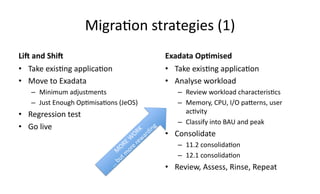
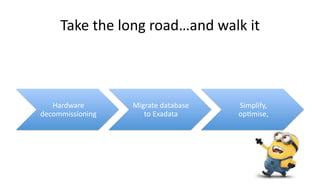
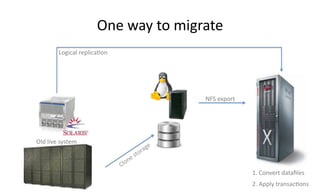
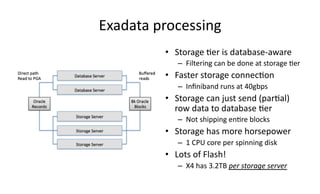
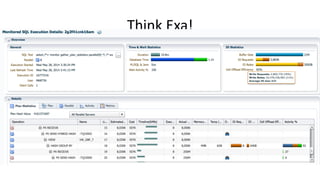
The document discusses Exadata and database migration strategies. It provides information on an Oracle consulting partner called Enkitec that specializes in Exadata implementations. The document discusses reasons for migrating databases to Exadata, such as hardware end of life. It also summarizes strategies for migrating databases to Exadata, such as lift and shift migrations with minimal changes or more optimized migrations after analyzing the workload. The document further discusses Exadata features like Smart Scan and Hybrid Columnar Compression that provide performance and storage benefits.