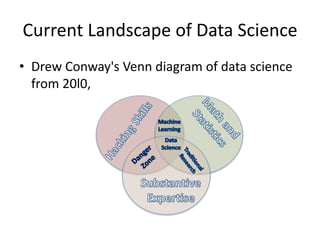
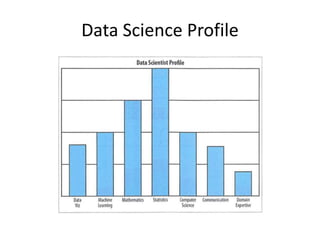
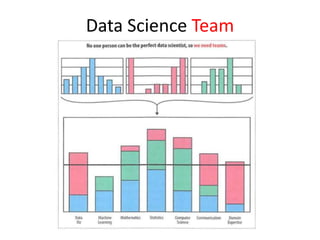
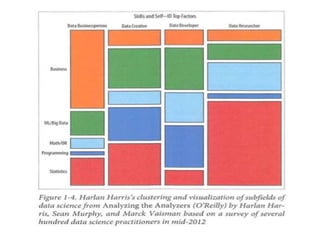
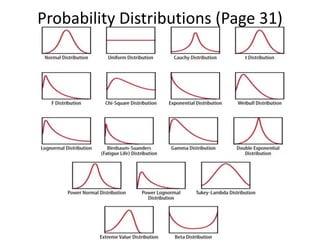
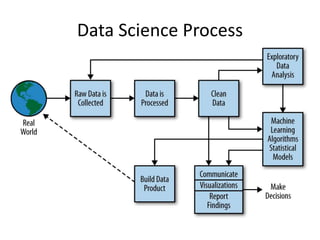
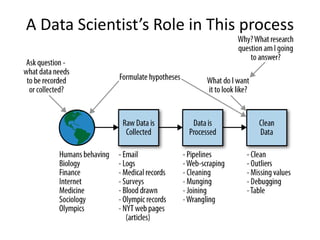
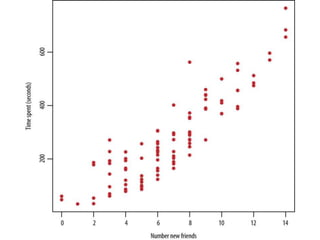
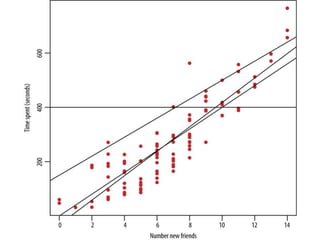
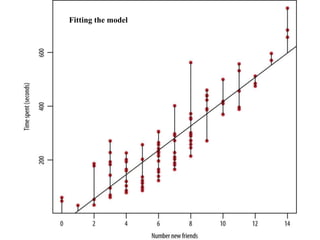
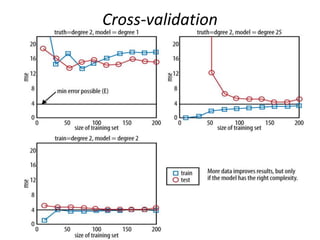
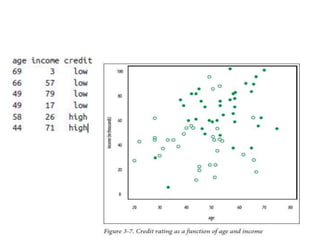
The document provides an overview of data science and what it entails. It discusses the hype around big data and data science, and how data science has evolved due to improvements in technology that allow for large-scale data processing. It defines data science as a process that involves collecting, cleaning, analyzing and extracting meaningful insights from data. Data scientists come from a variety of academic backgrounds and work in both industry and academia developing solutions to real-world problems using data-driven approaches.