

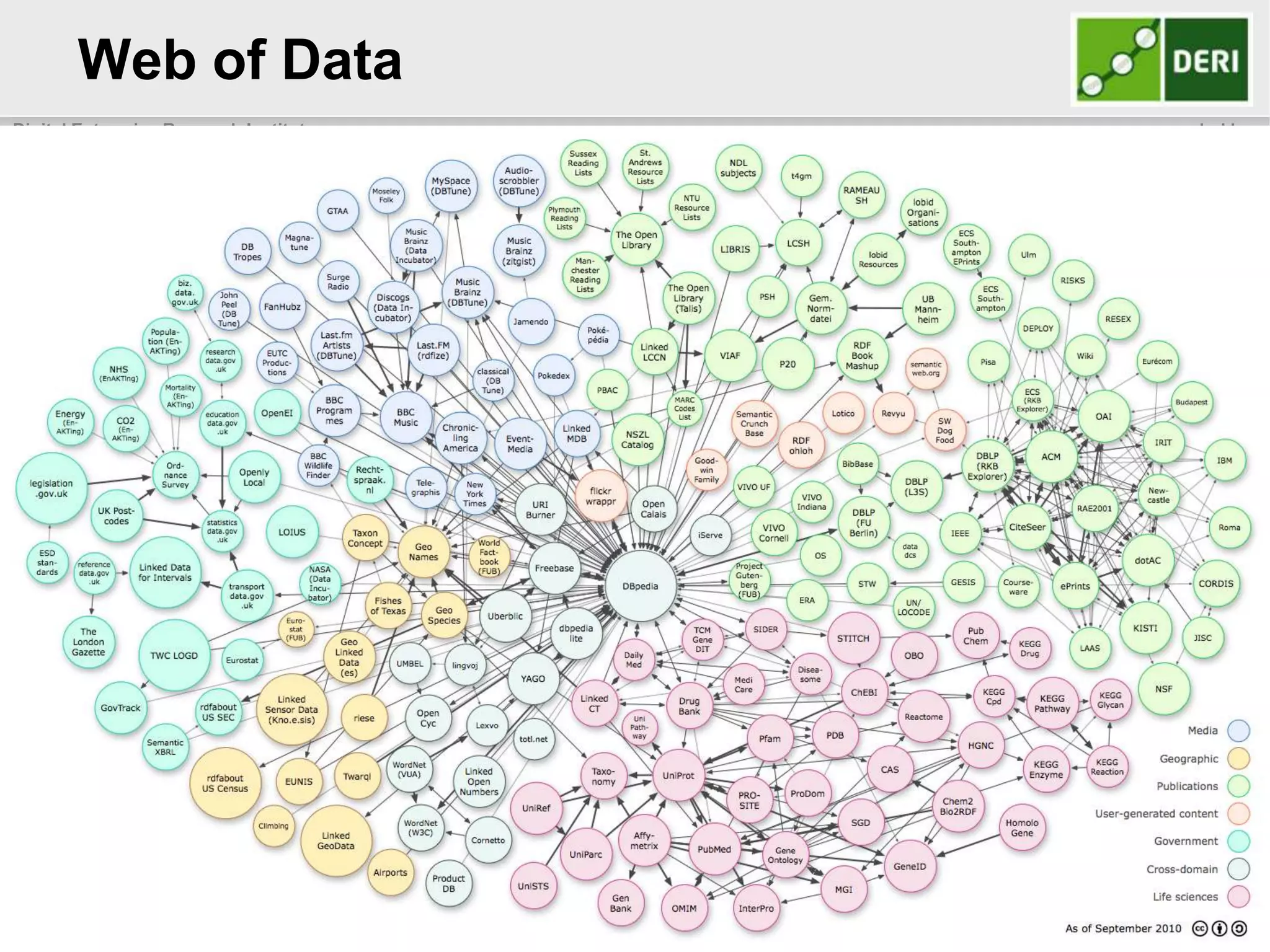


















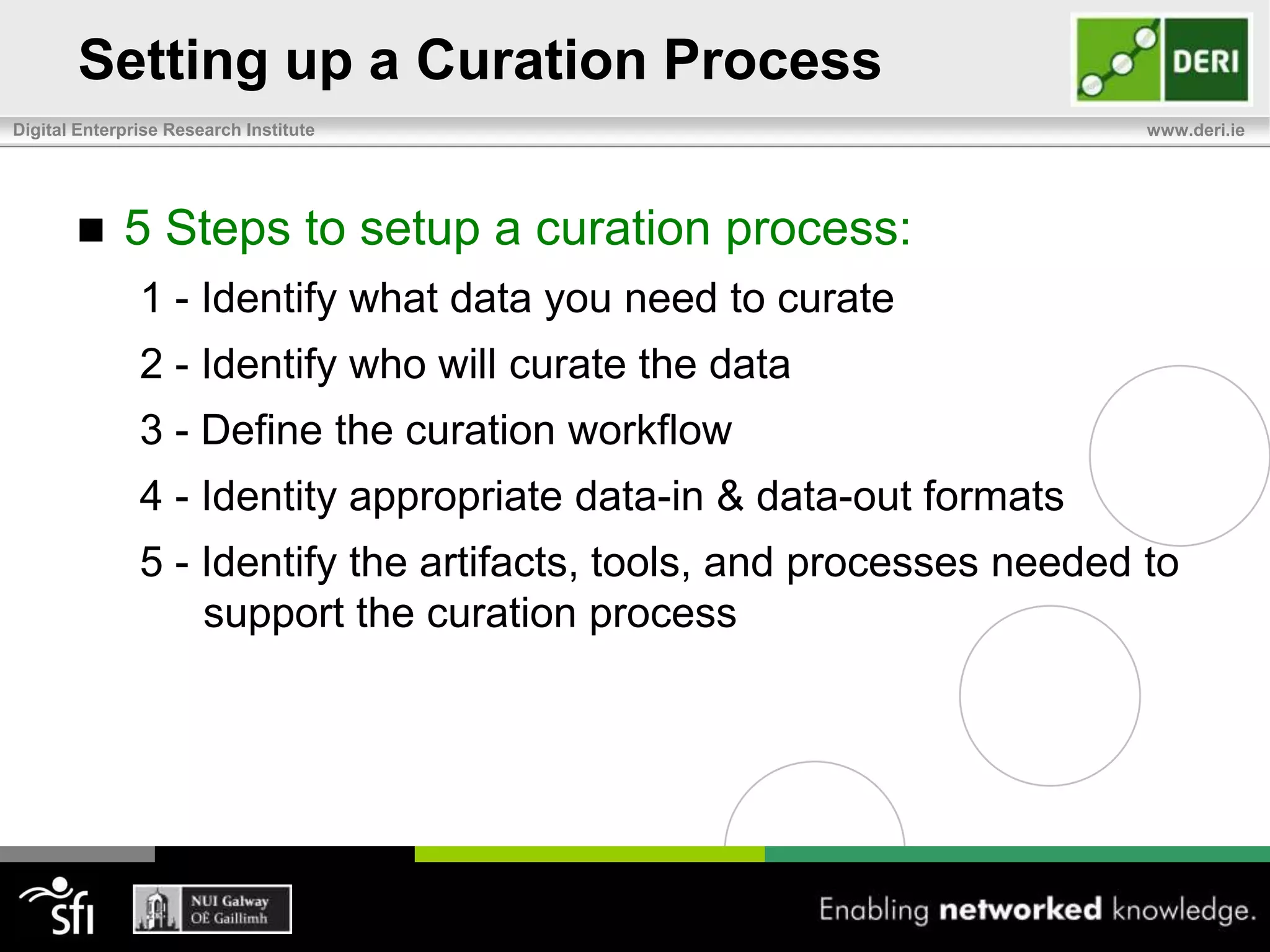


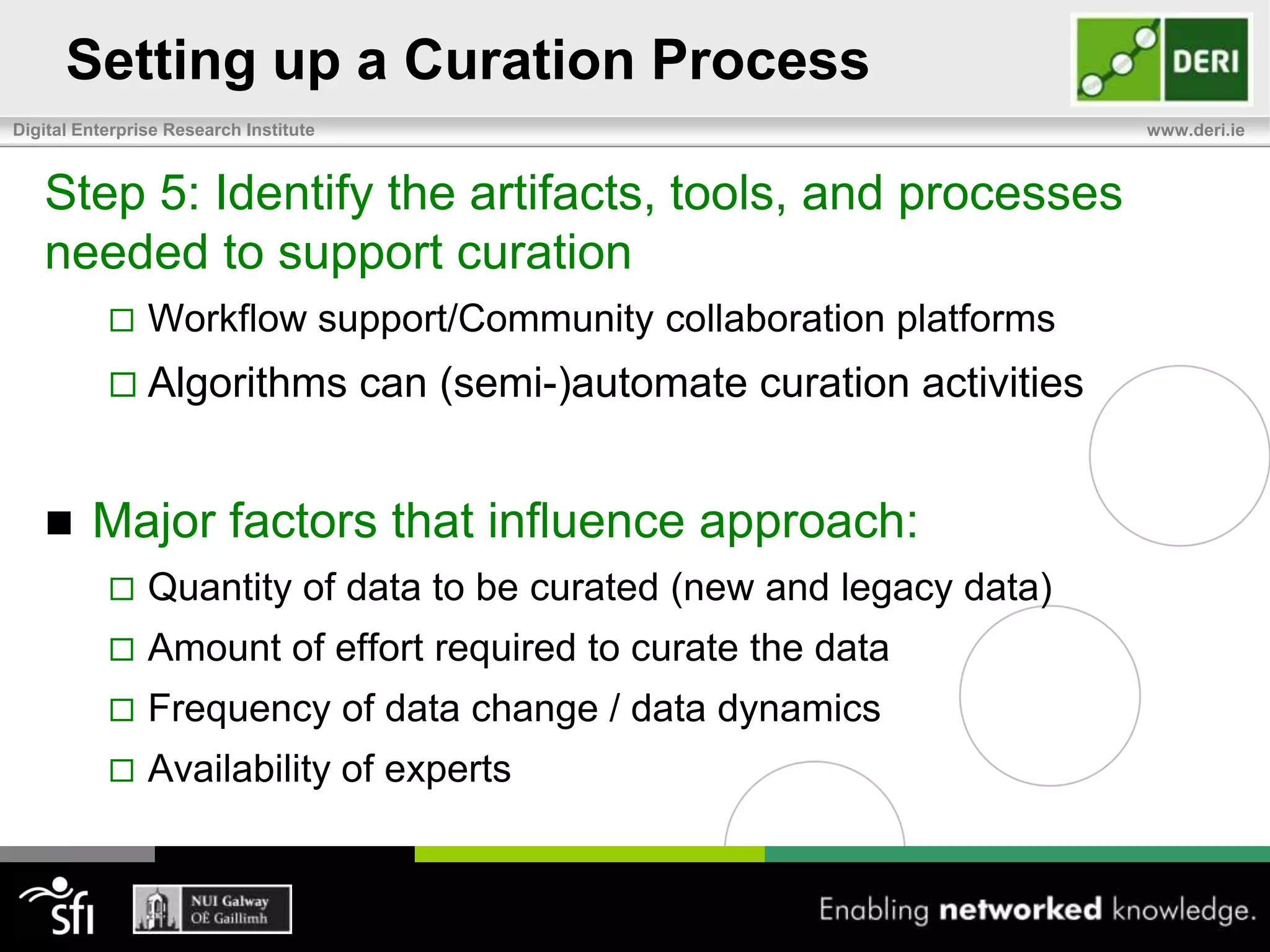















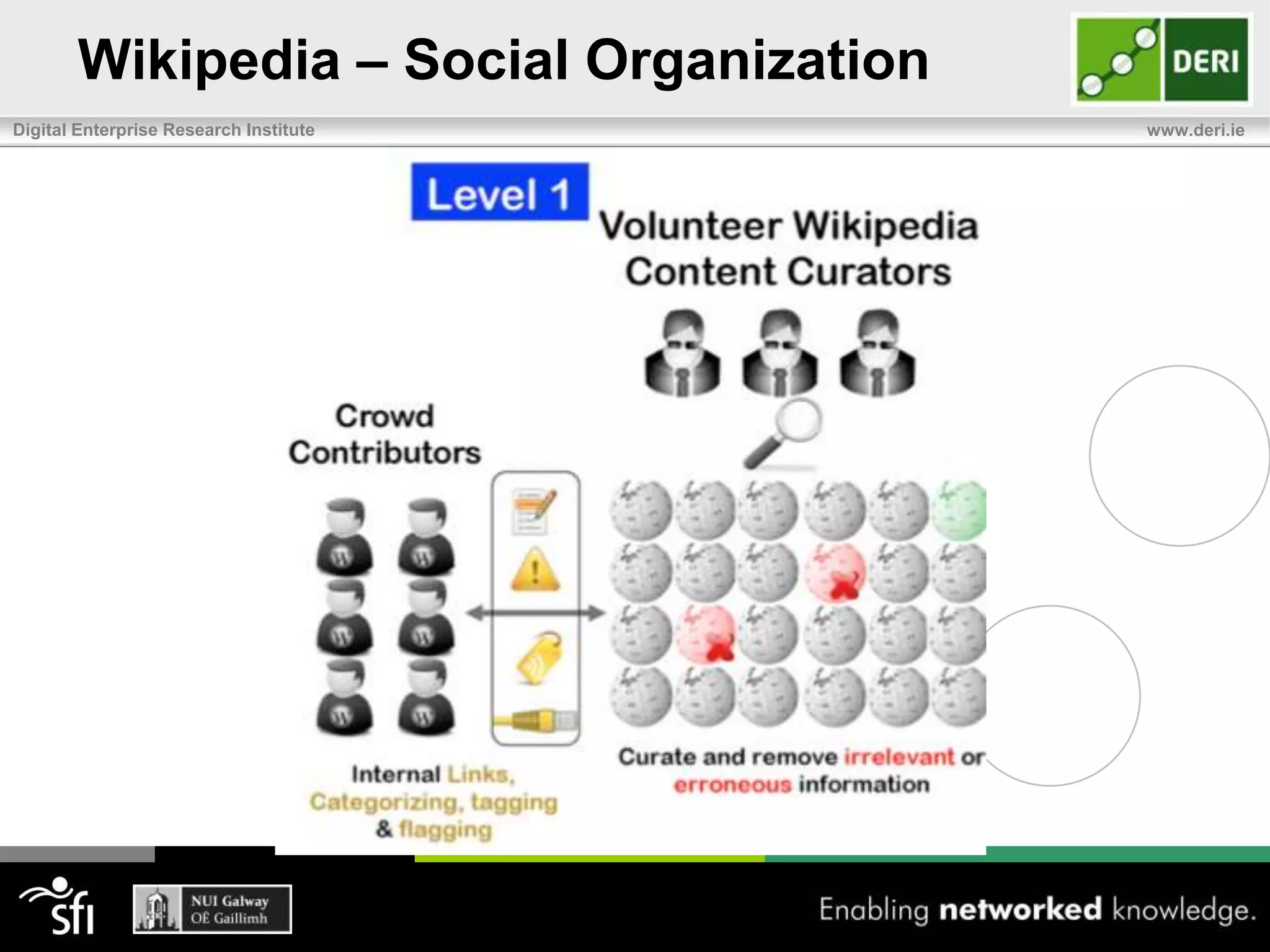




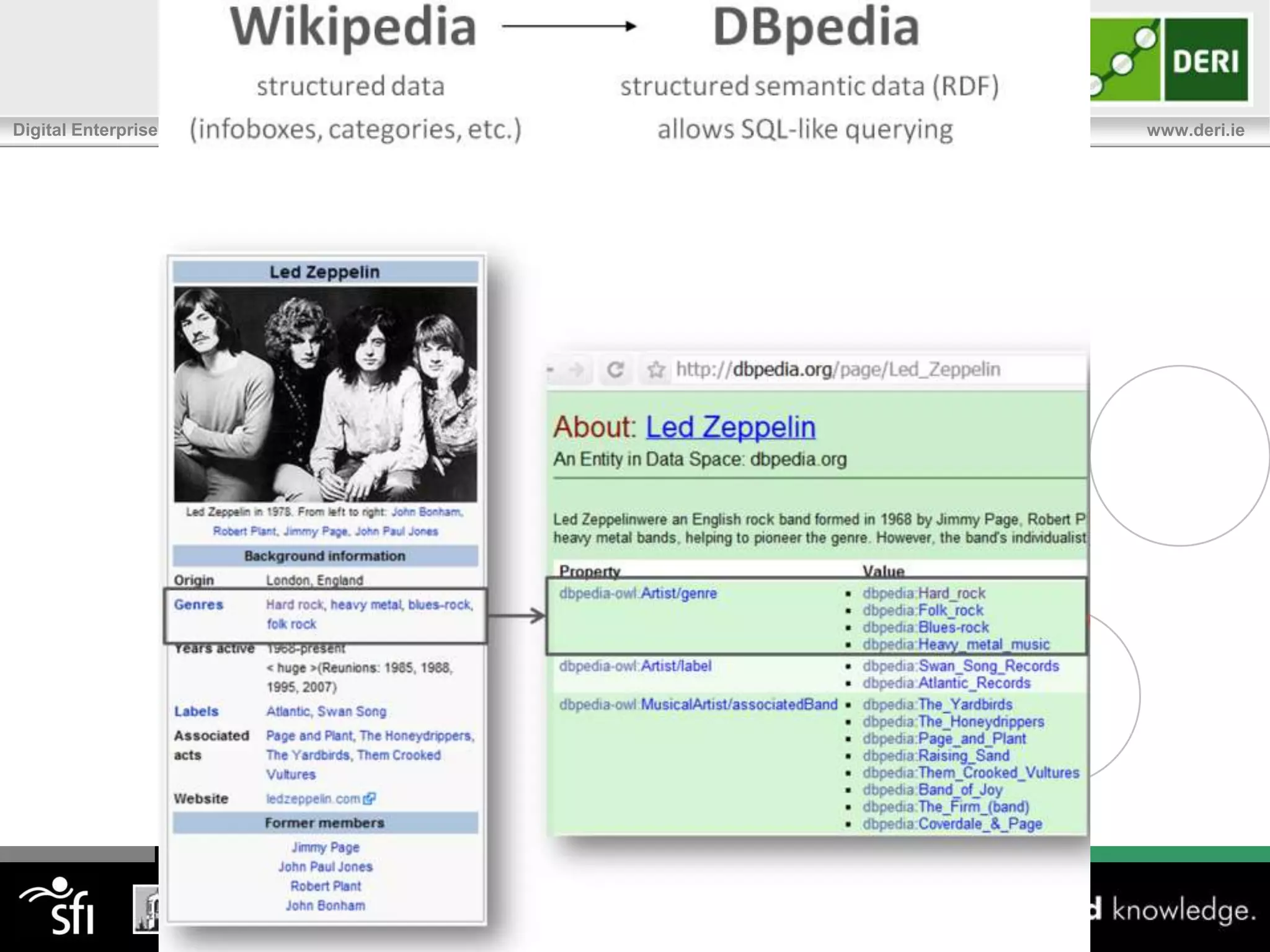










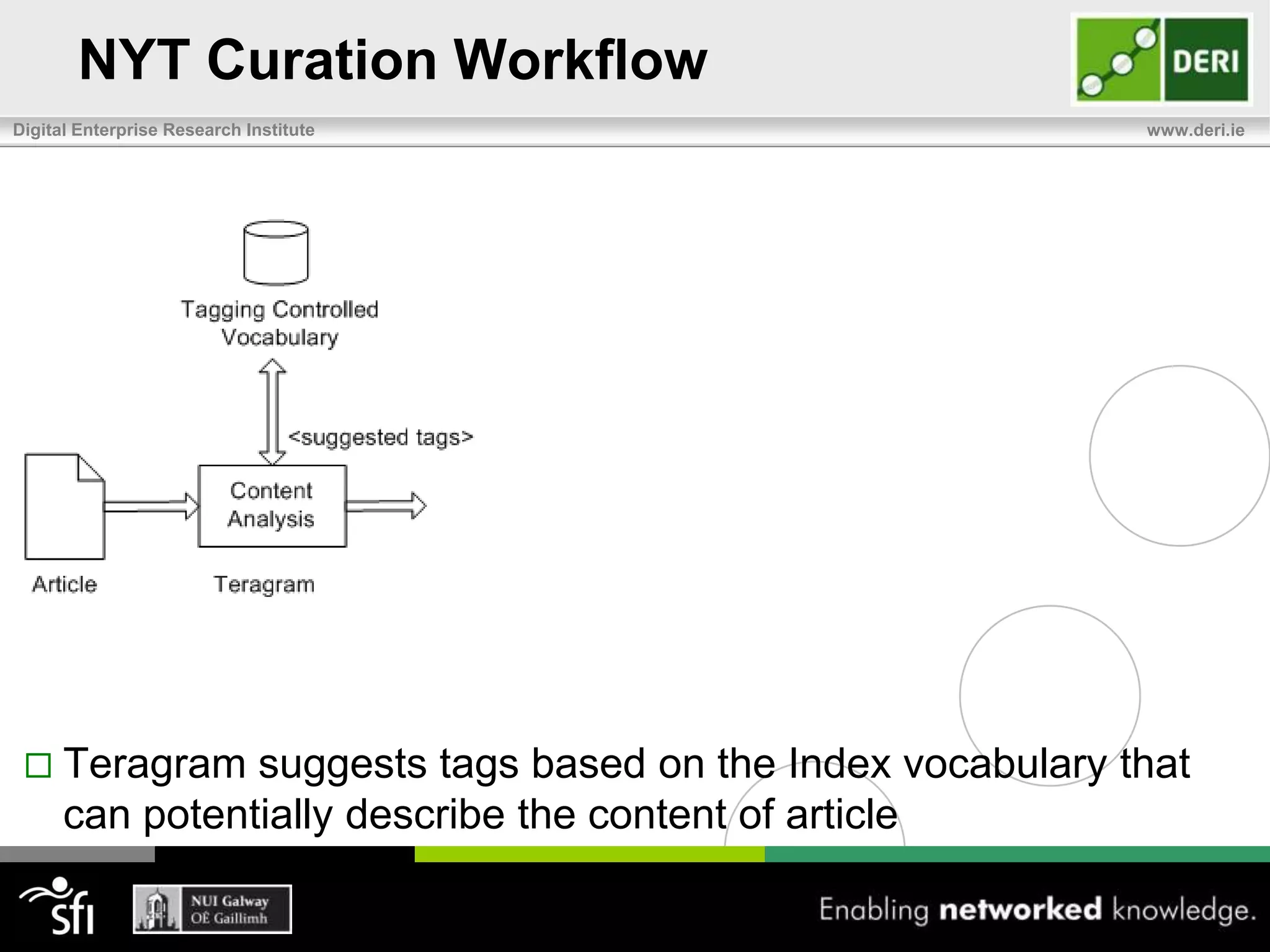
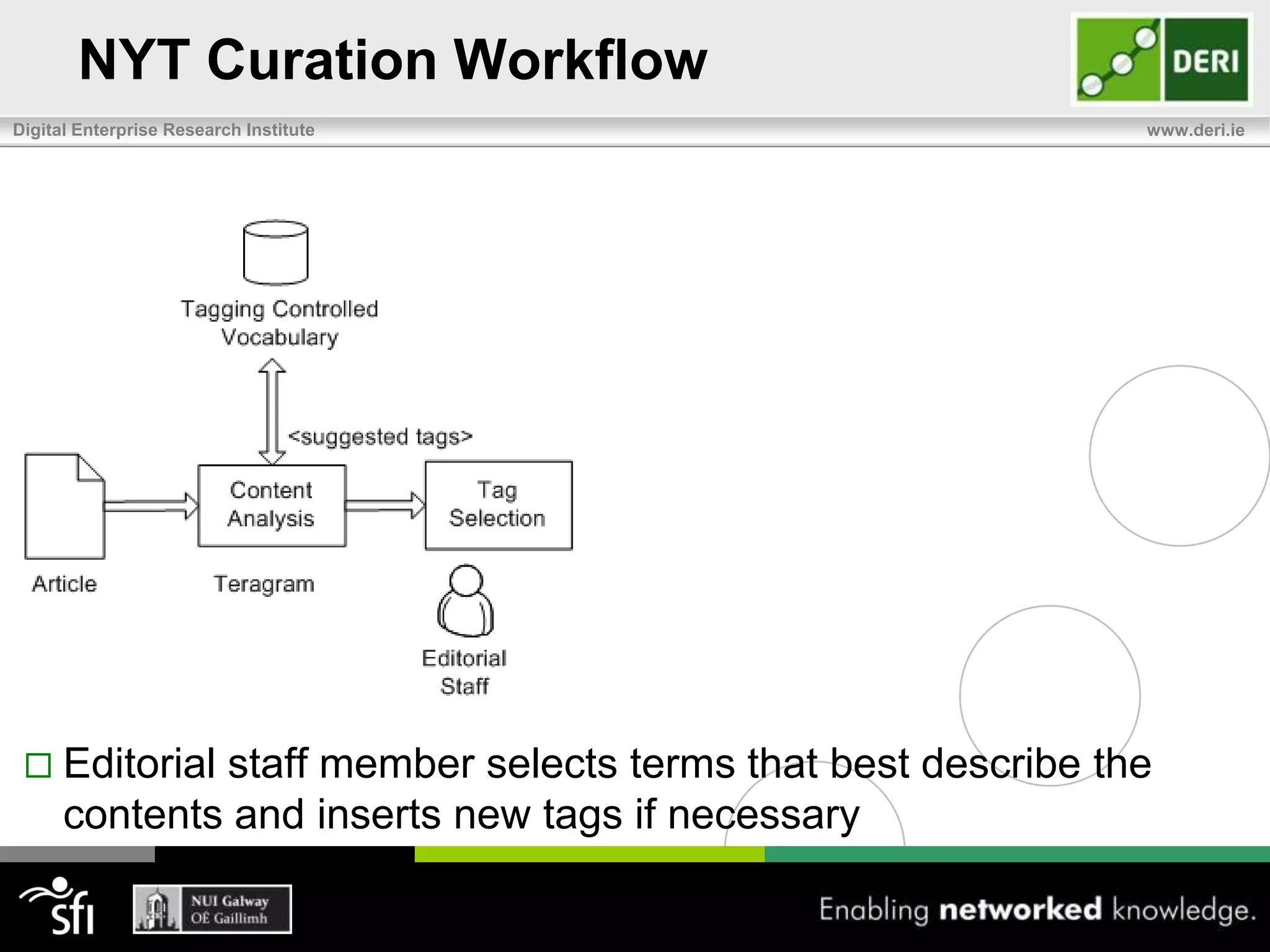
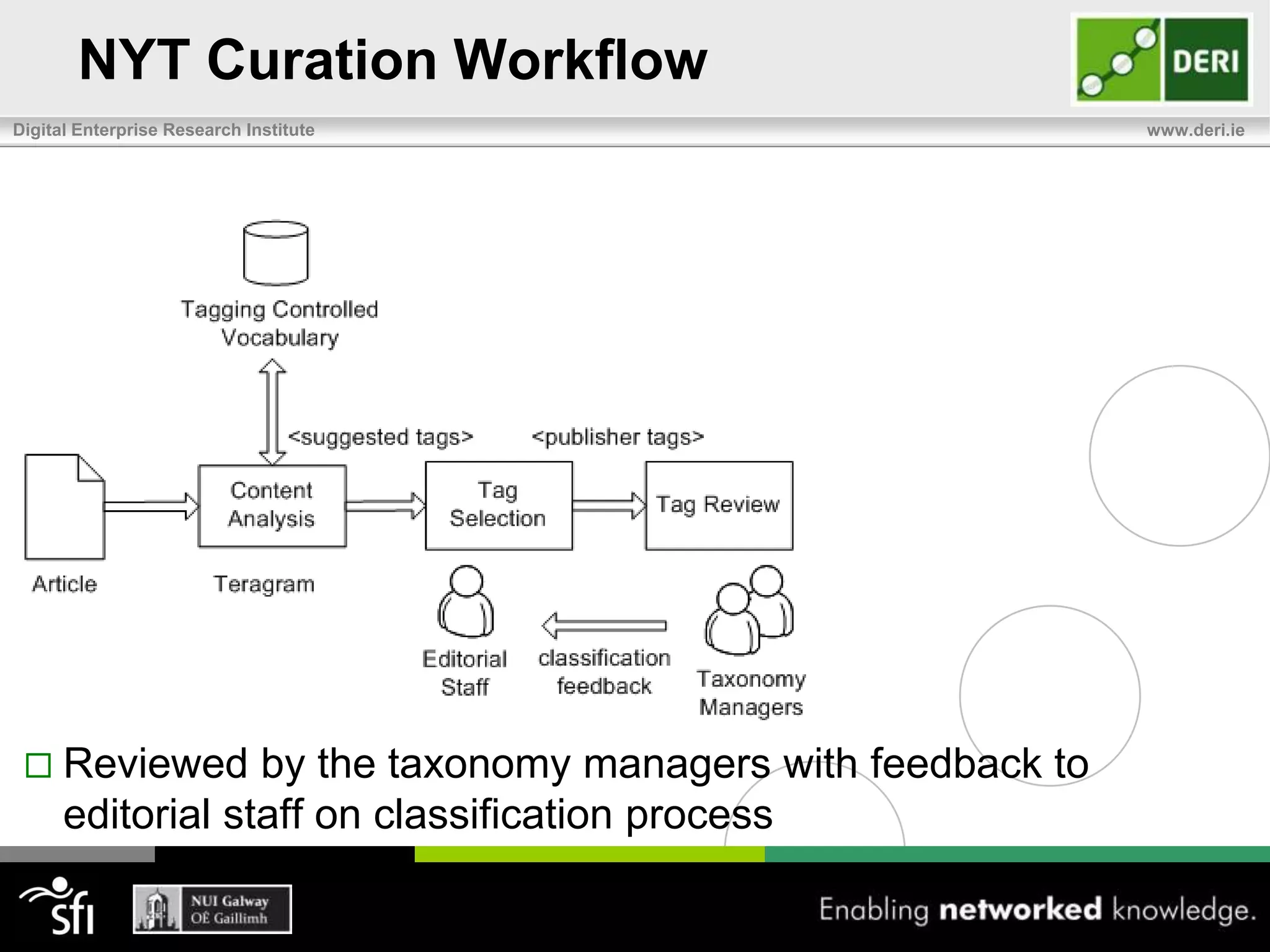
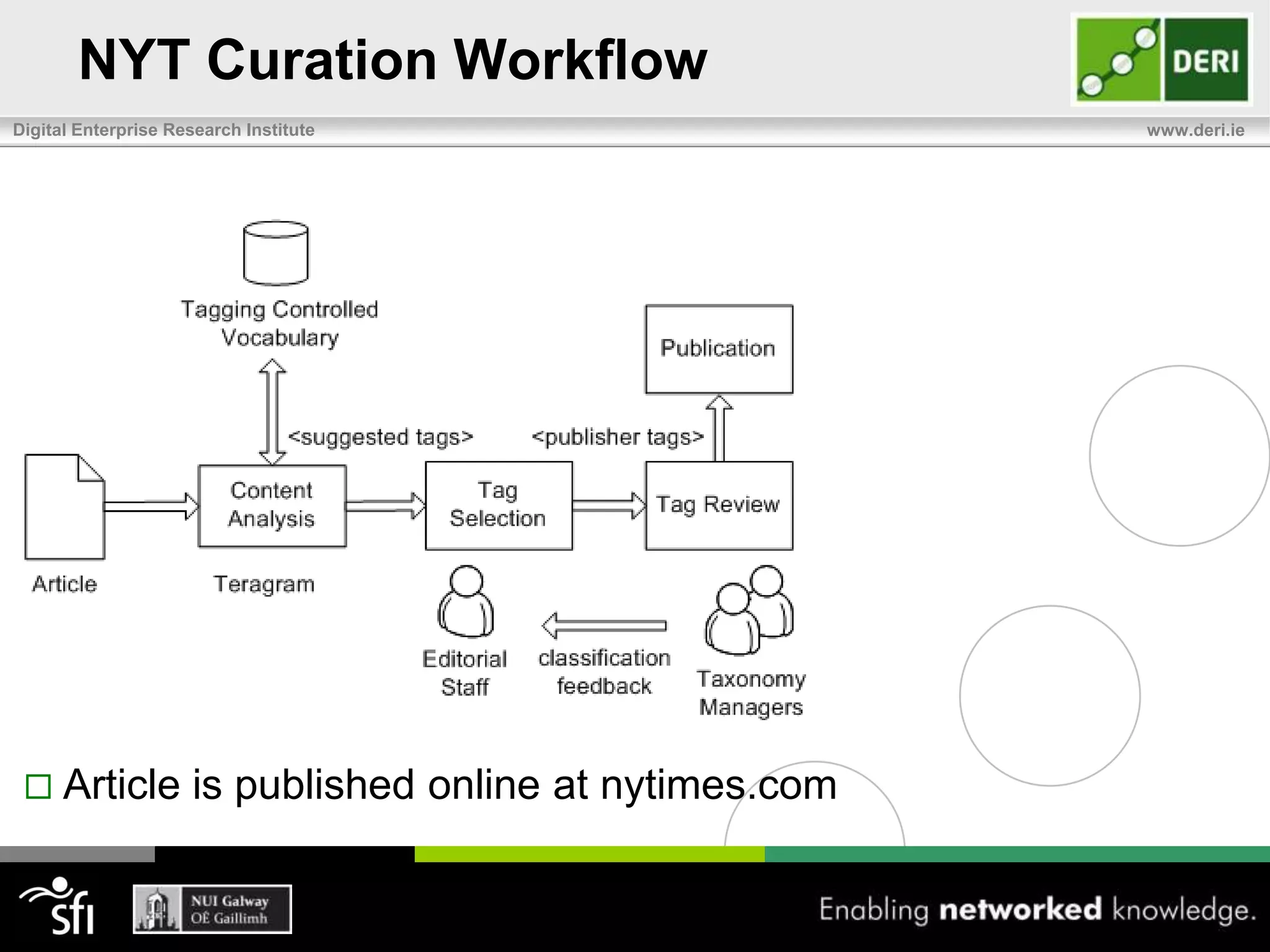
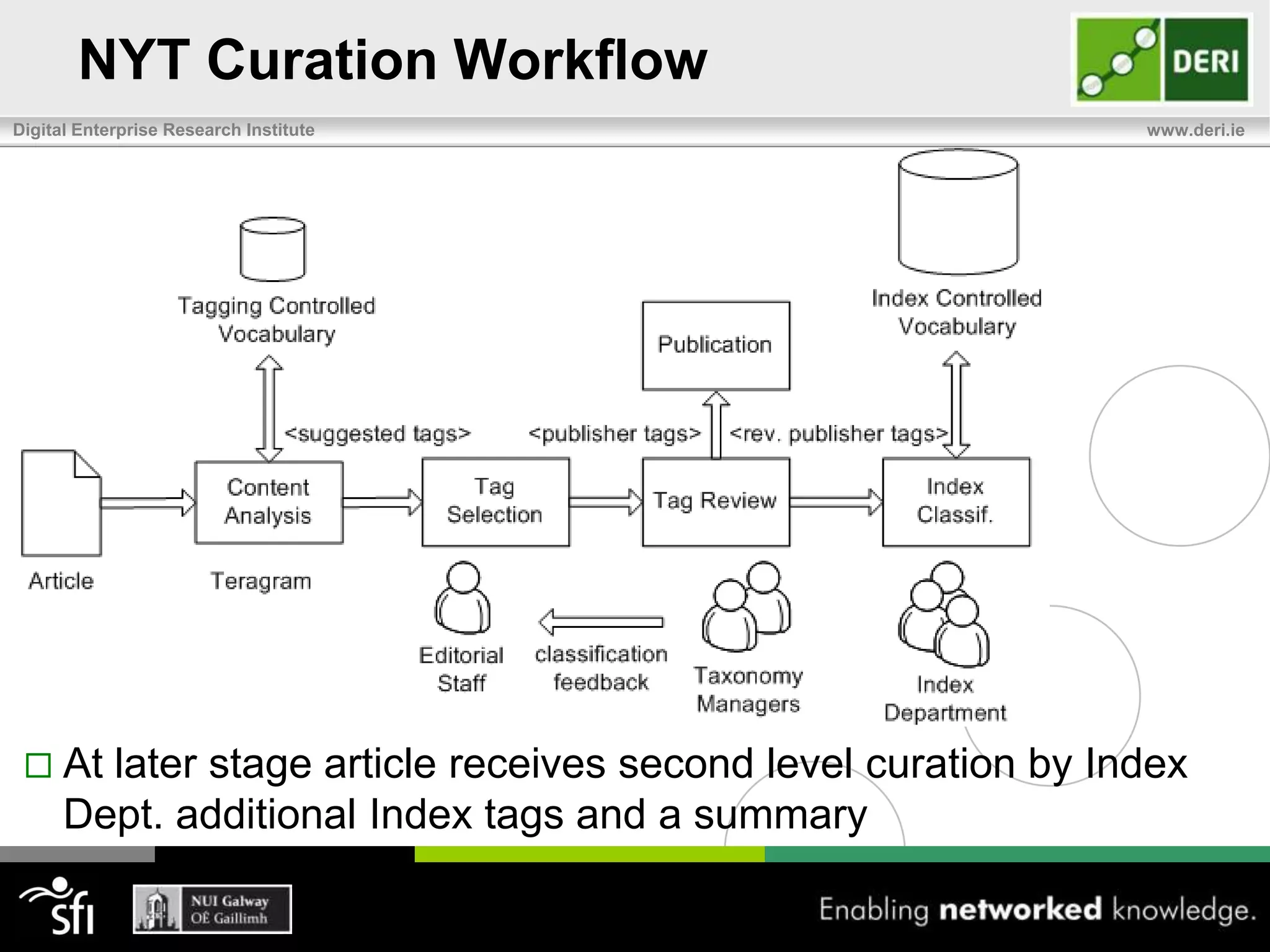
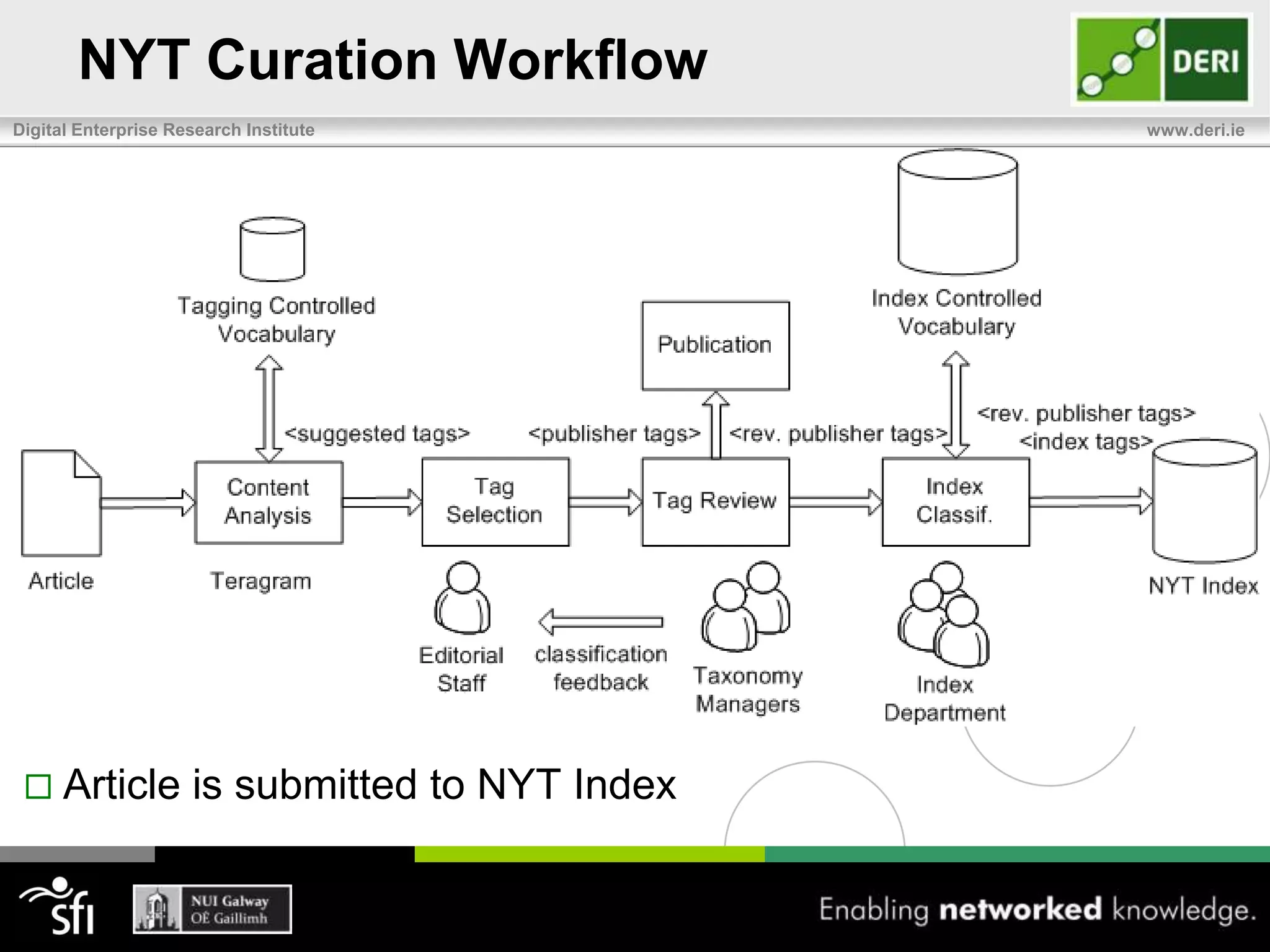


















The document discusses the significance of community-driven data curation for enterprises, exploring how it improves data quality and accessibility across various industries such as healthcare, finance, and manufacturing. It highlights different curation methods, including individual and community-based approaches, alongside case studies from major organizations like Wikipedia, The New York Times, and Thomson Reuters. Additionally, it outlines best practices for setting up effective data curation processes to enhance the trustworthiness and usability of data in a corporate setting.























































































