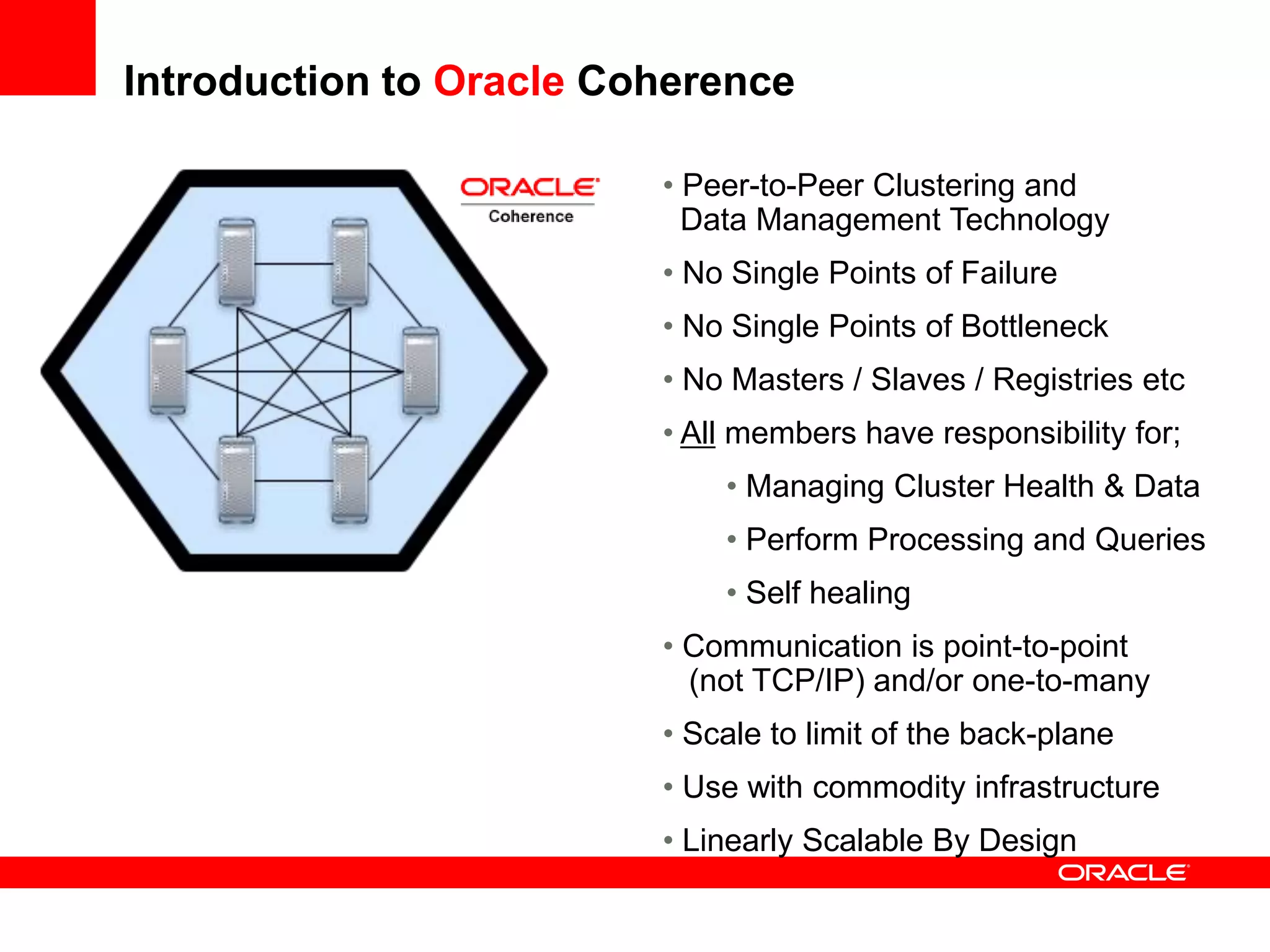
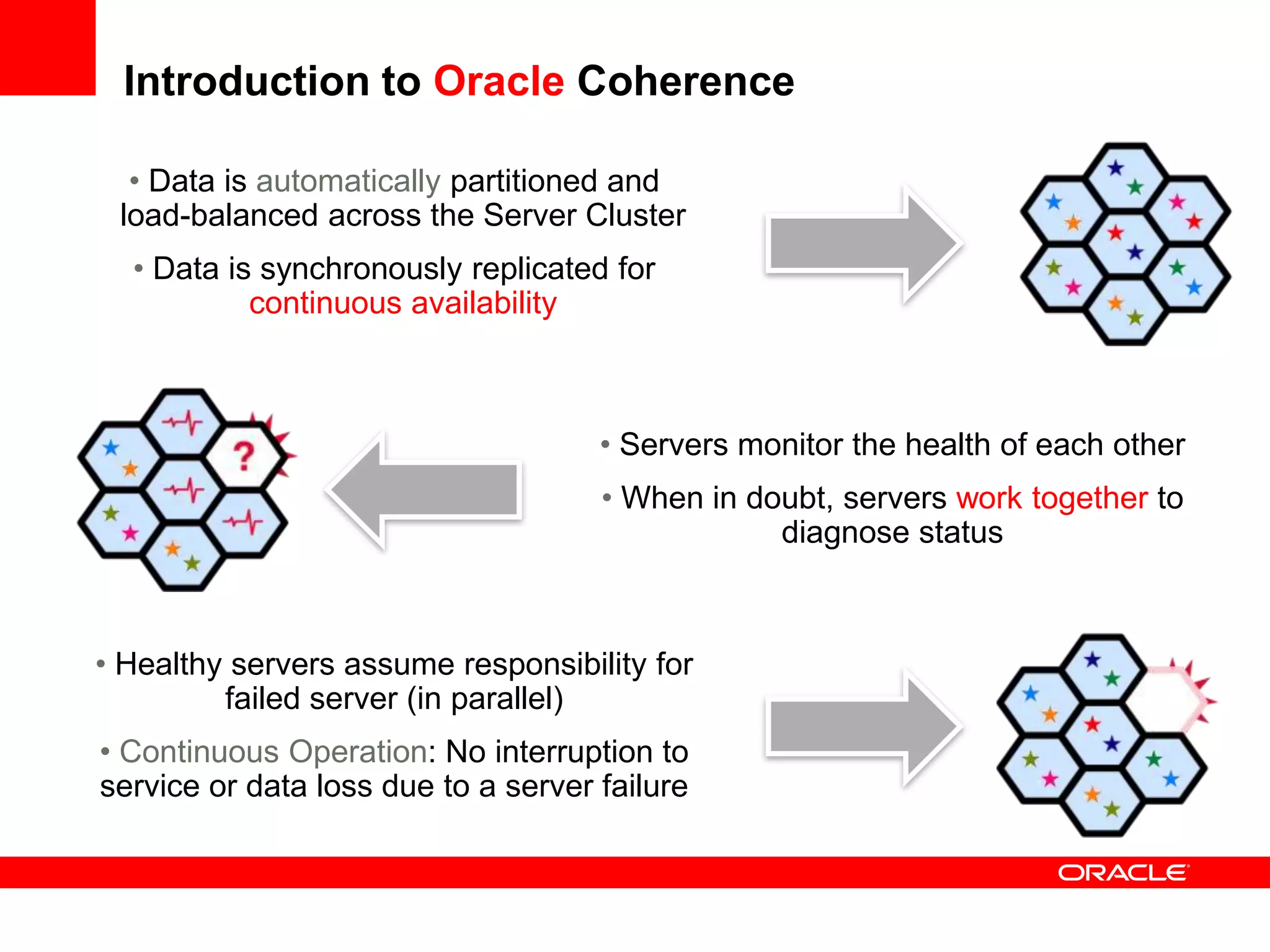
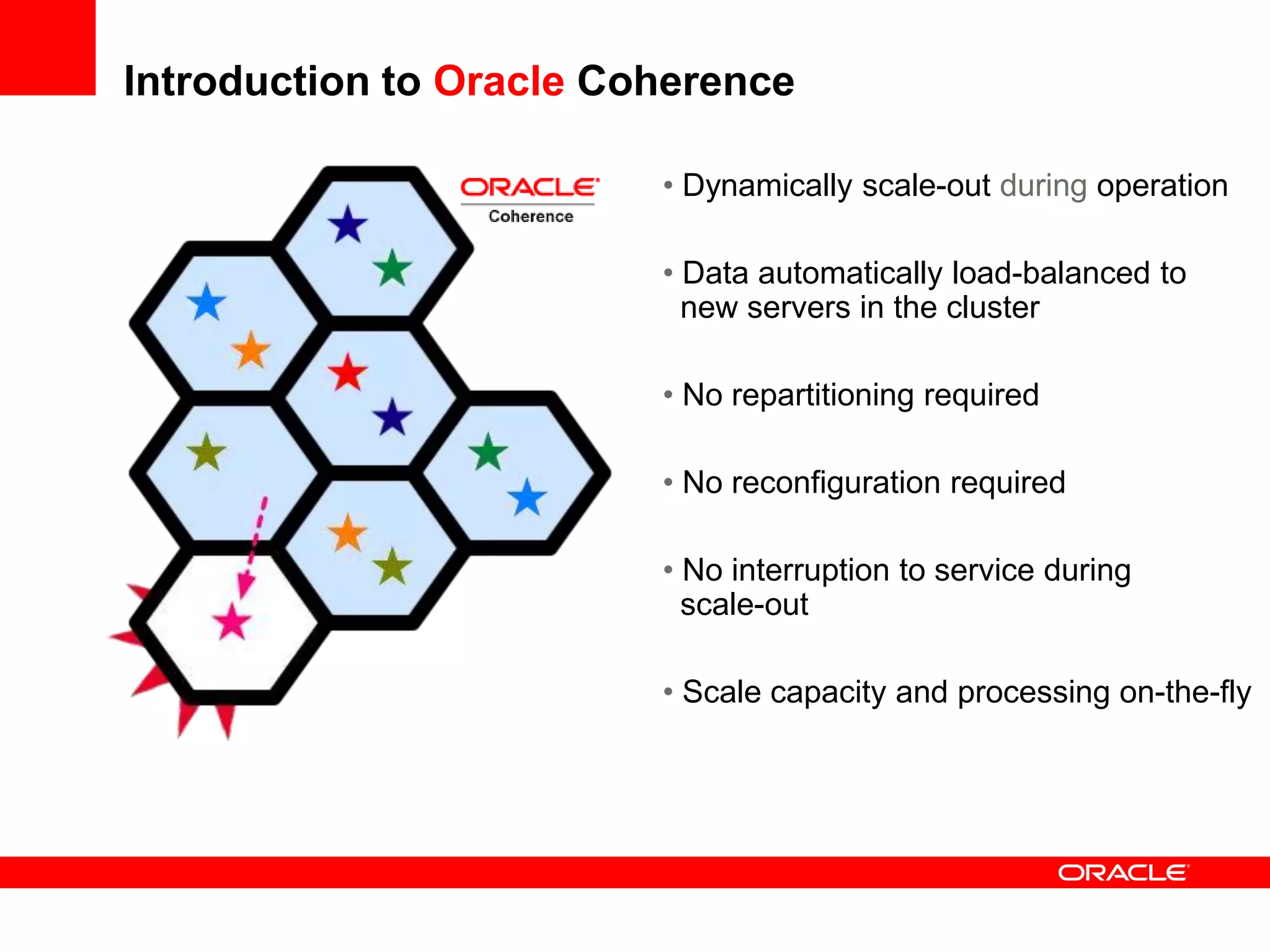
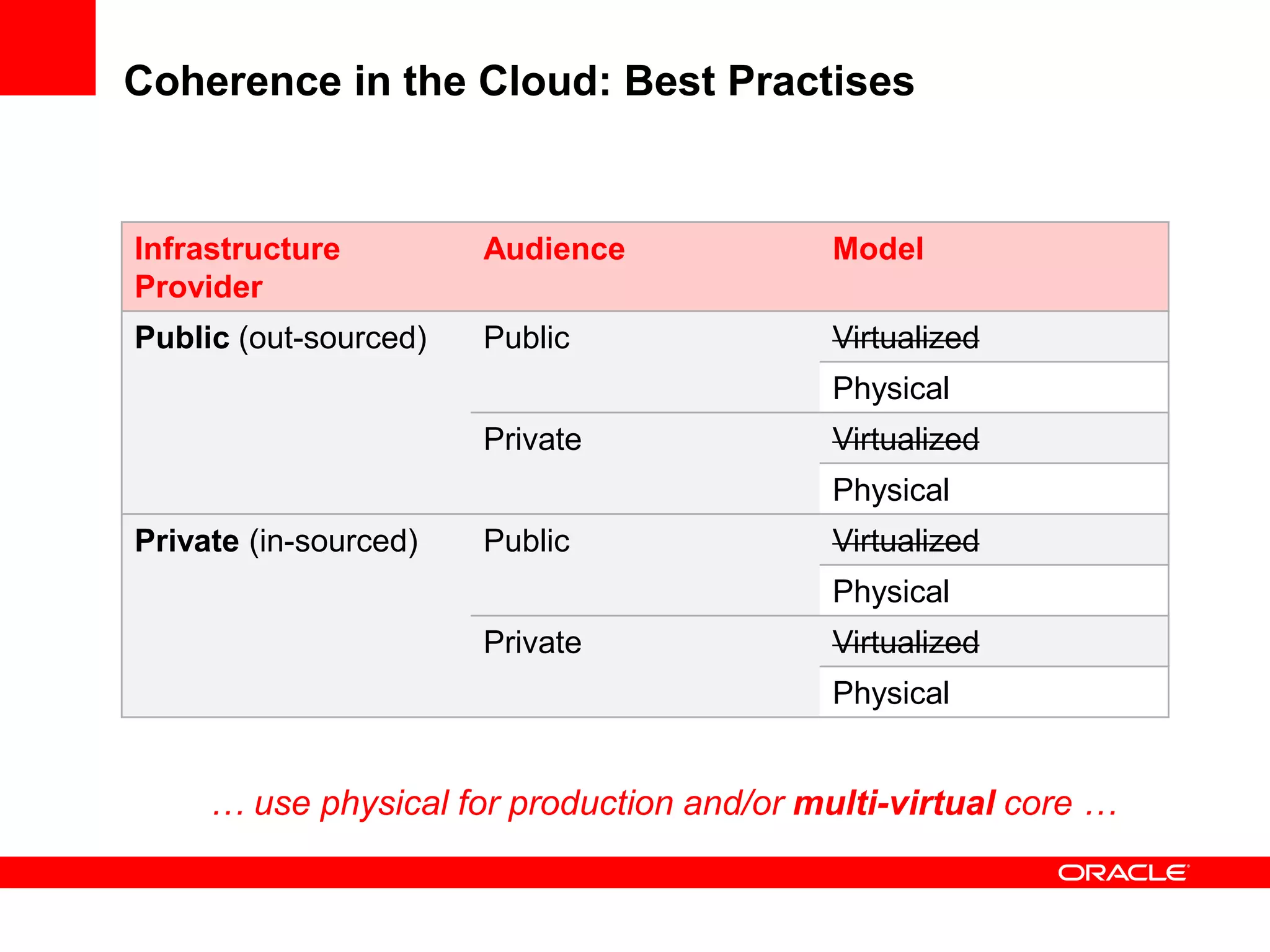
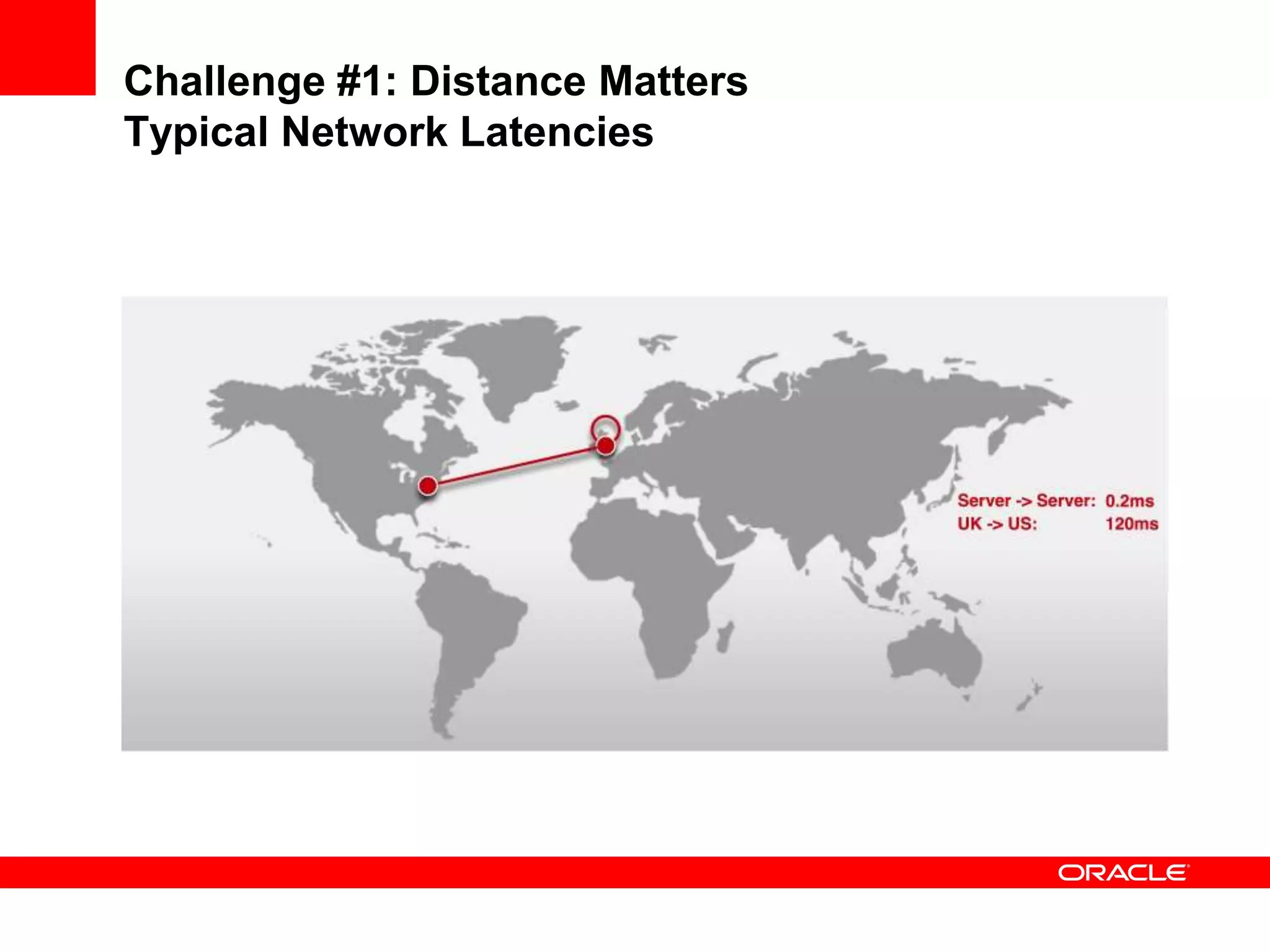
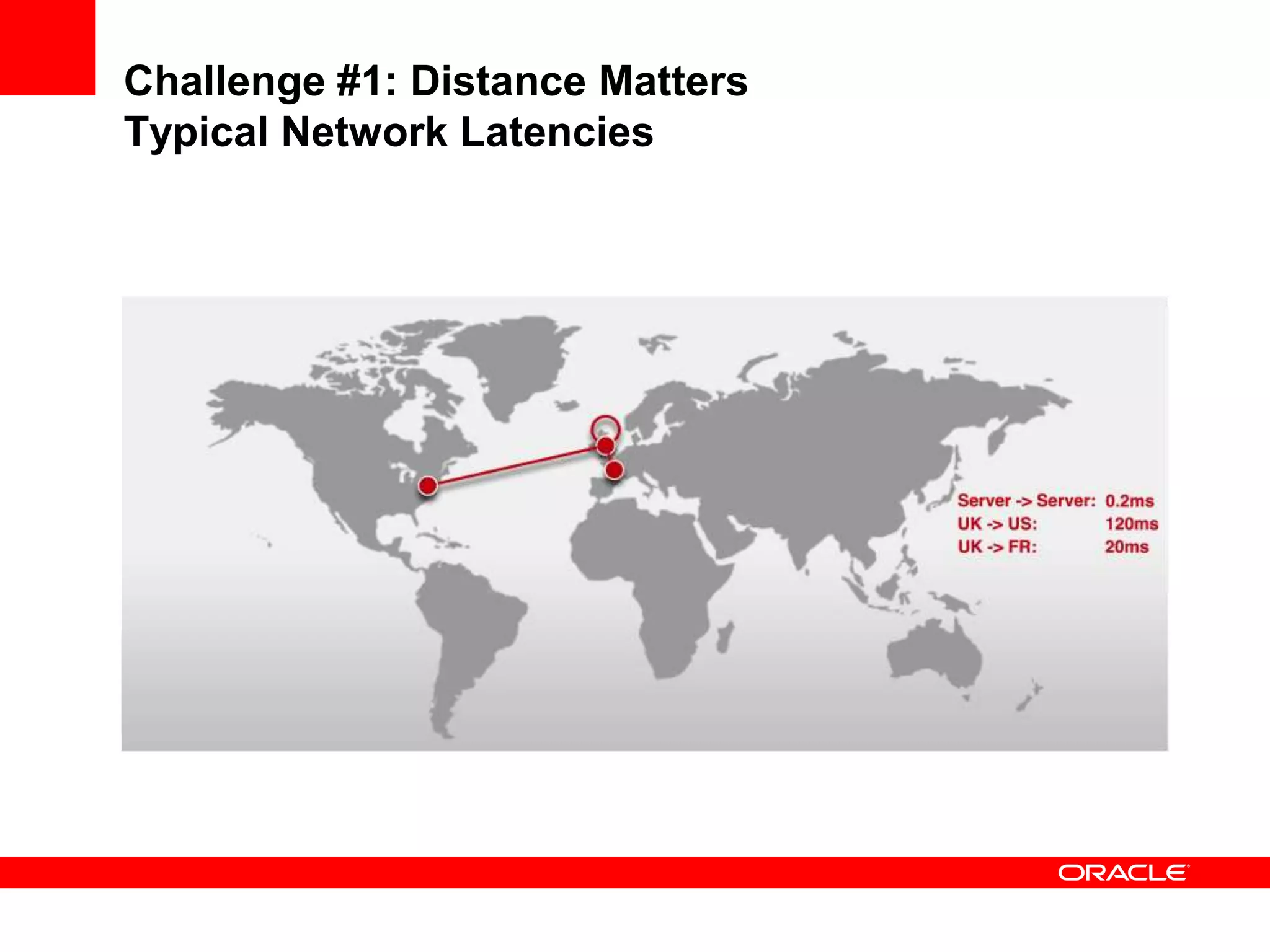
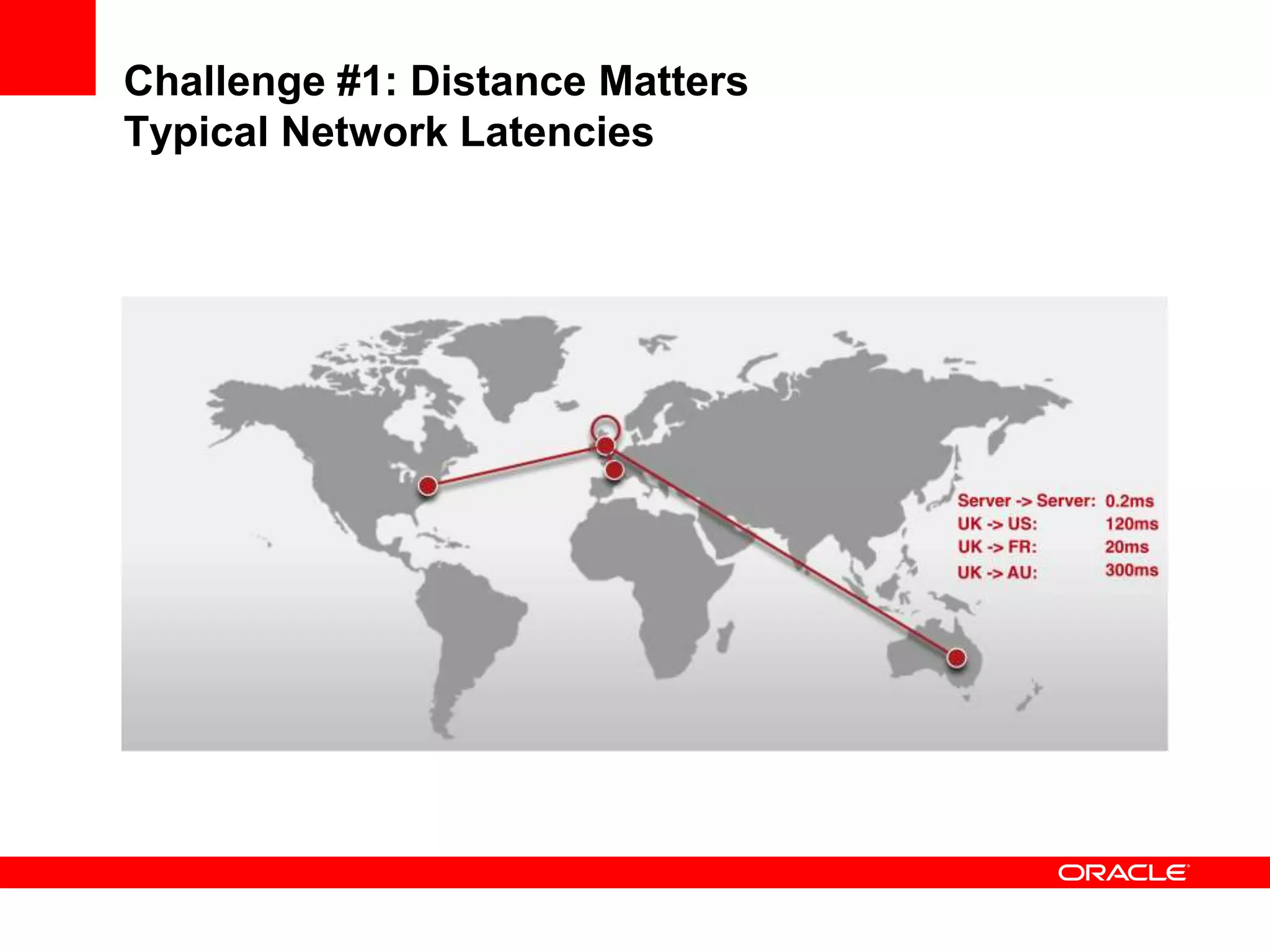
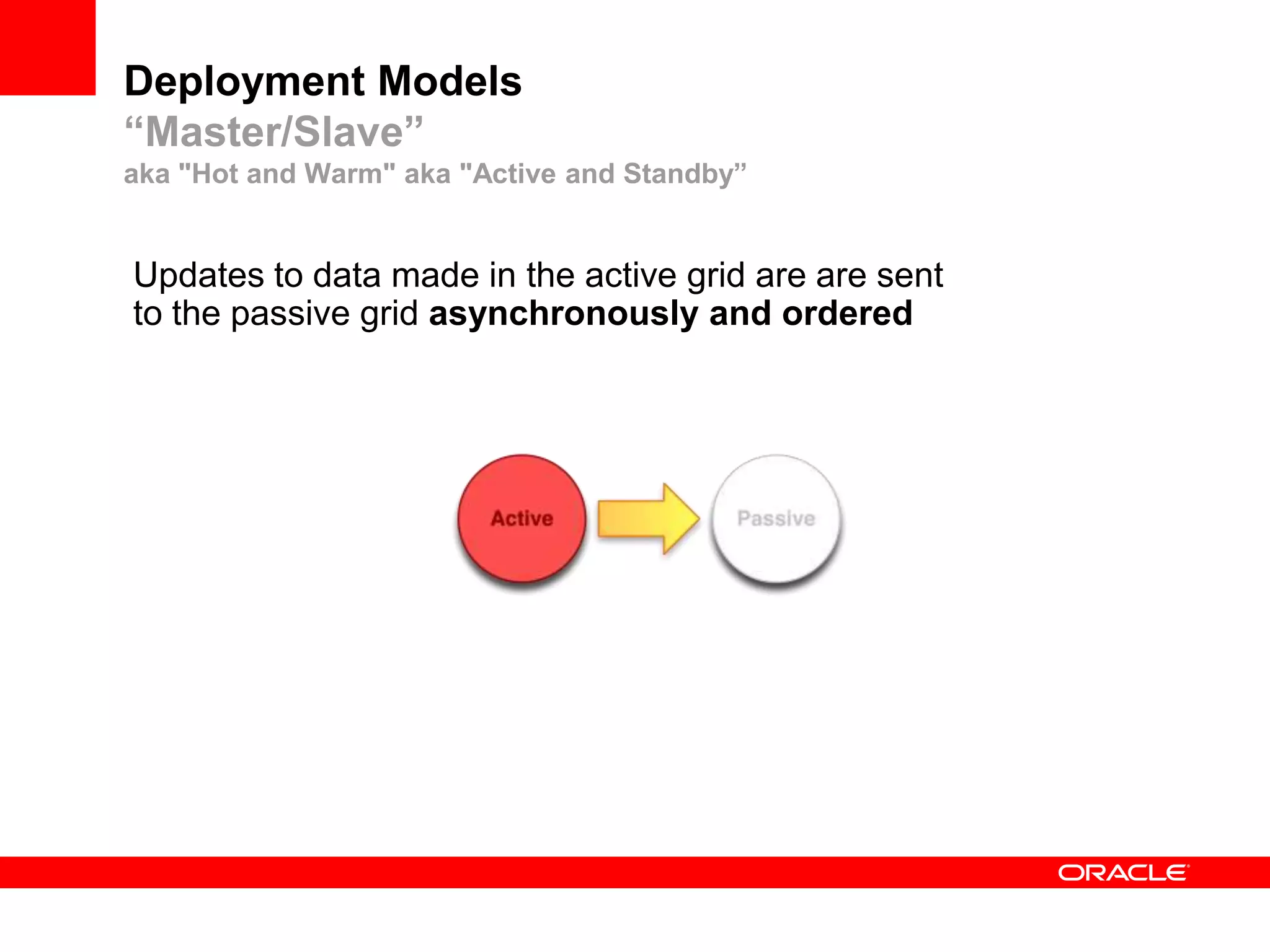
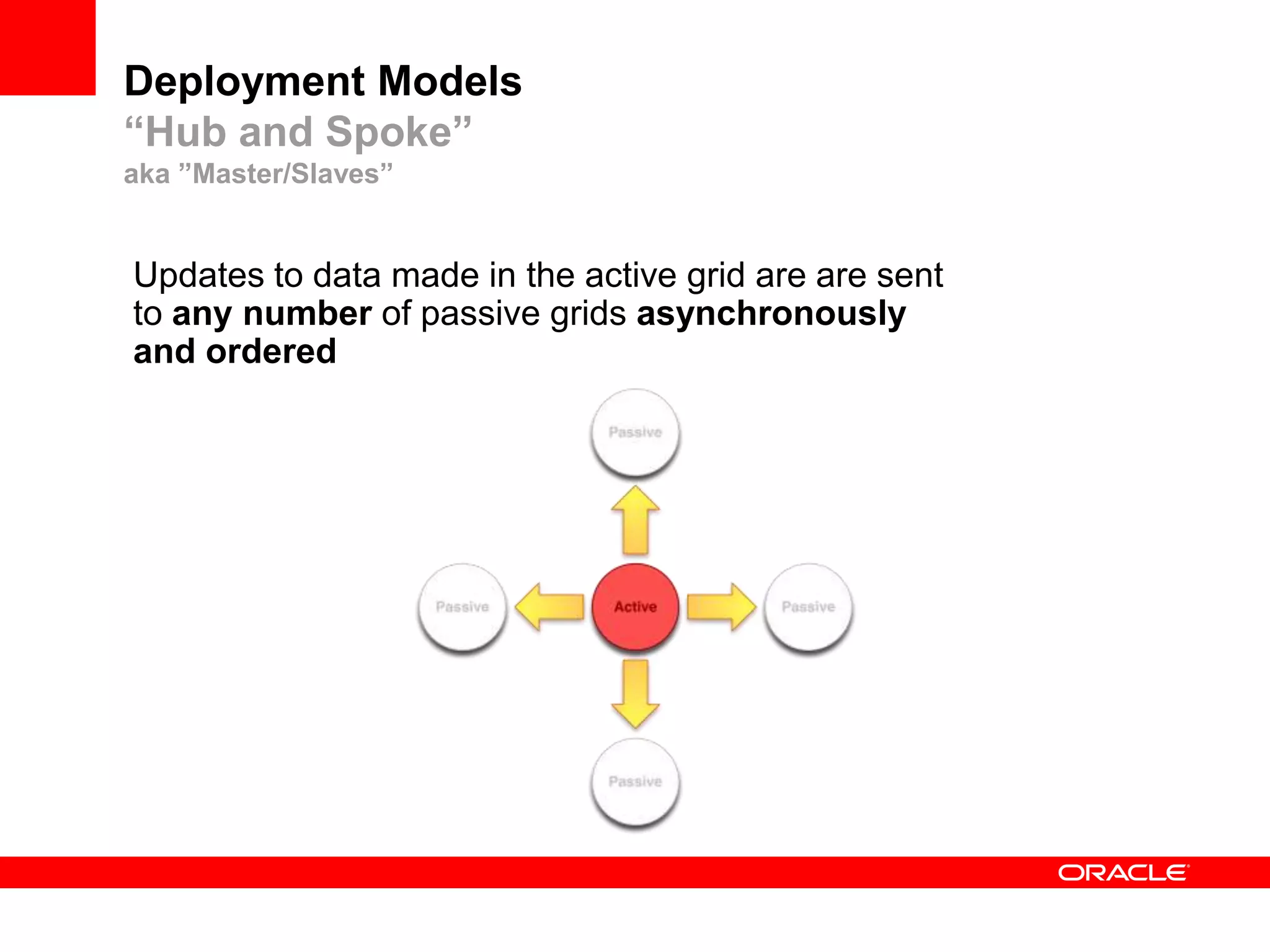
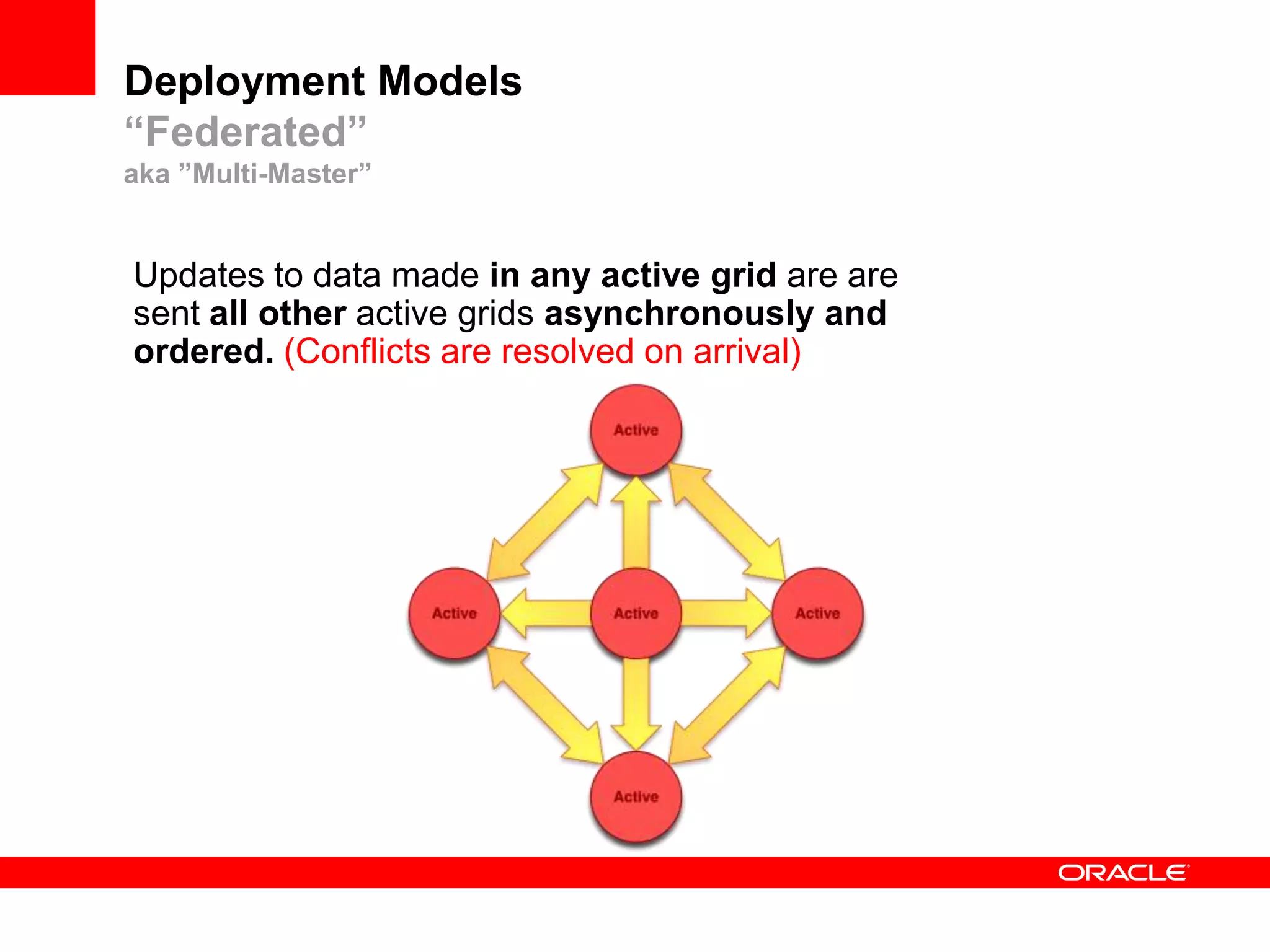
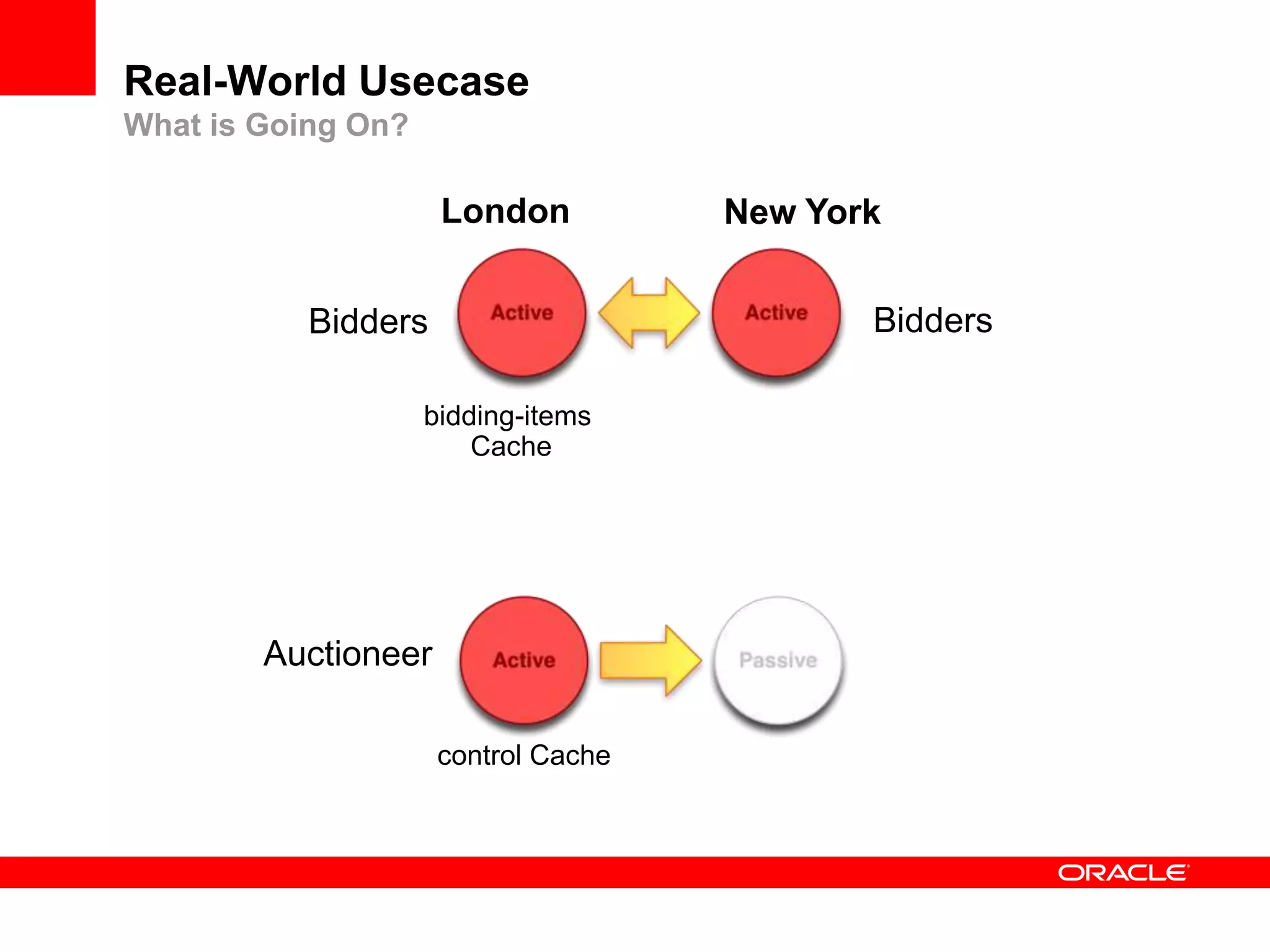
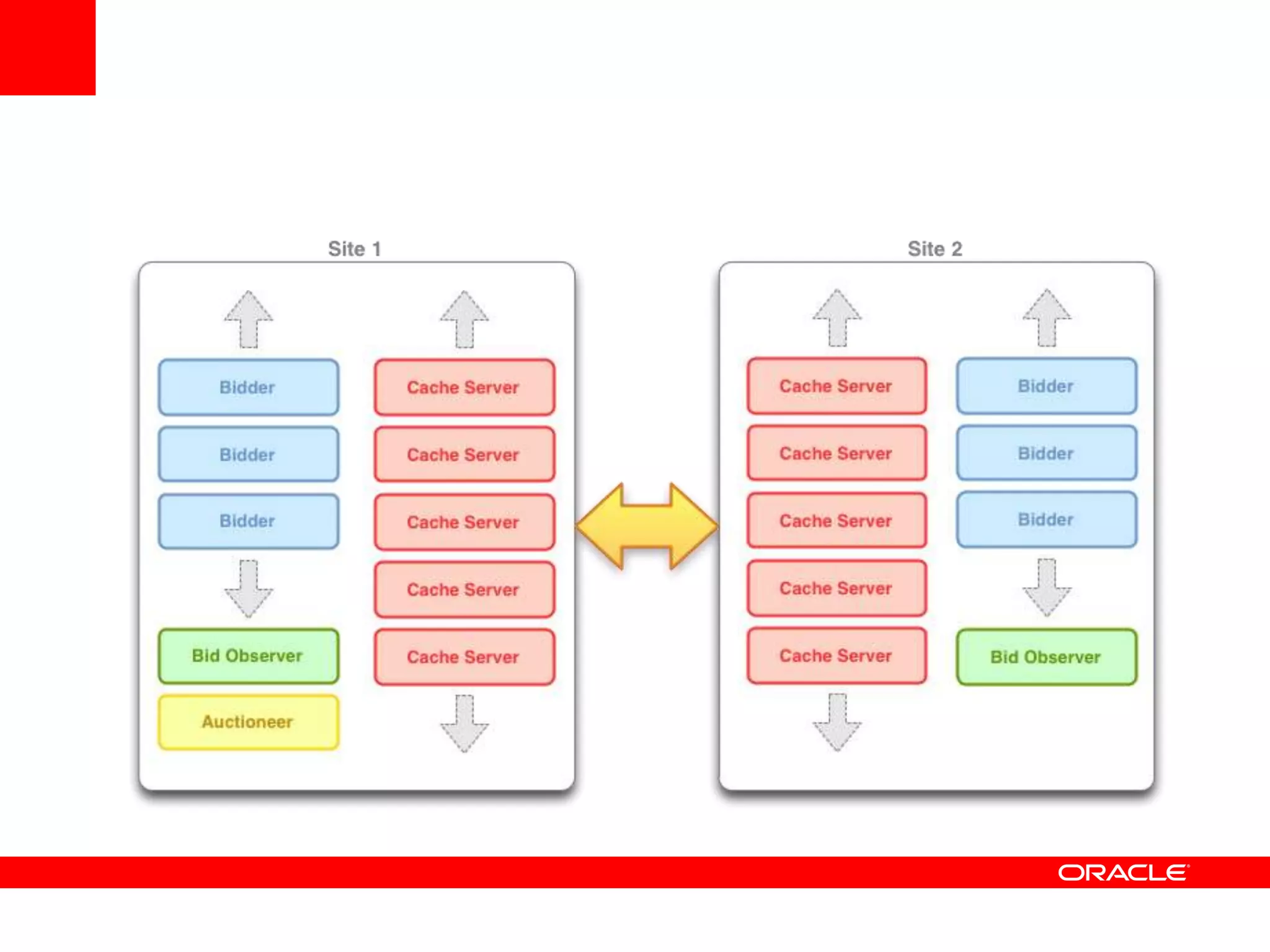
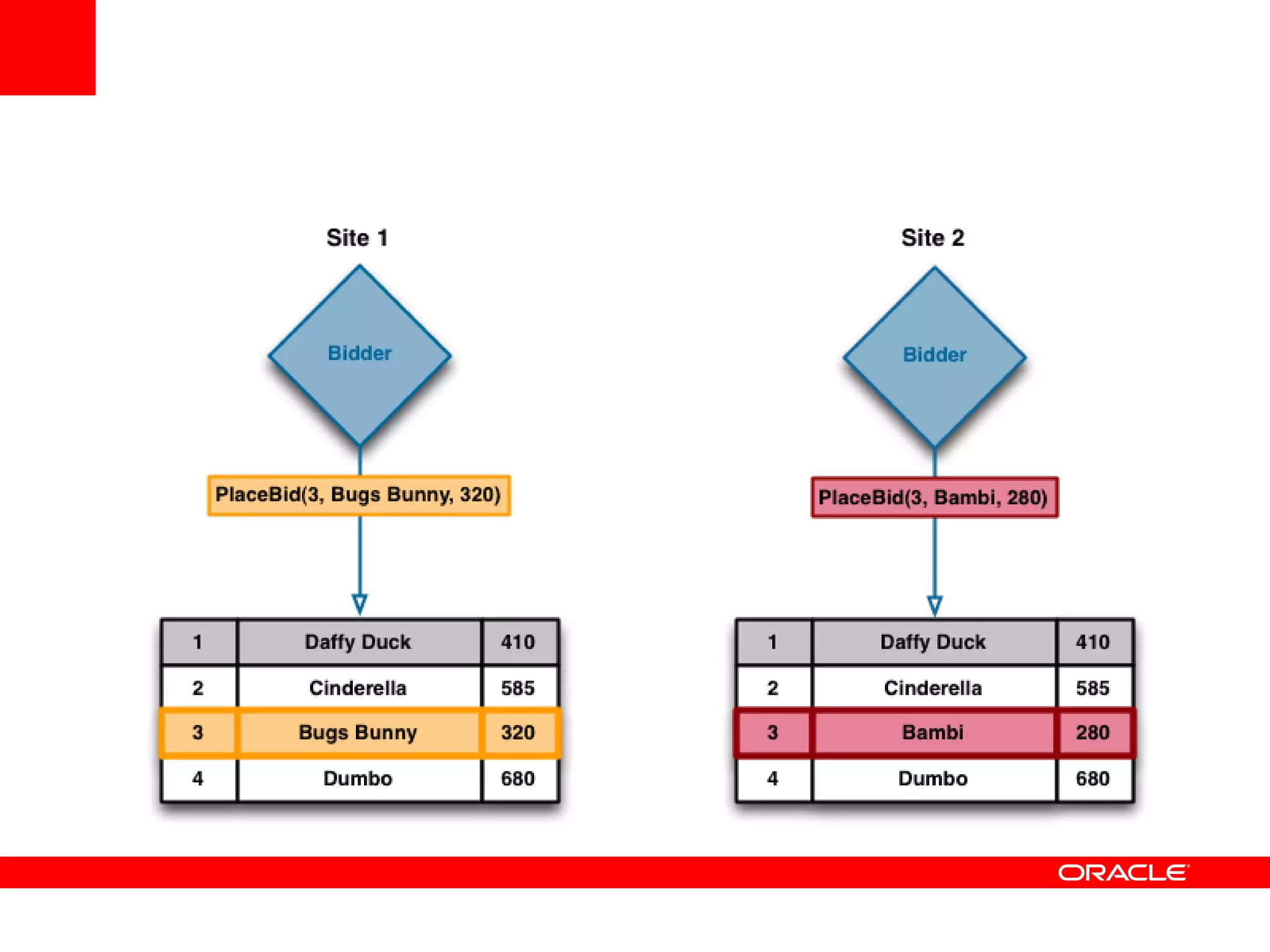
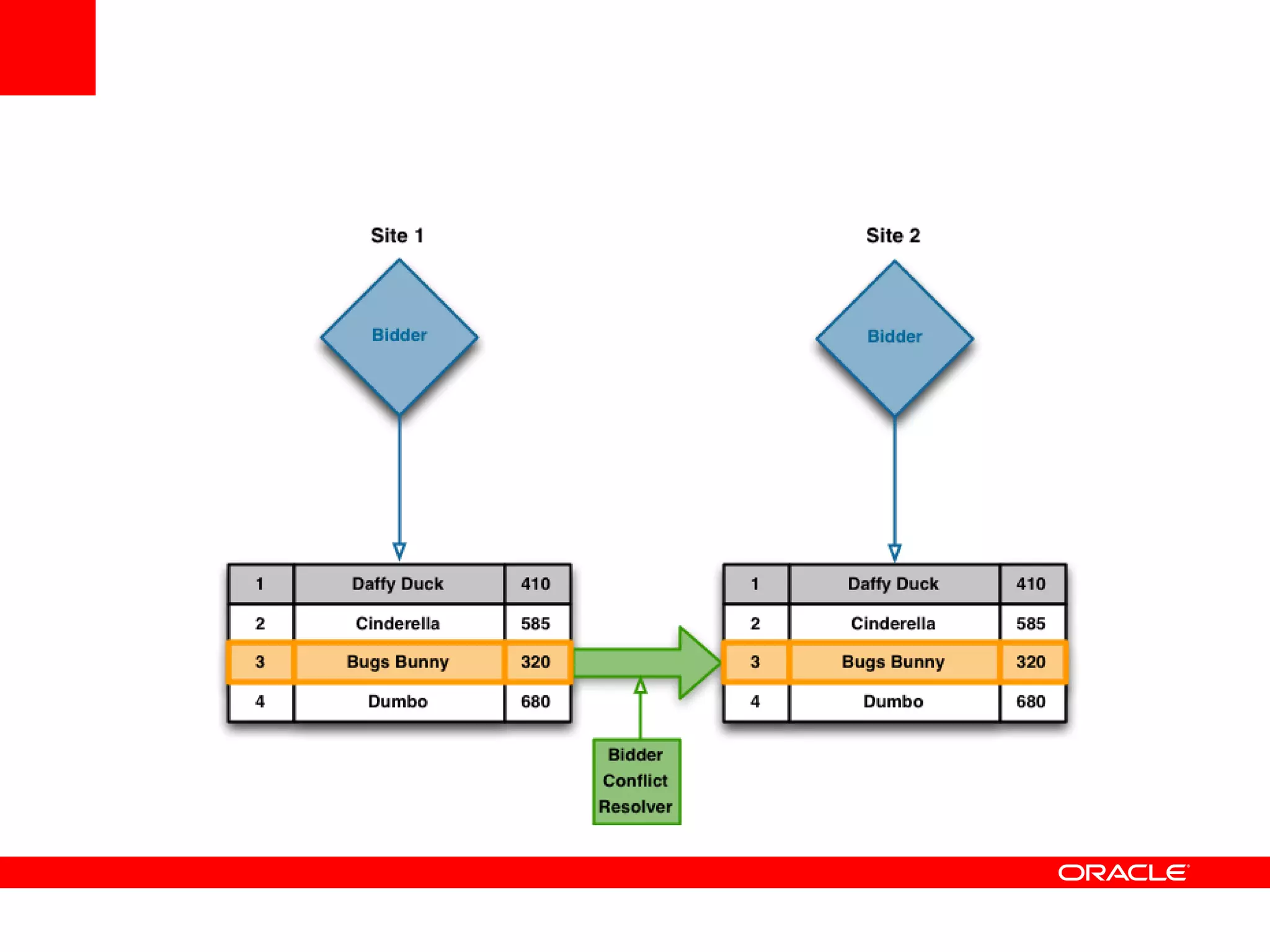
This document outlines a general product direction for connected clouds middleware and is intended for informational purposes only. It may not be incorporated into any contracts and does not commit Oracle to deliver any functionality. The document discusses making globally distributed stateful applications appear and operate as a single application across multiple cloud regions, providers and data centers. It also provides an agenda on challenges of multi-site deployments and introduces Oracle Coherence as a solution.