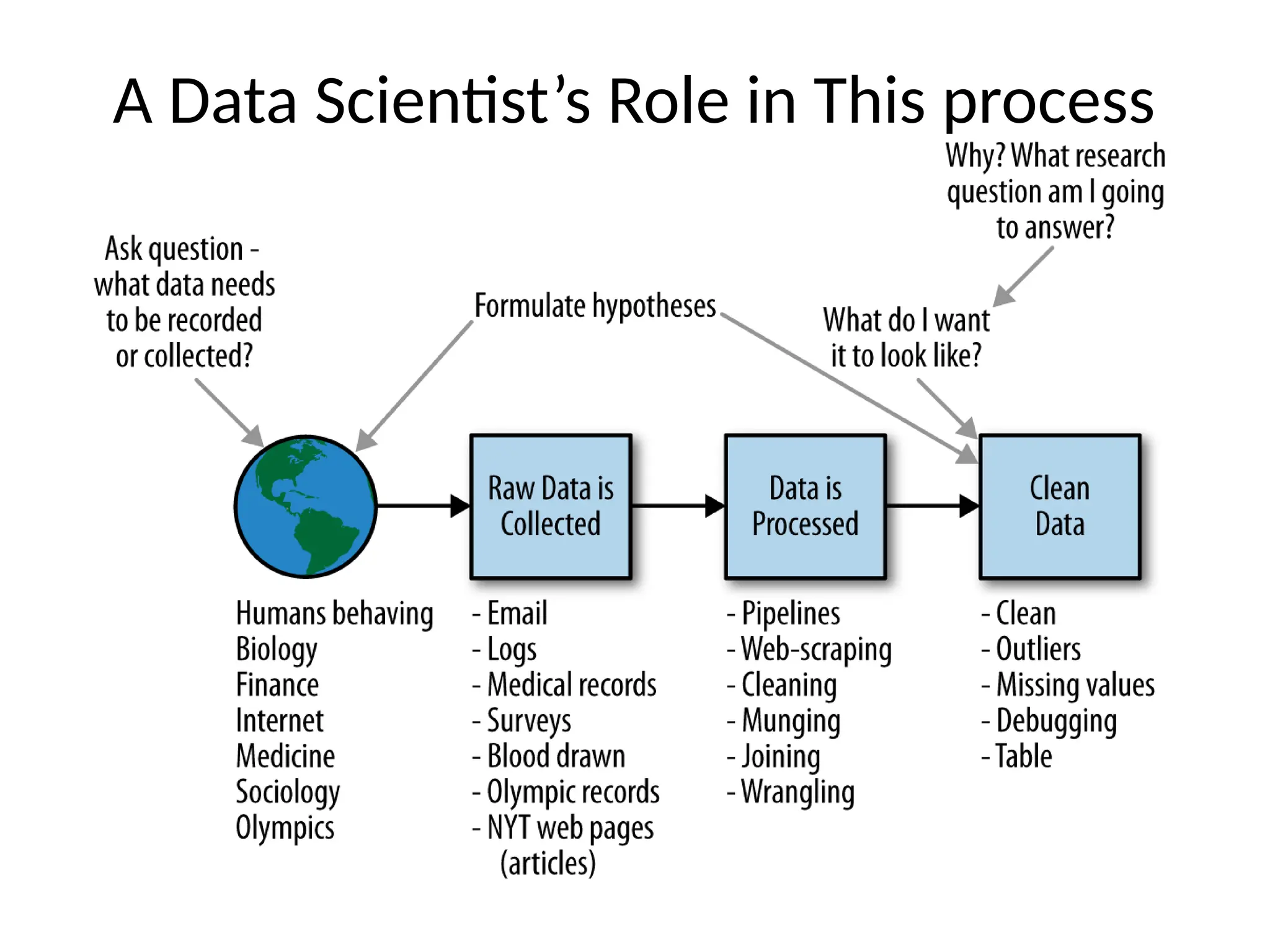
Chapter 1 discusses the concept of data science, its evolution, and the role of data scientists in both academia and industry, emphasizing the need for diverse skills and collaboration. Chapter 2 explores big data statistics, touching on statistical thinking, inference, and the importance of understanding populations and samples in data analysis. Additionally, it highlights the significance of exploratory data analysis as a mindset and critical tool in the data science process.







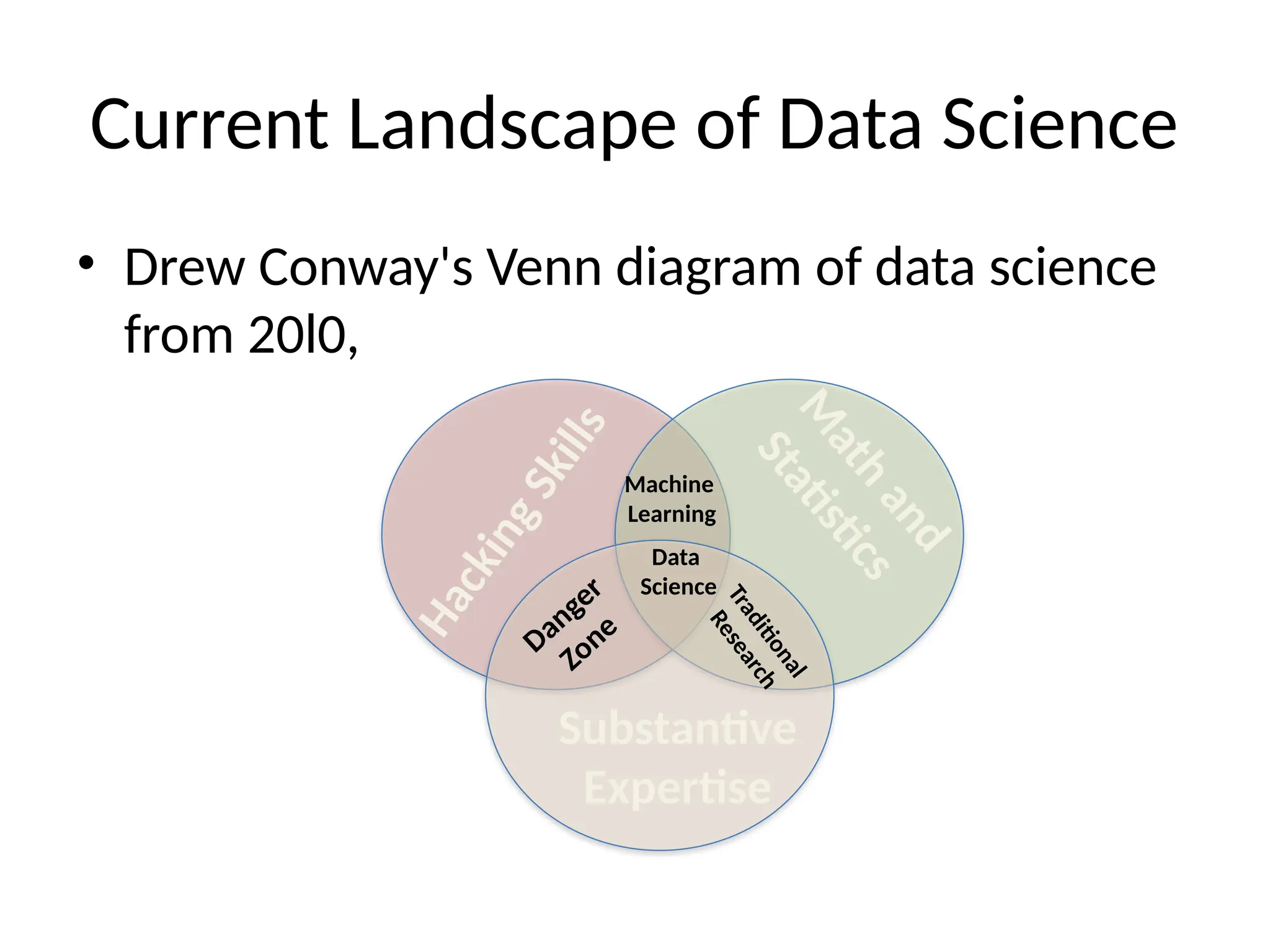

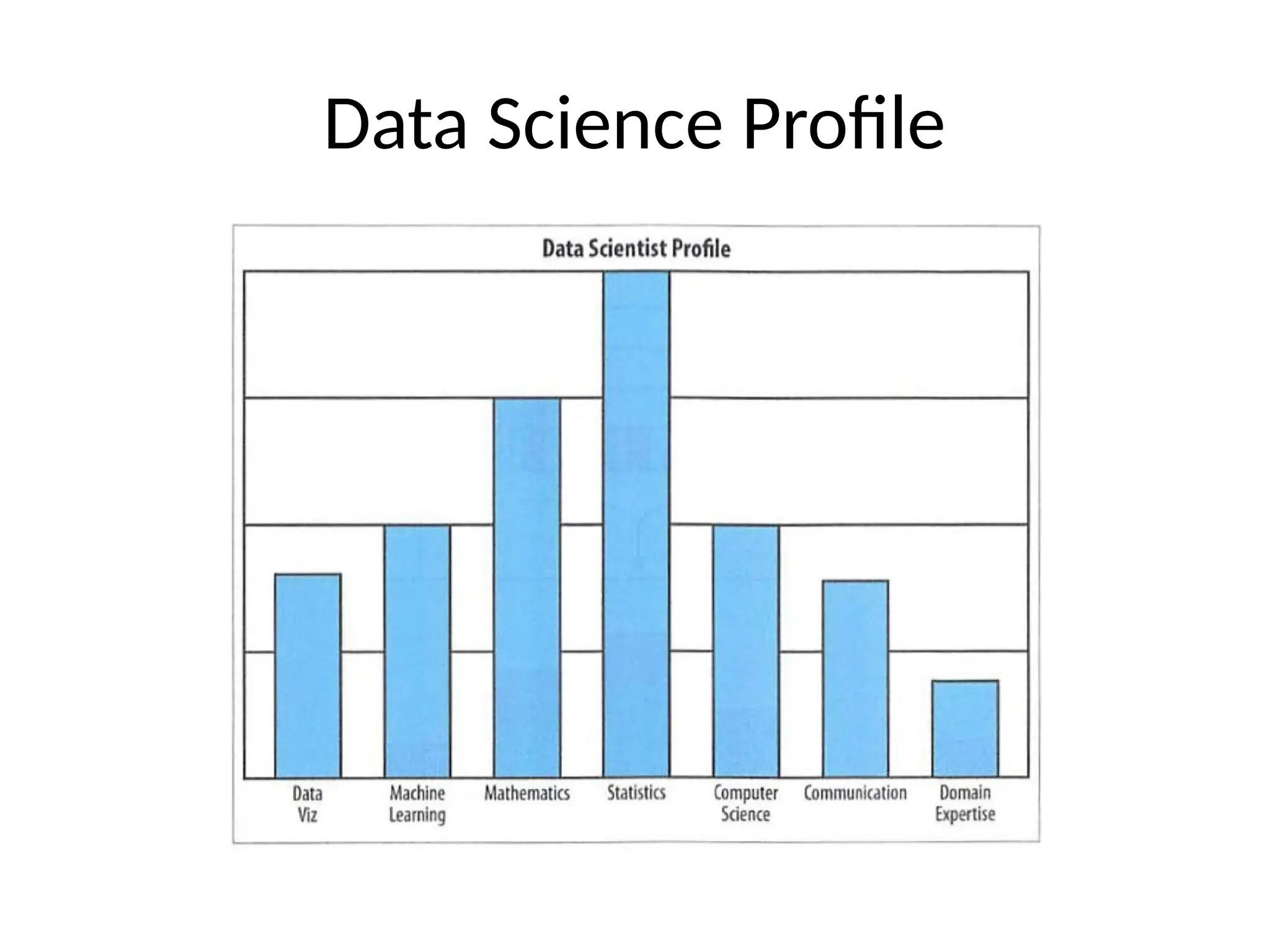
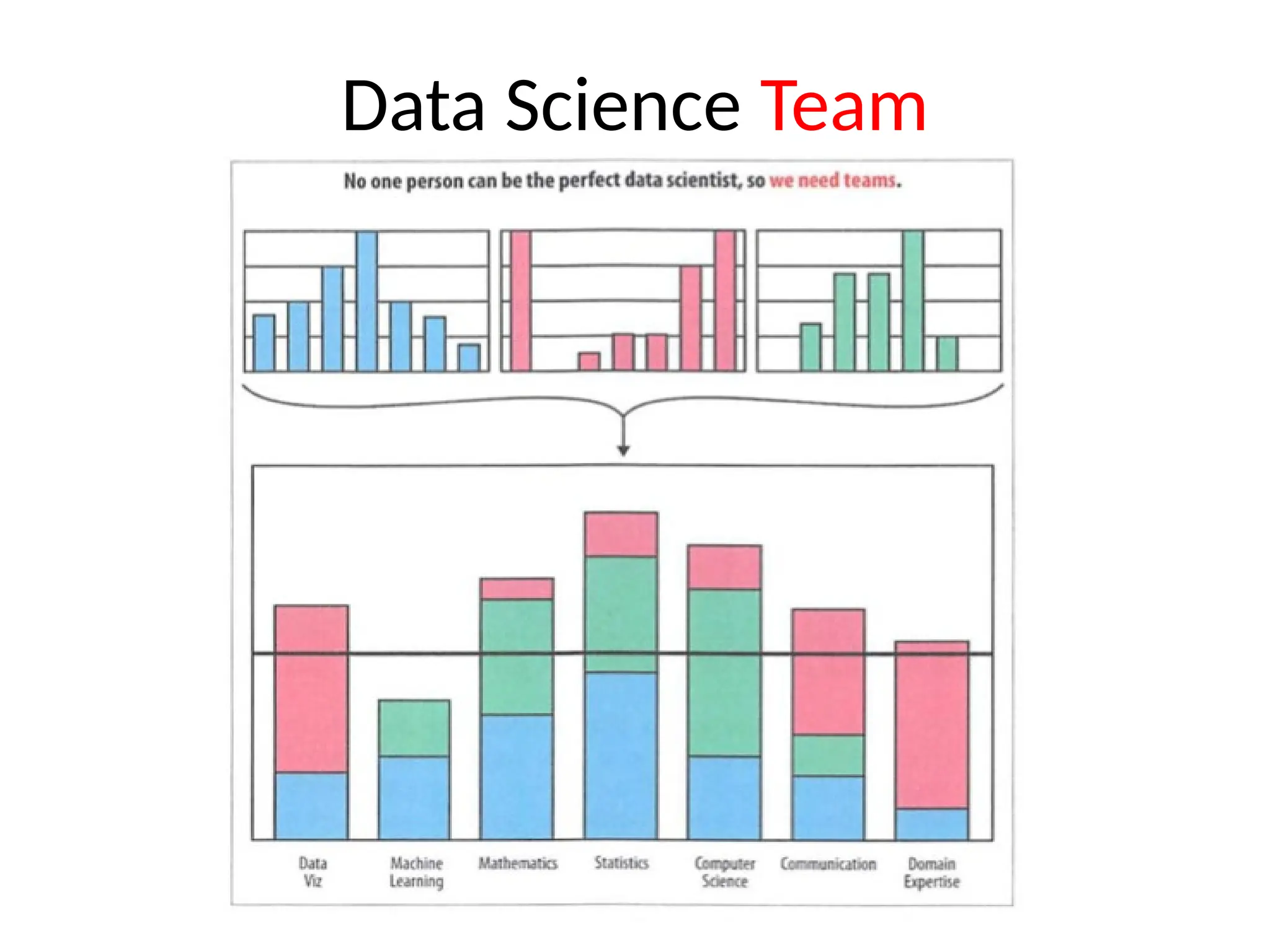










































![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)