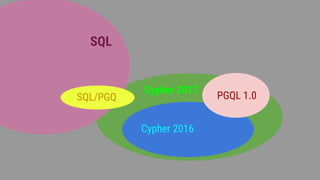
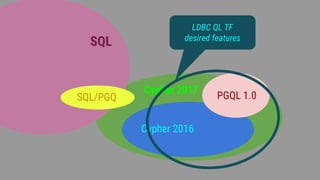
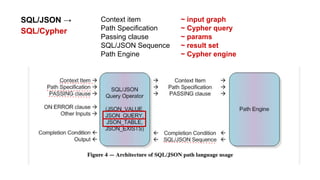
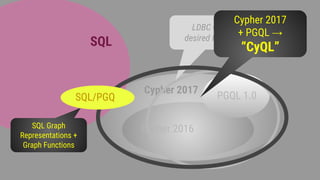
The document discusses the development and standardization of graph query languages, particularly focusing on opencypher and its community efforts. It highlights initiatives from the Linked Data Benchmark Council (LDBC), discussions on enhancing SQL to include graph data model concepts, and ongoing work towards proposing new features and syntax changes in existing languages. Key stakeholders include Neo4j and various commercial and open-source databases utilizing Cypher as their graph query language.



























![GraphQL vs Traditional Rest API [GeeCon Prague 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/geeconprague2018-graphqlvstraditionalrestapi-181027185525-thumbnail.jpg?width=640&height=640&fit=bounds)




































































