Download as PDF, PPTX

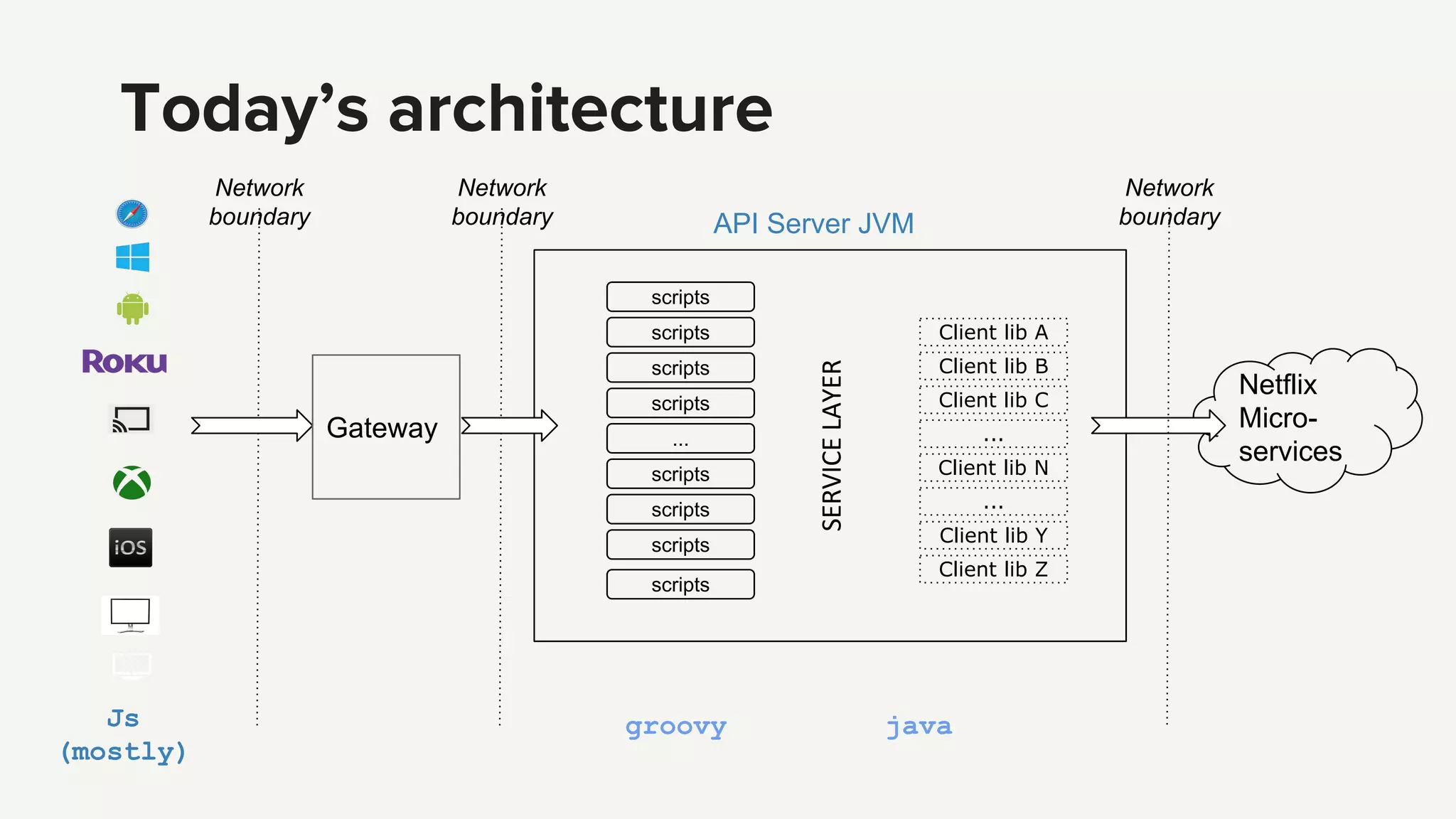














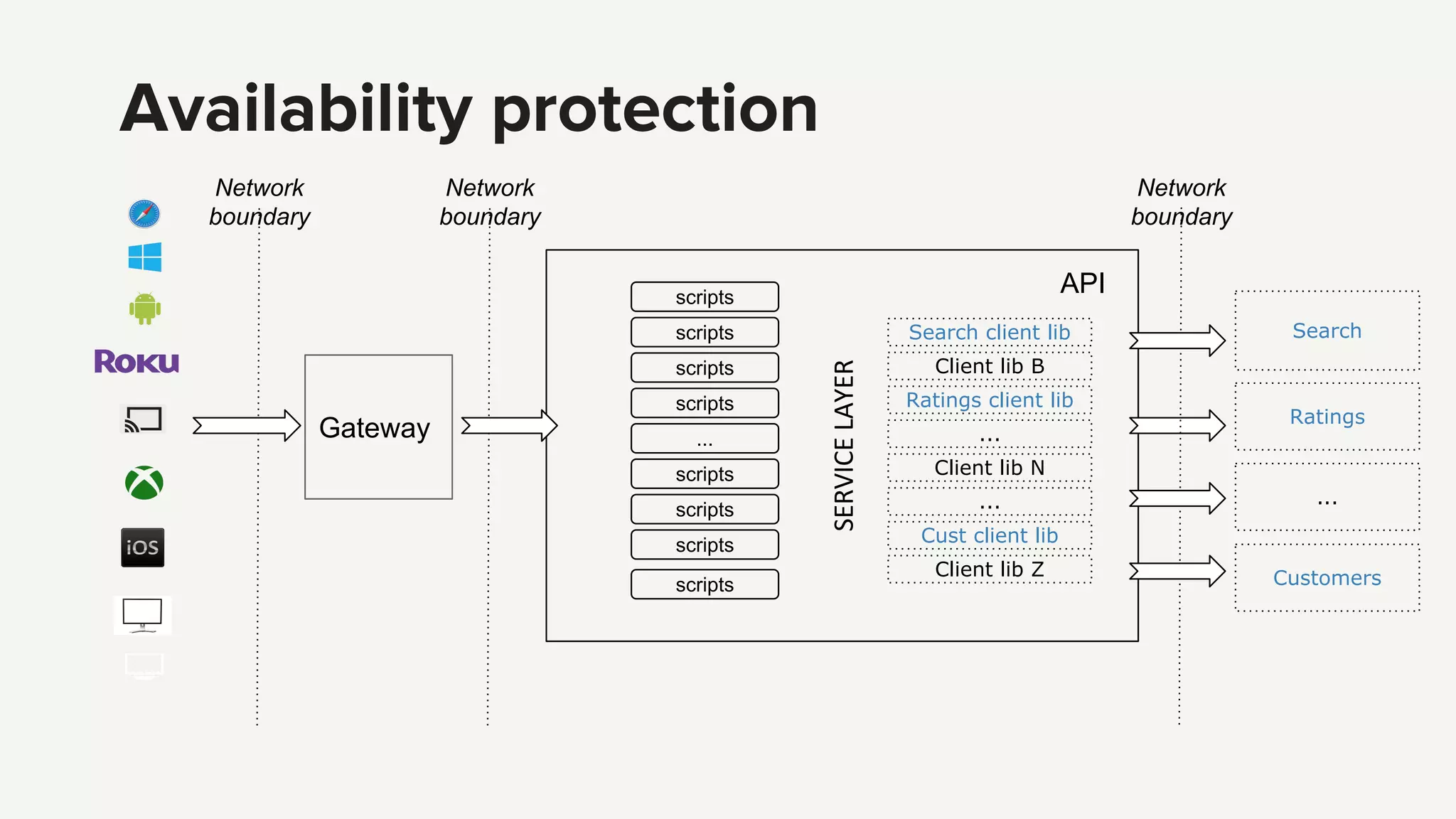











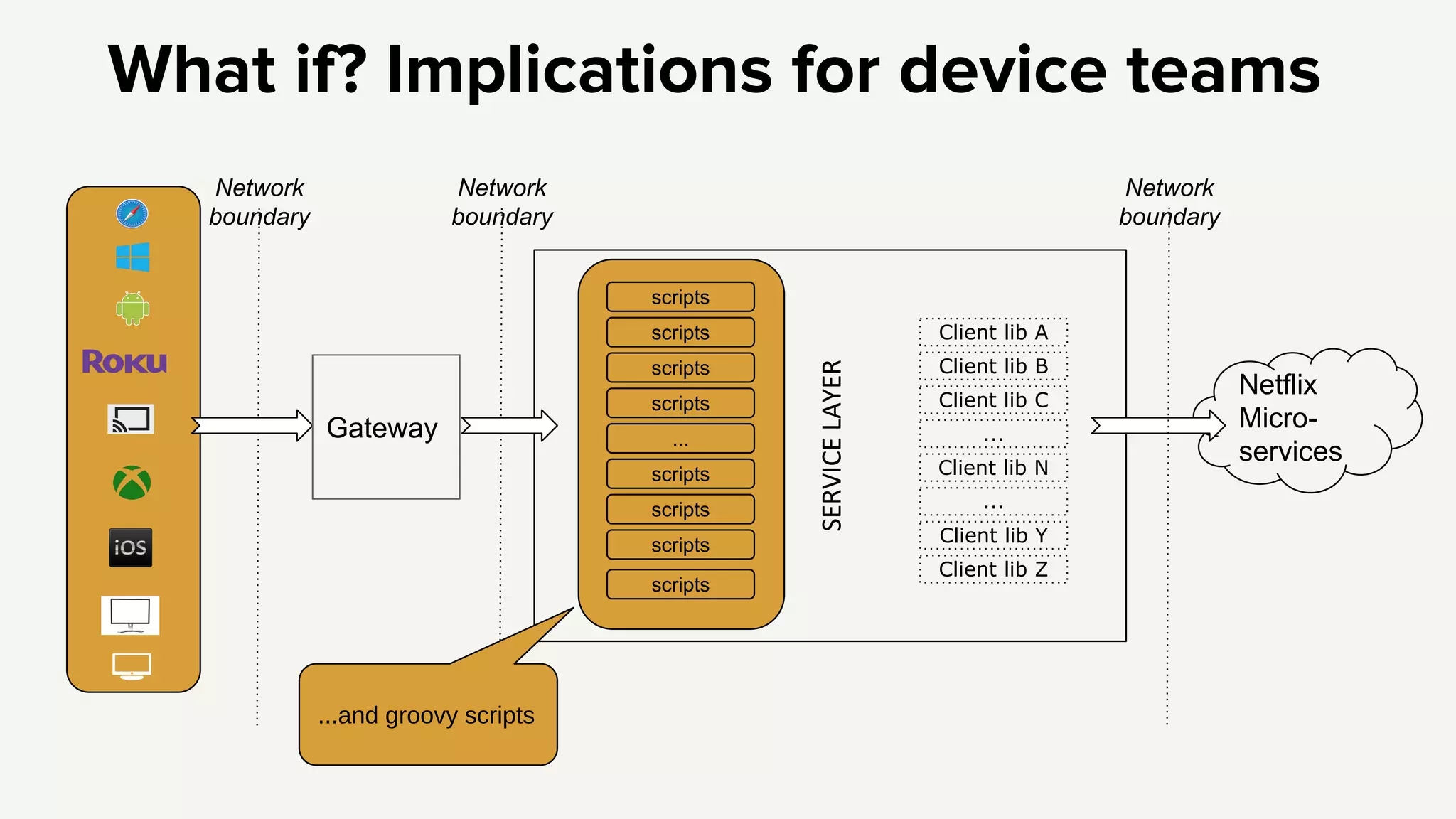

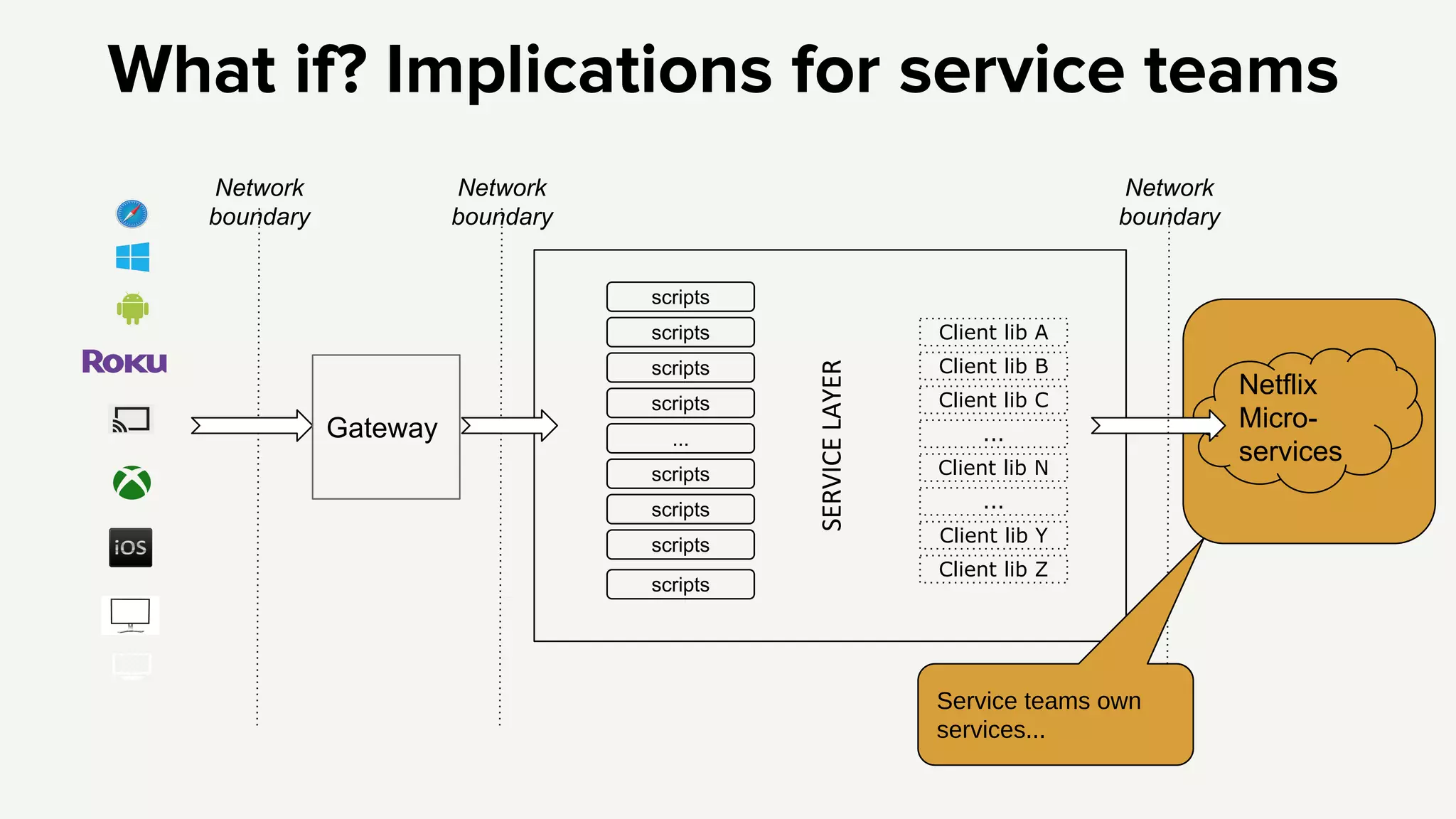




















1. The new Netflix API aims to provide orchestration of services, availability protection, and abstraction for client libraries and device teams. 2. To address complexity challenges, Netflix plans to move scripts out of the API and split the API into separate services for authentication and an edge platform for scripts. 3. This will reduce complexity, improve debugging and profiling, and allow faster independent development while still providing higher level APIs and resiliency across services.
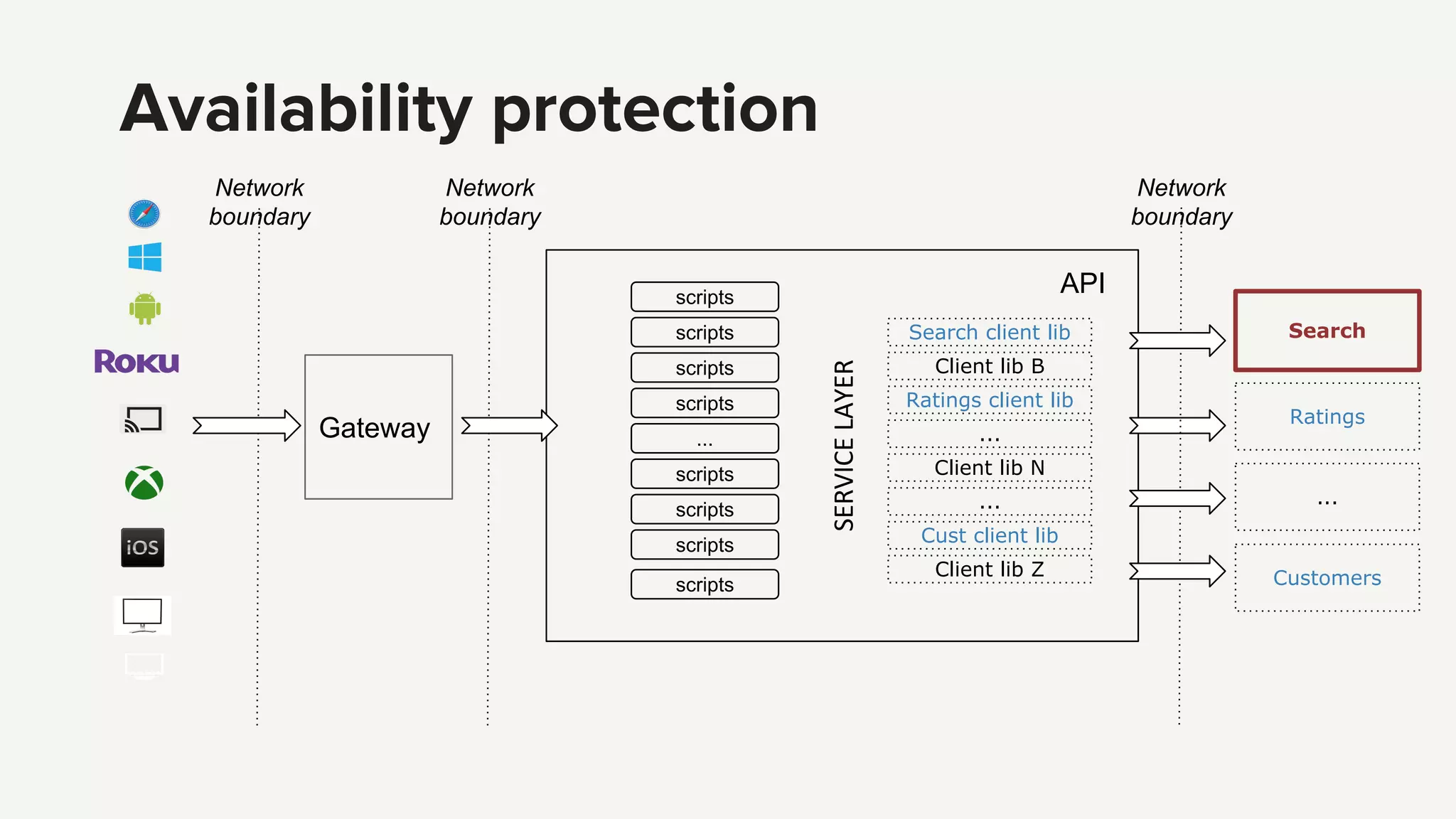
Introduction to the Netflix API architecture and its complexity challenges, highlighting the need for orchestration and availability.
Introduction to the Netflix API architecture and its complexity challenges, highlighting the need for orchestration and availability.API's purpose defined by orchestration, availability protection, and abstraction, which are essential for effective service management.
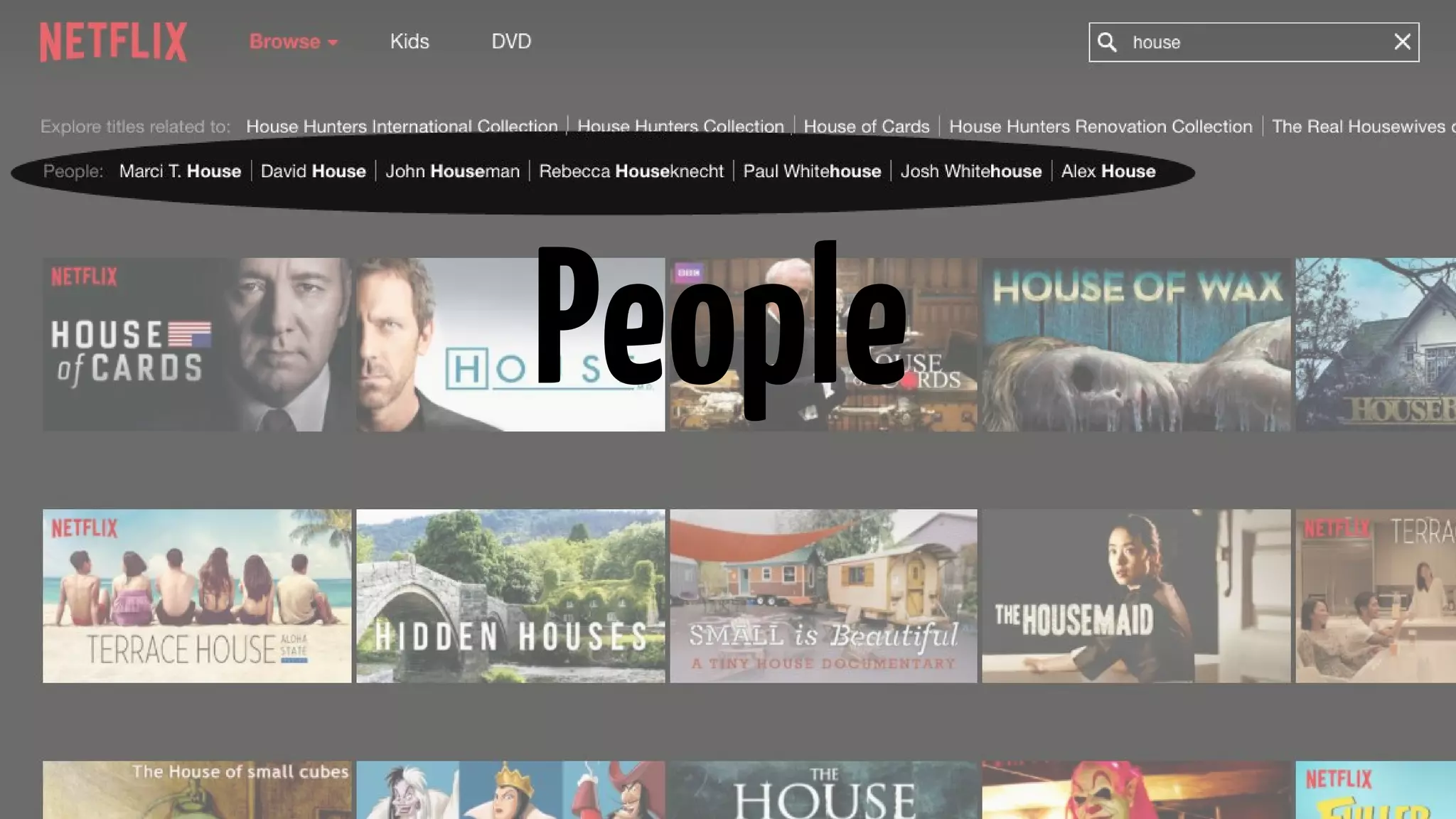
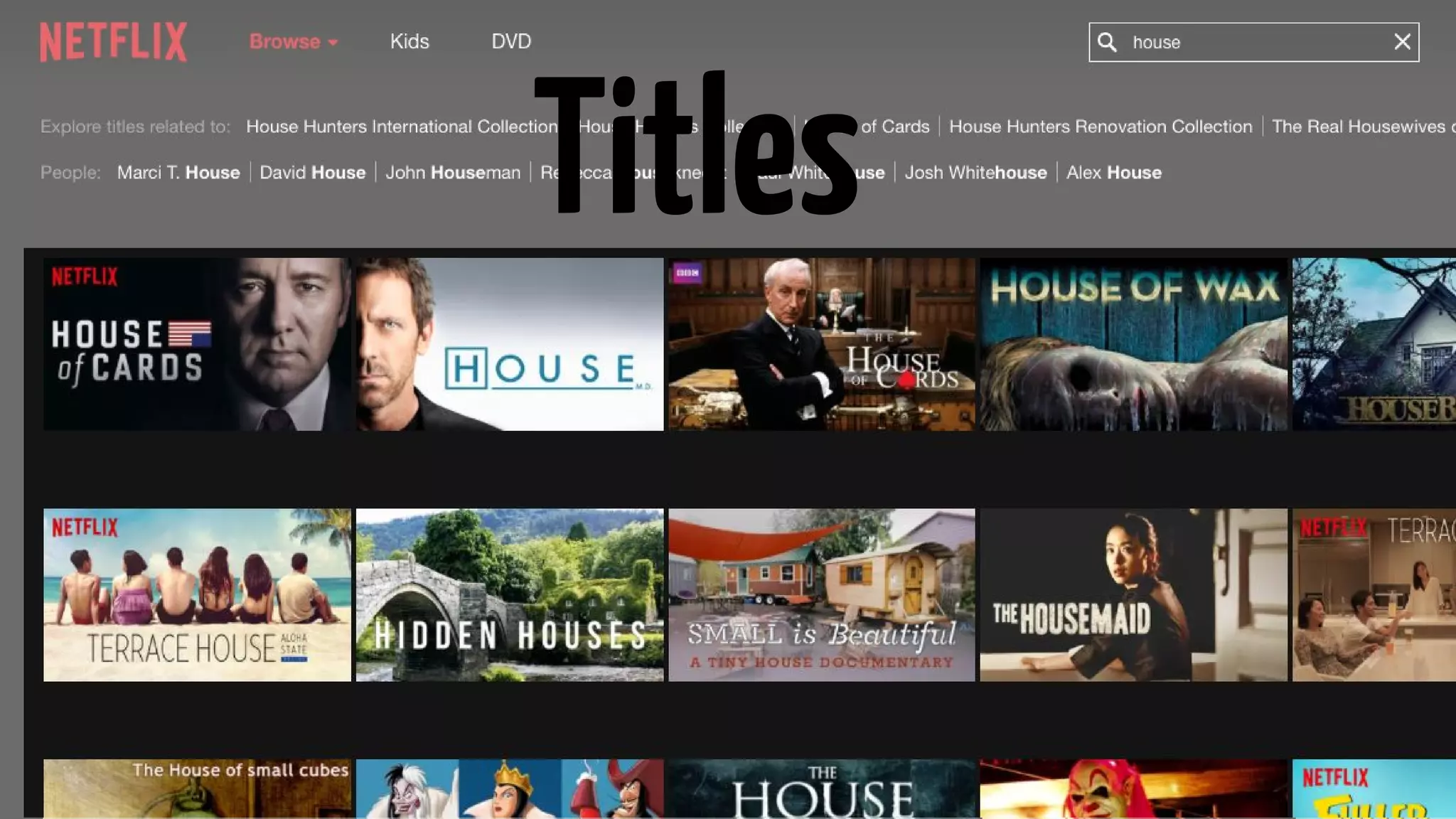
Explanation of search requests, metadata requirements, and orchestration processes for search results.
Explanation of search requests, metadata requirements, and orchestration processes for search results.
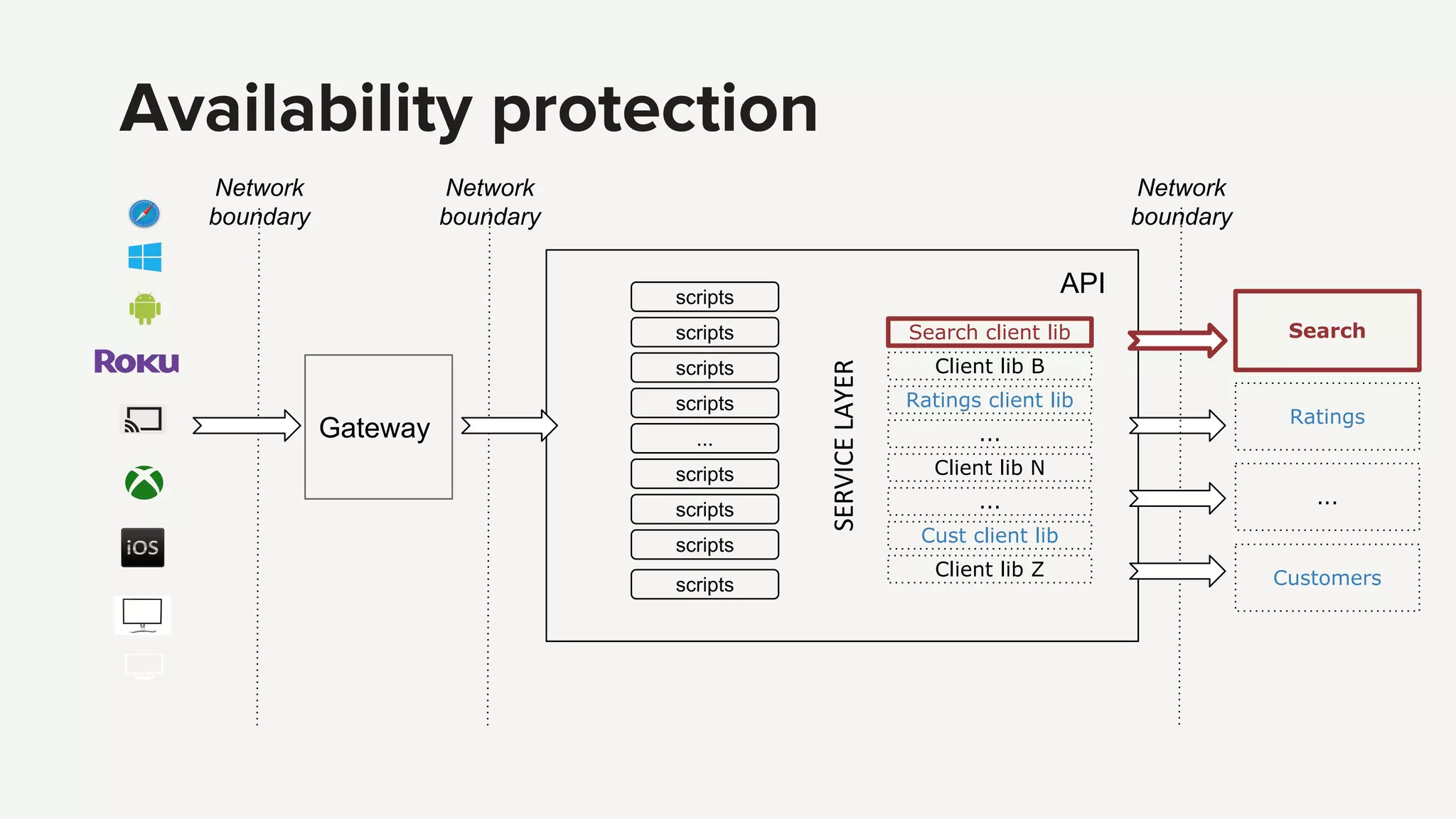
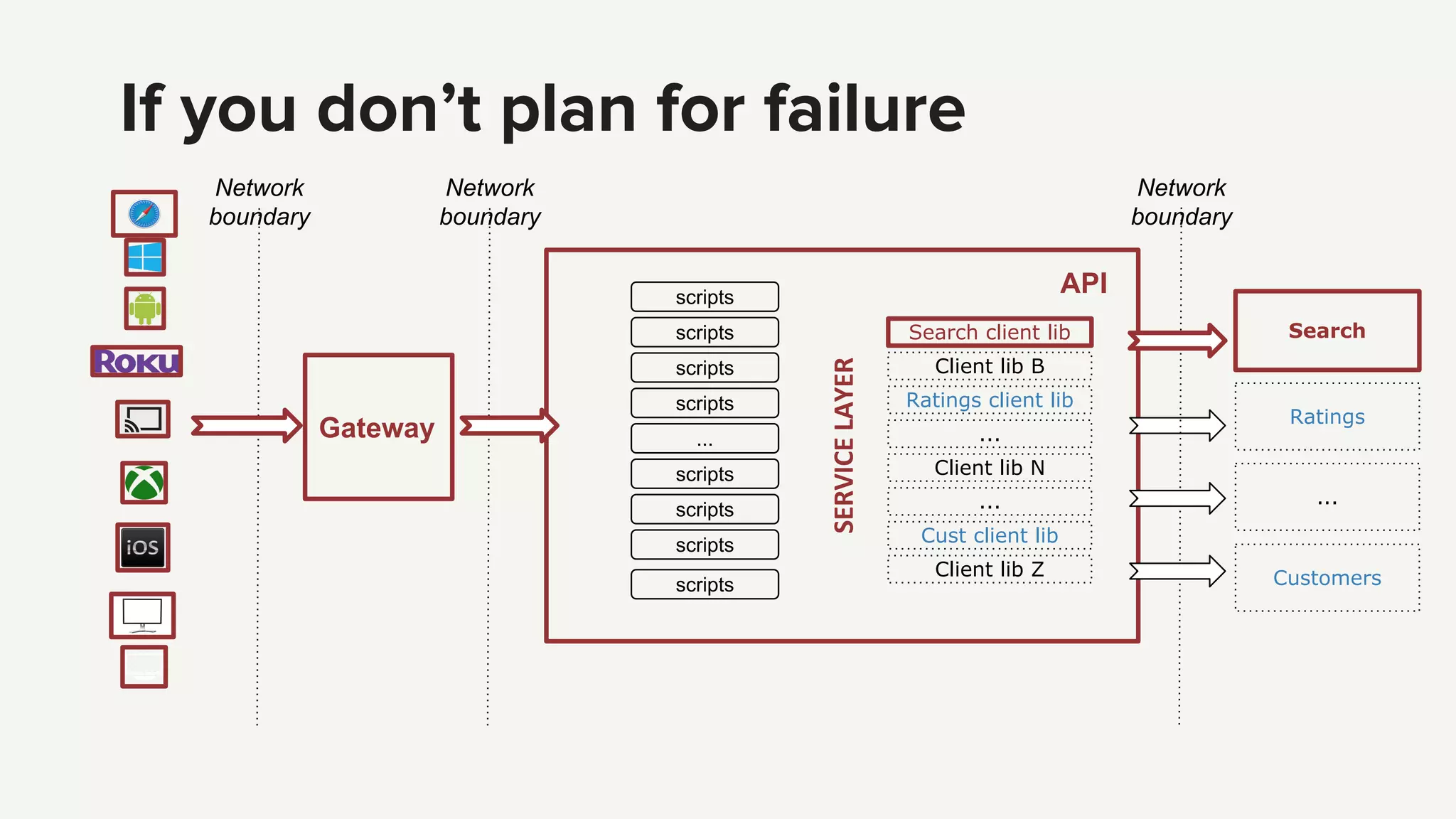
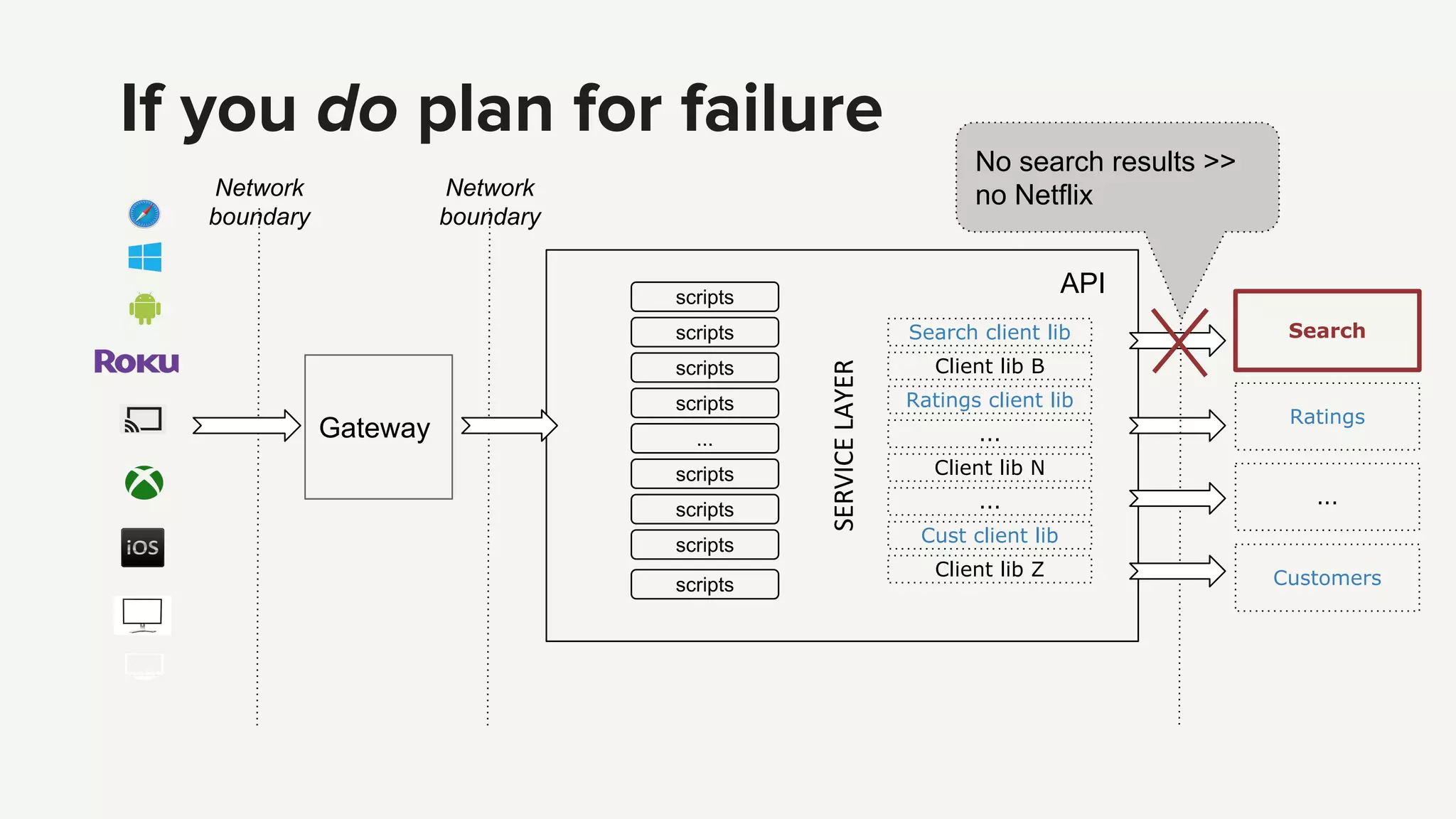
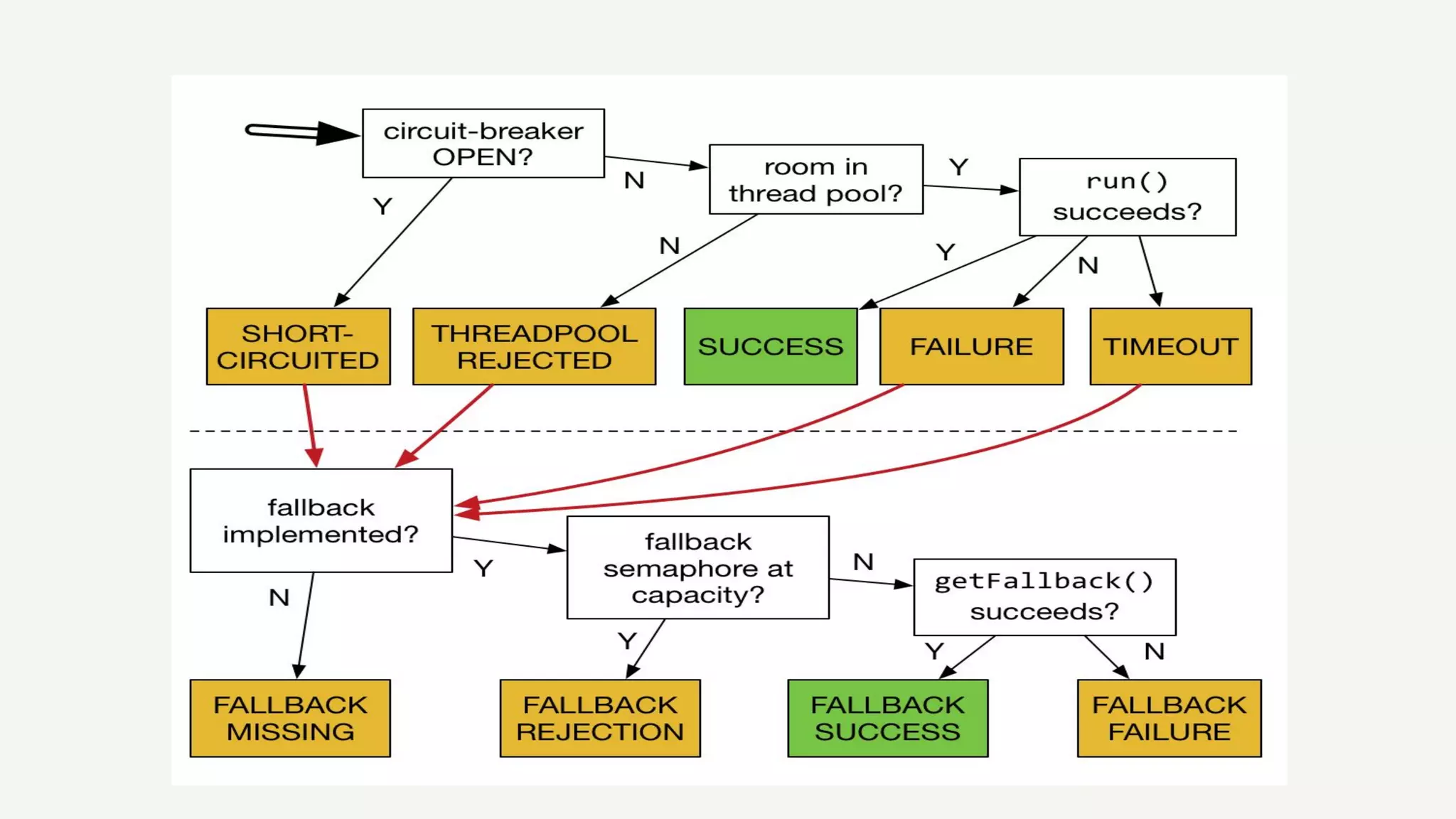
Strategies for ensuring API reliability, including customer experience, fault tolerance with Hystrix, and handling service dependencies.
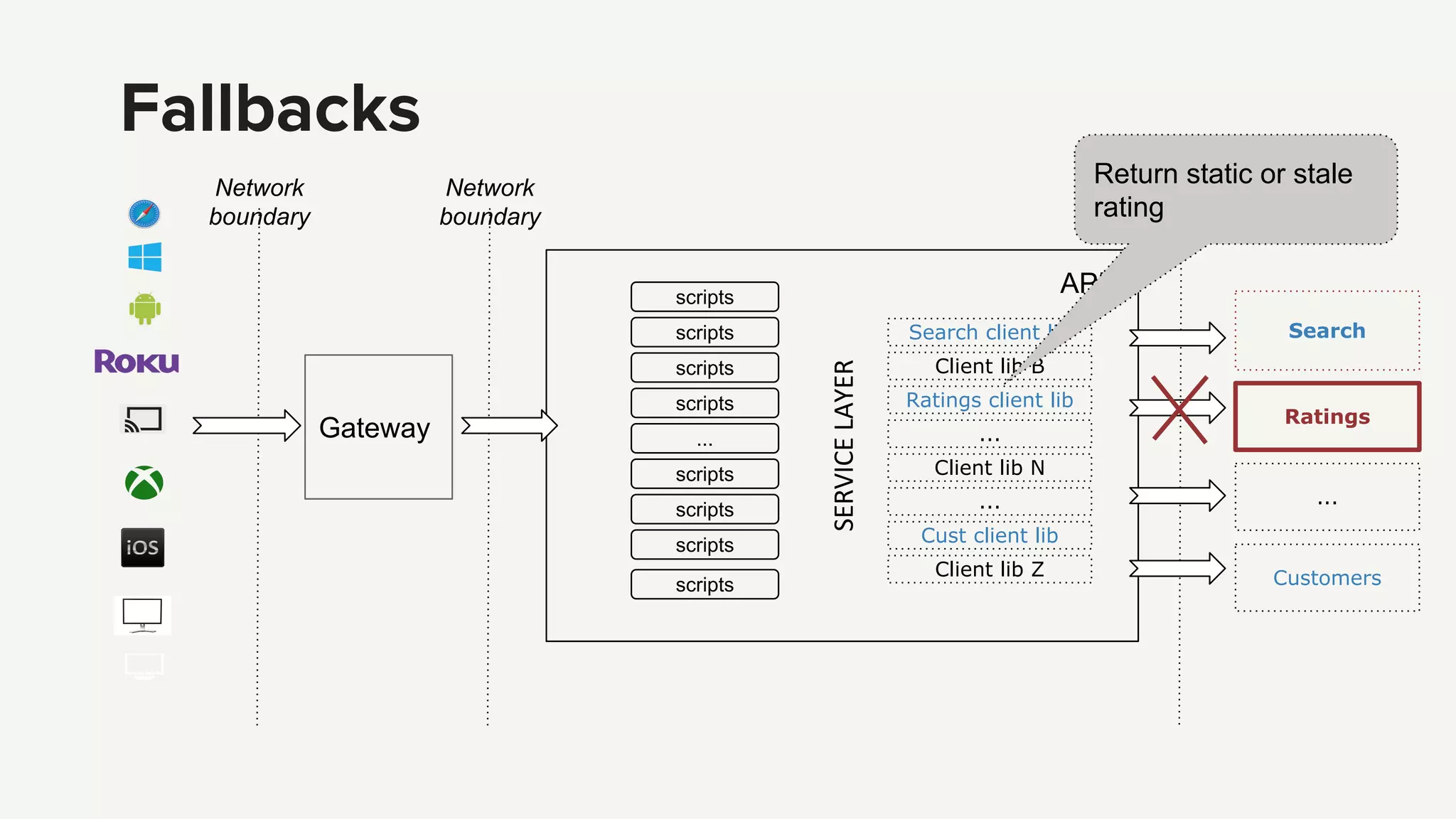
Techniques for managing errors in API services using fallbacks and making error-handling explicit to maintain functionality.
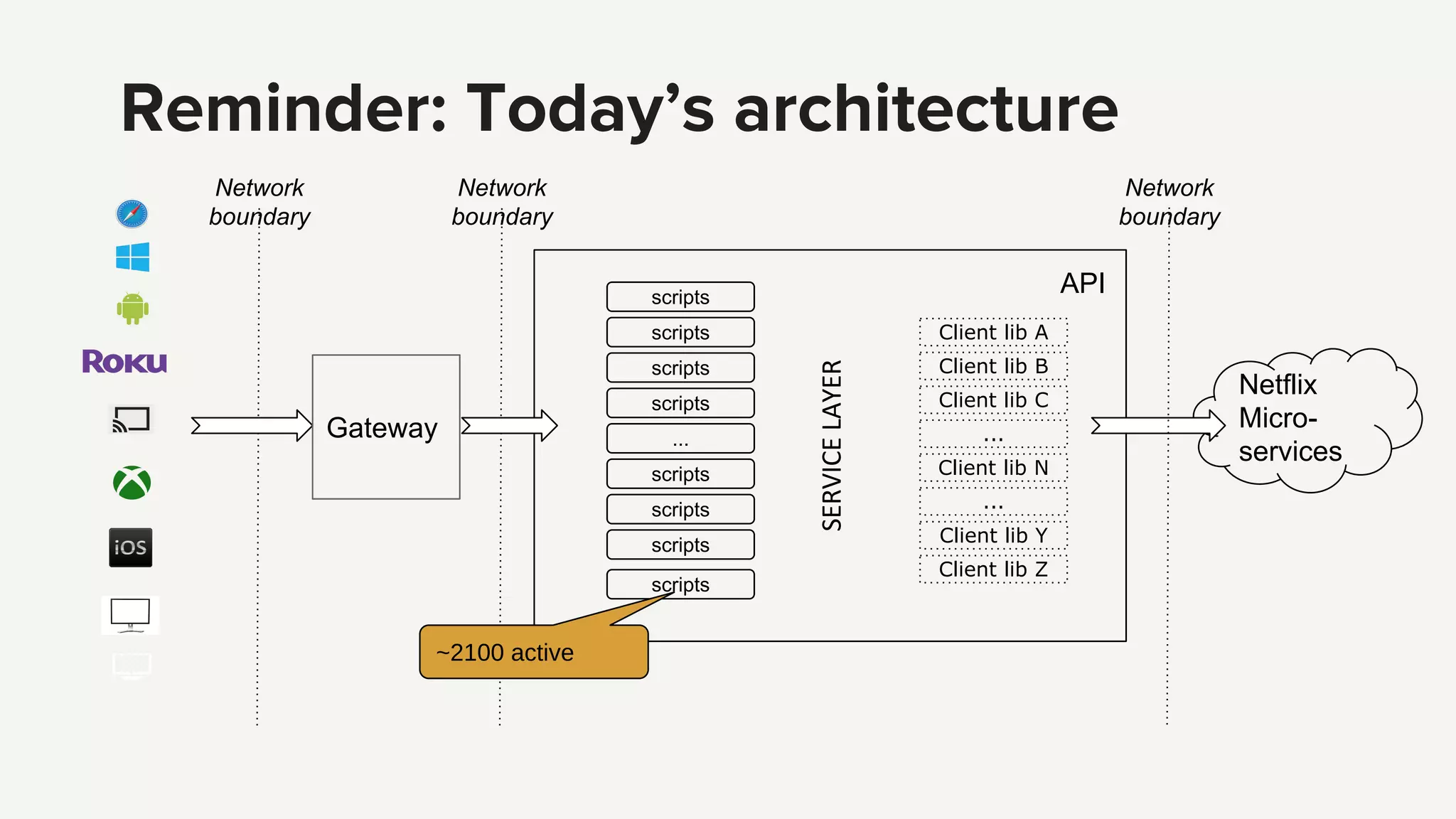
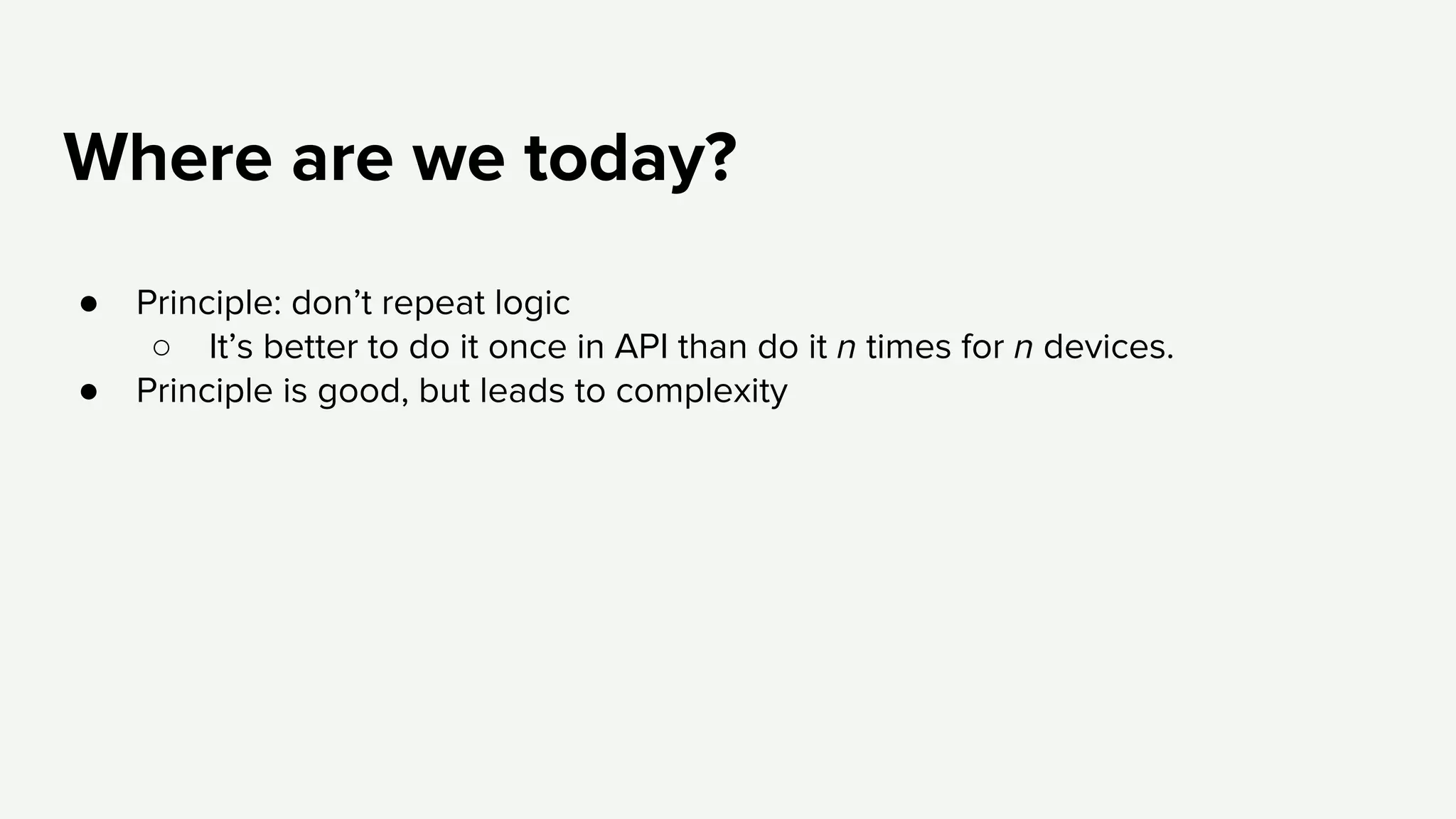
Identifying complexity challenges such as debugging and operational insights while discussing future priorities for simplification.
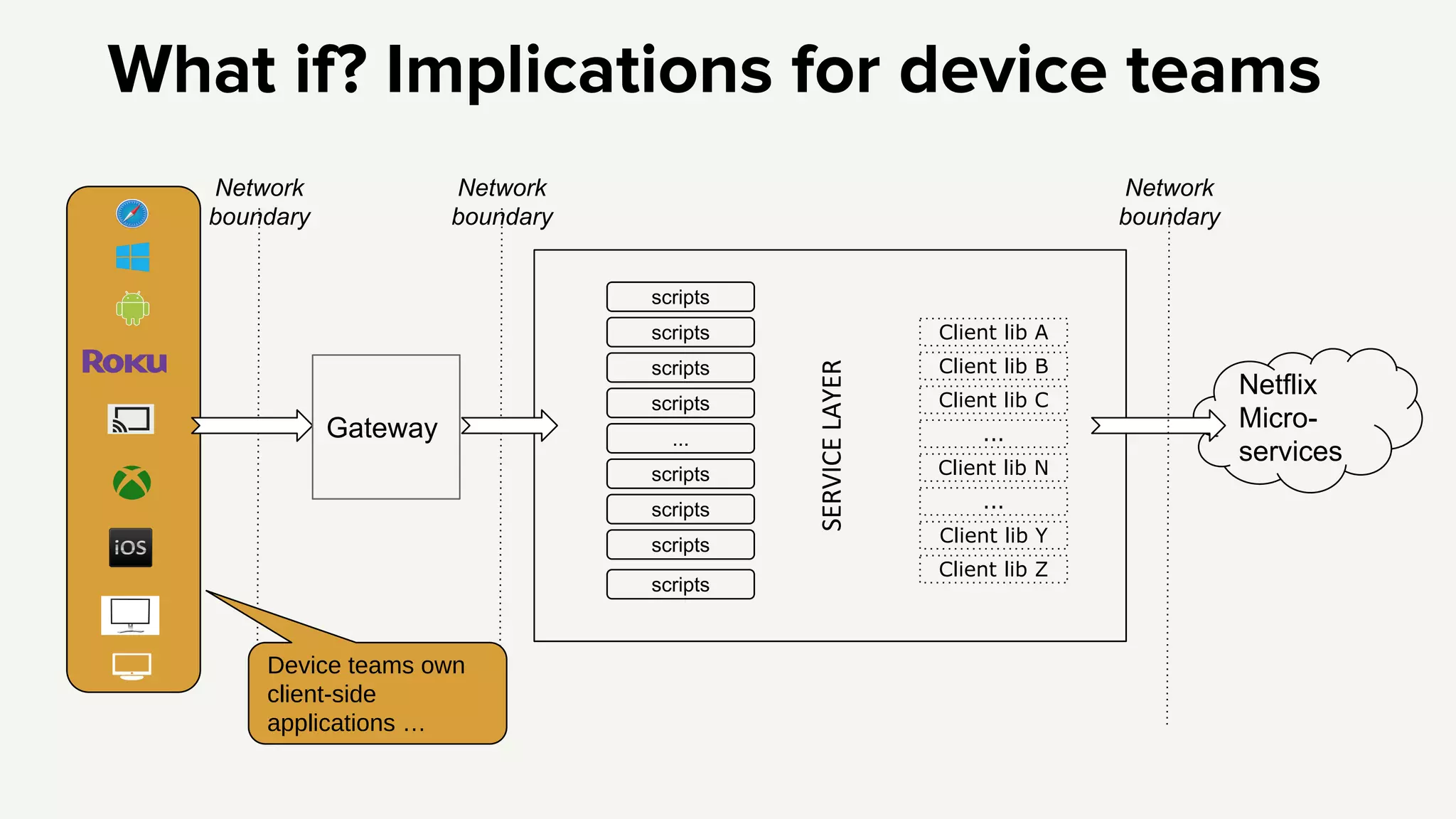
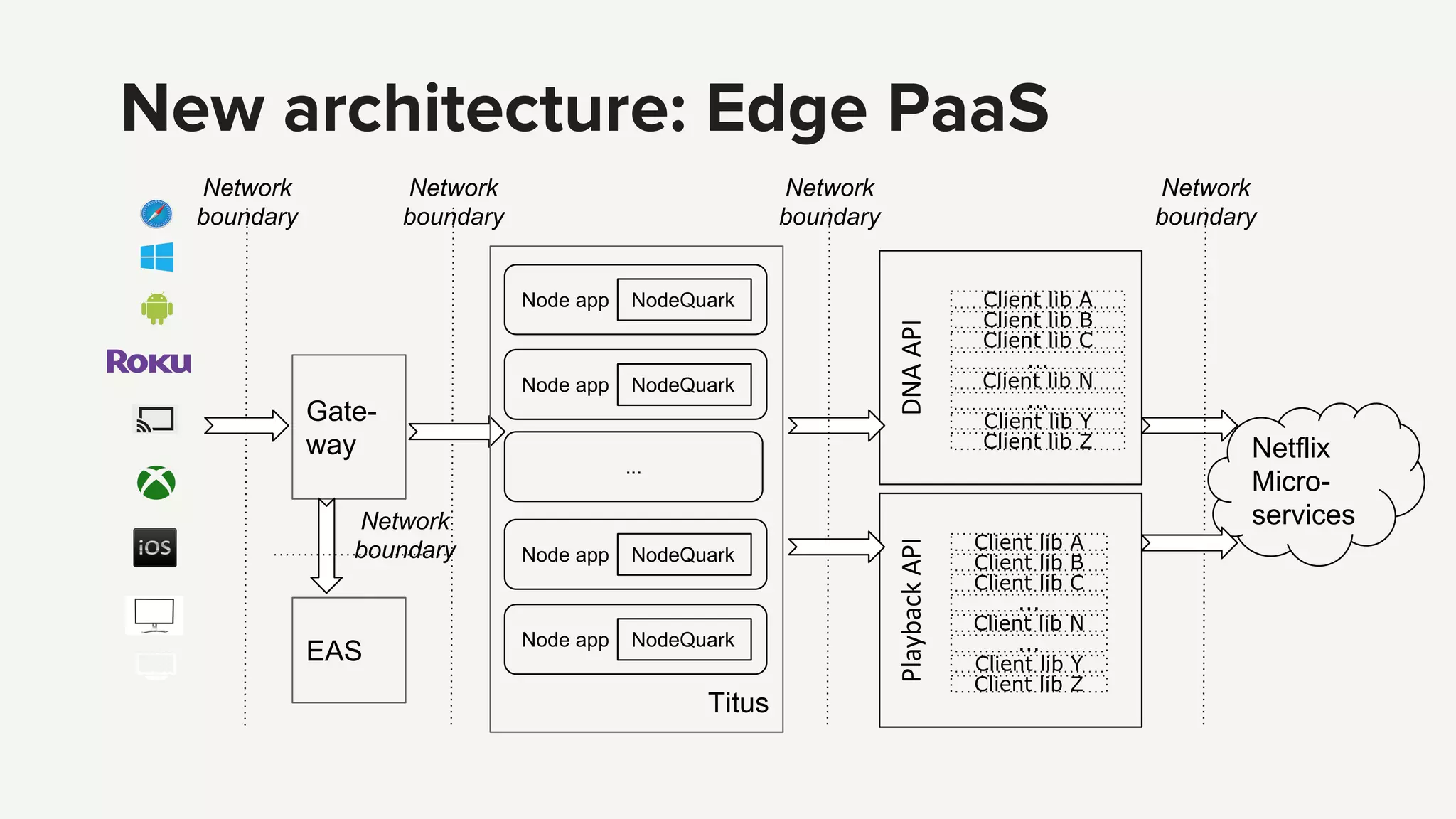
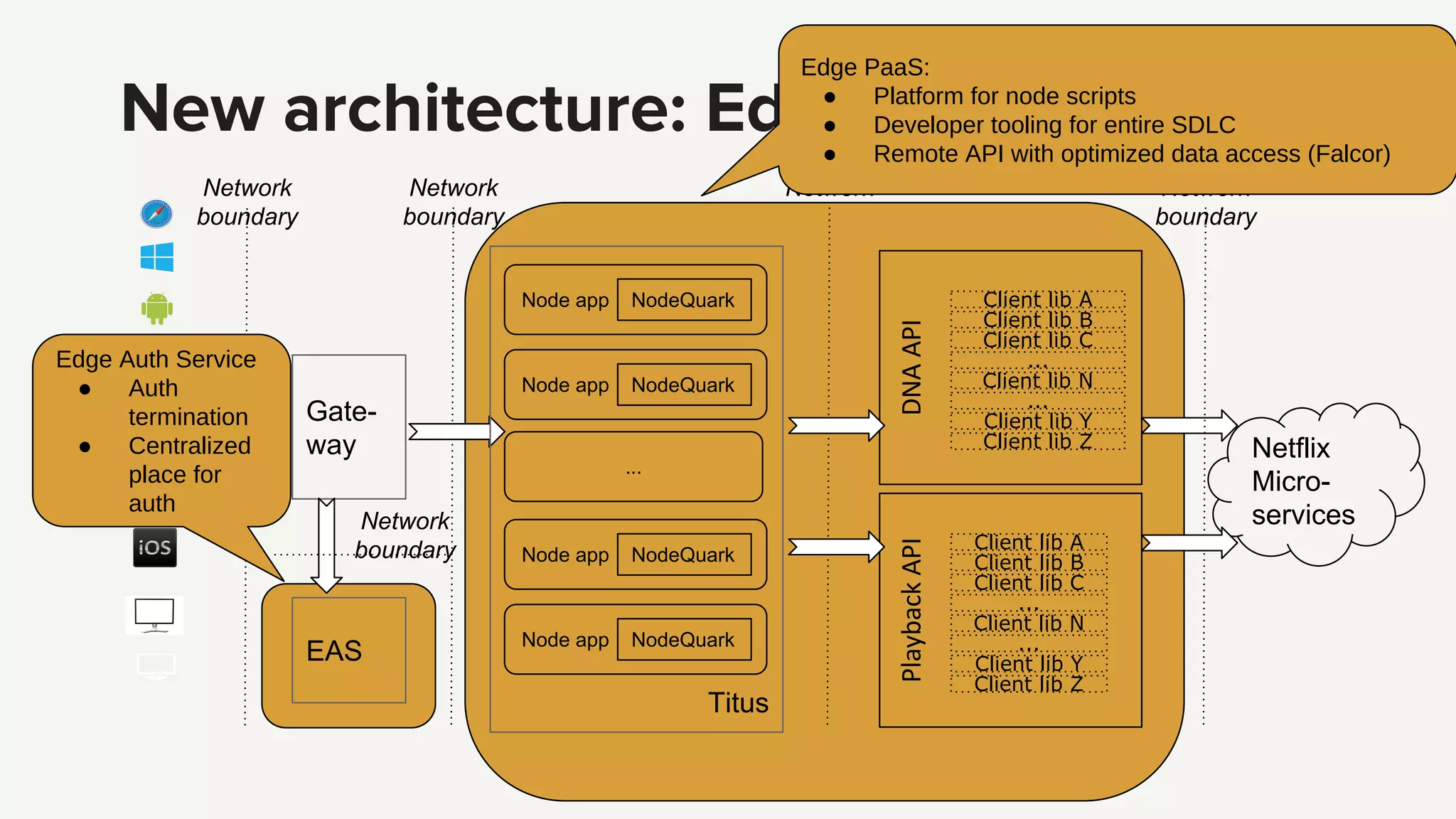
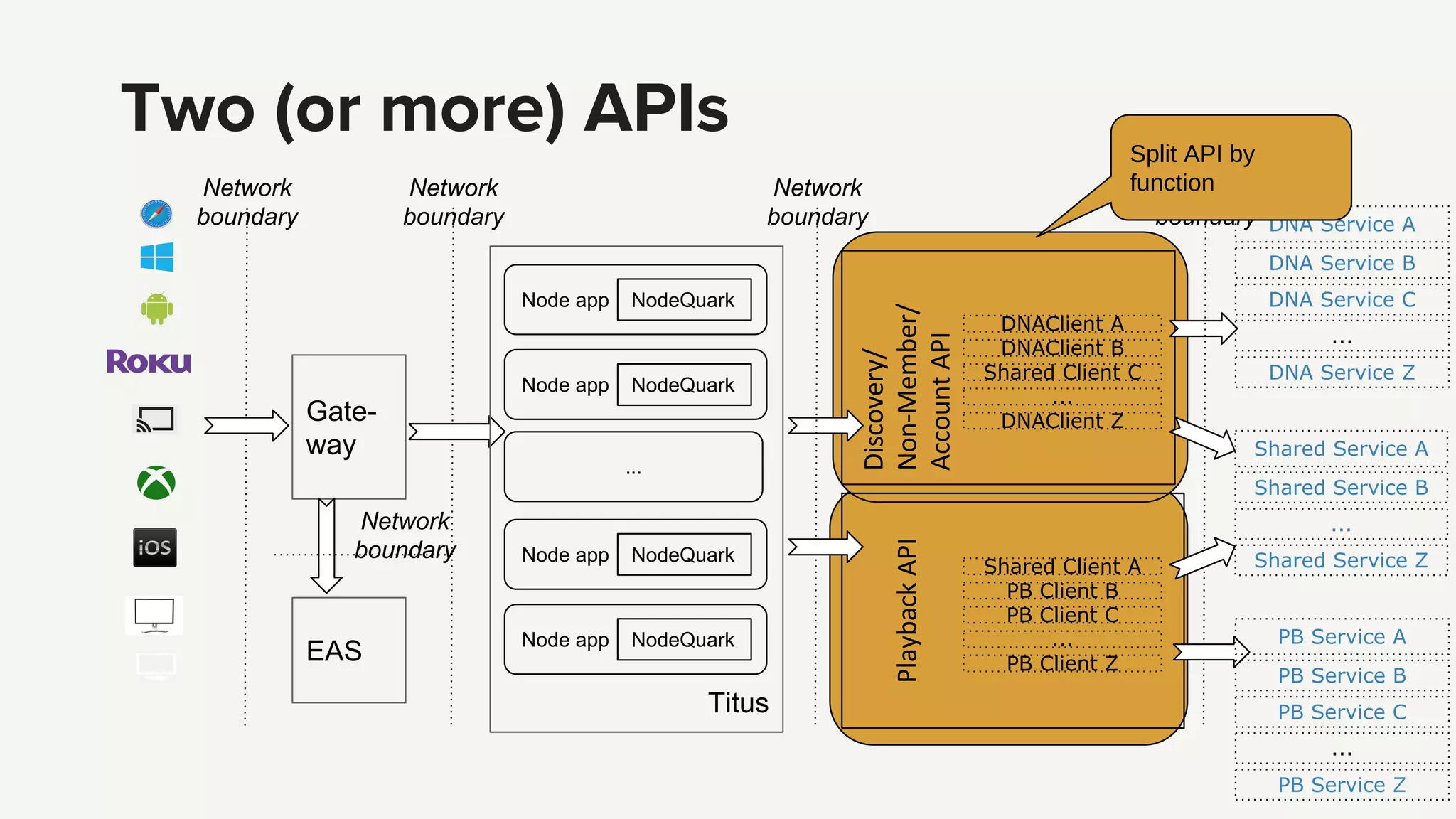
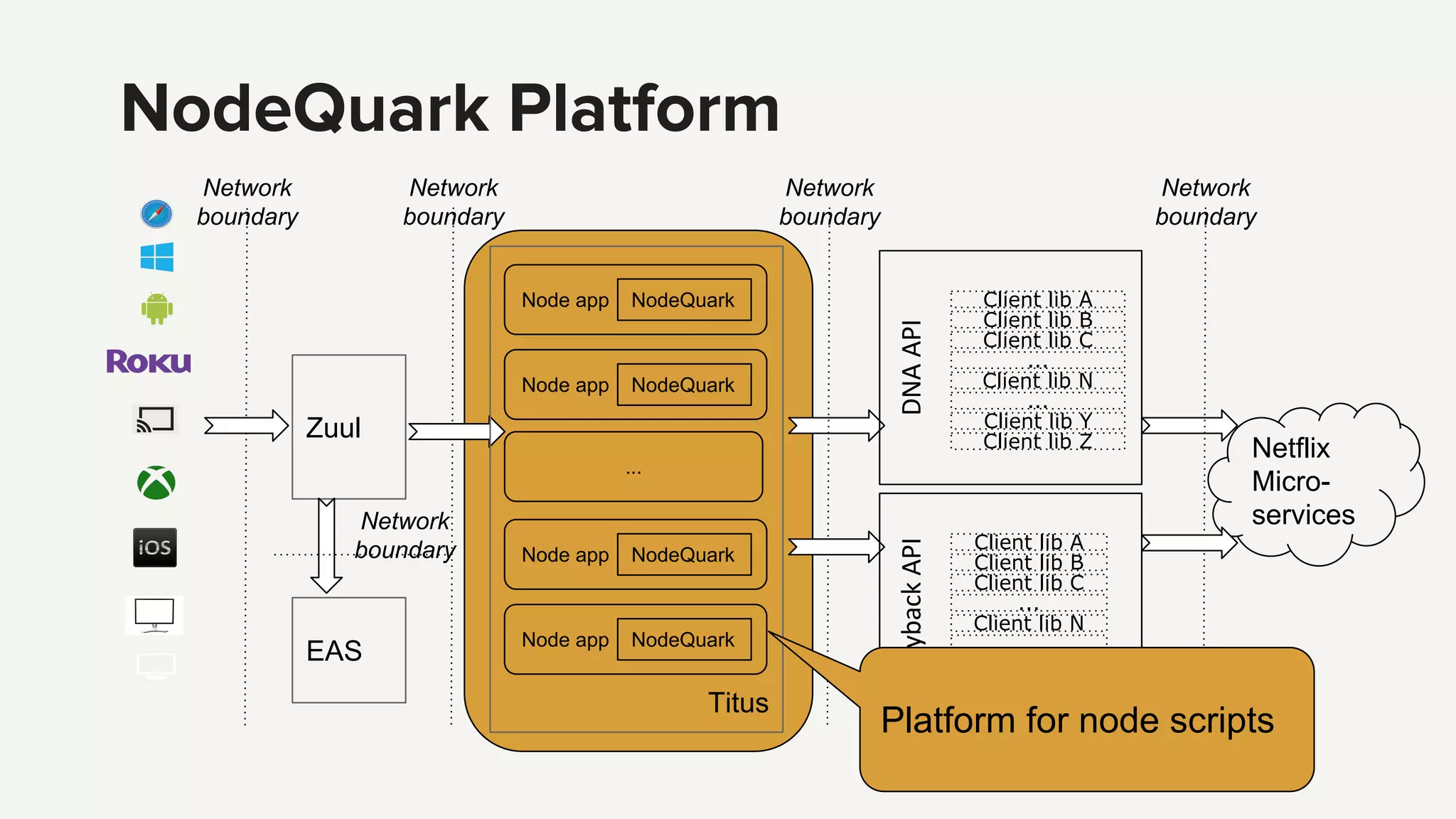
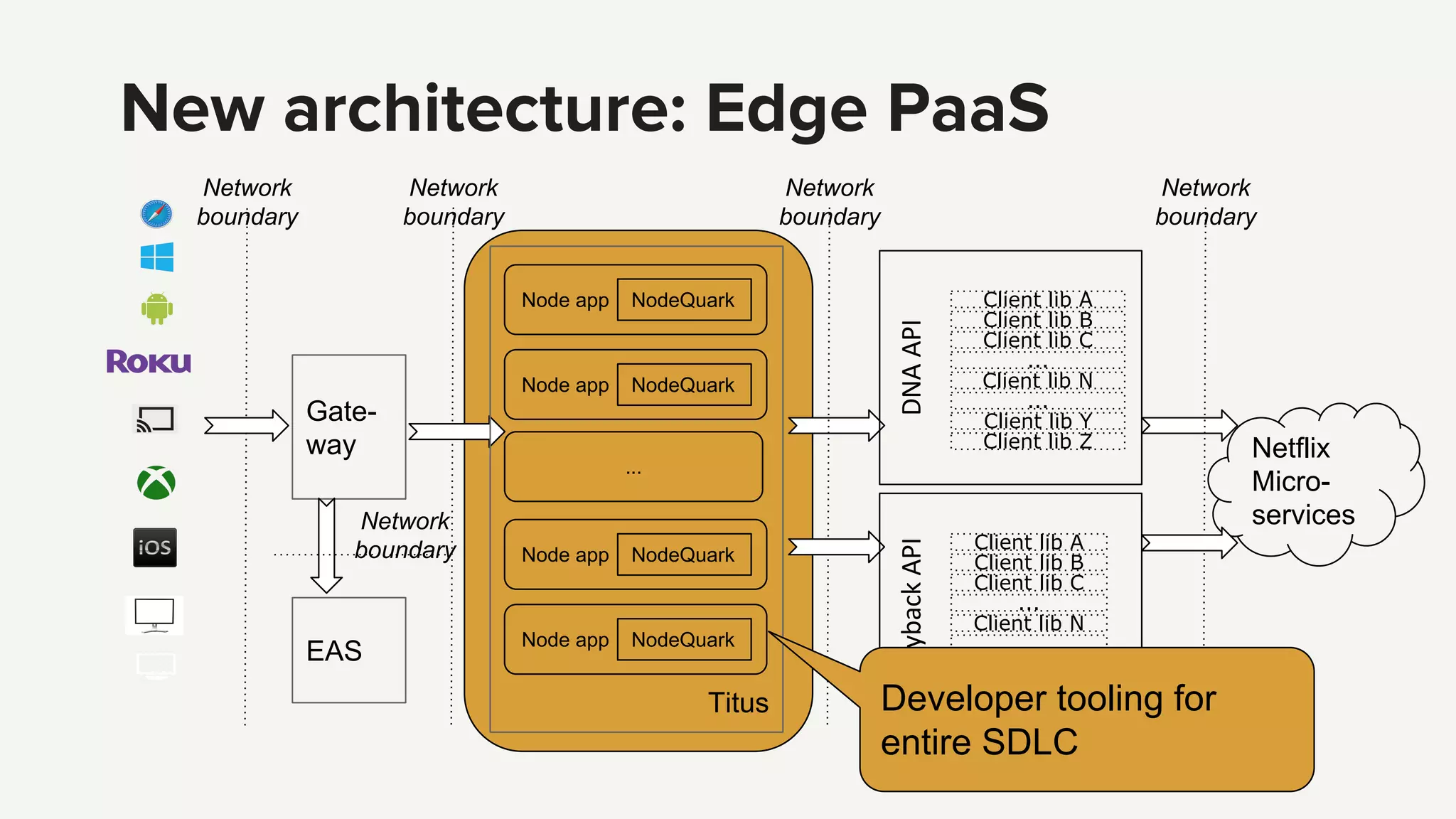
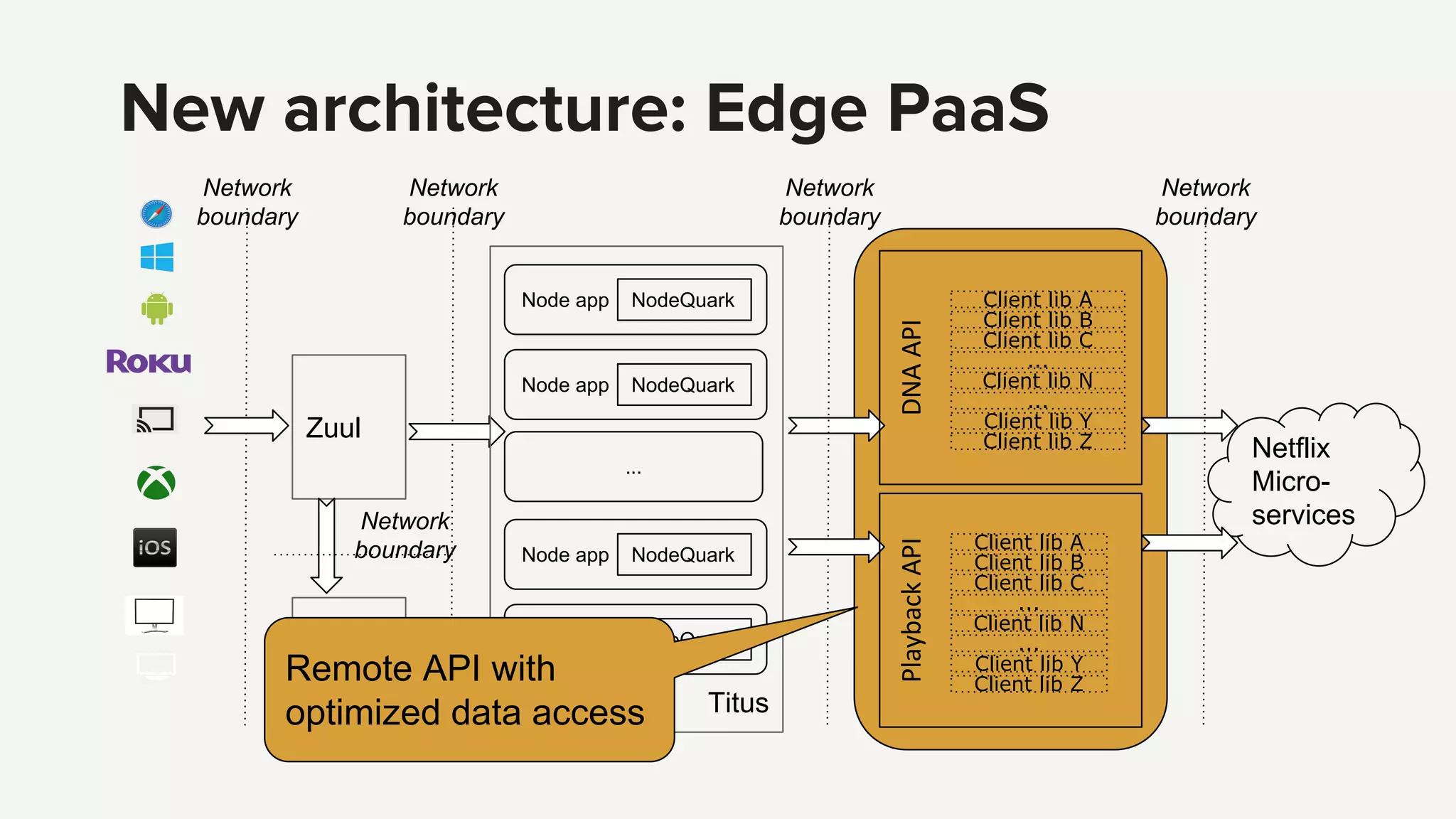
Introduction to the Edge PaaS architecture, emphasizing node applications, enhanced developer tools, and remote API capabilities.
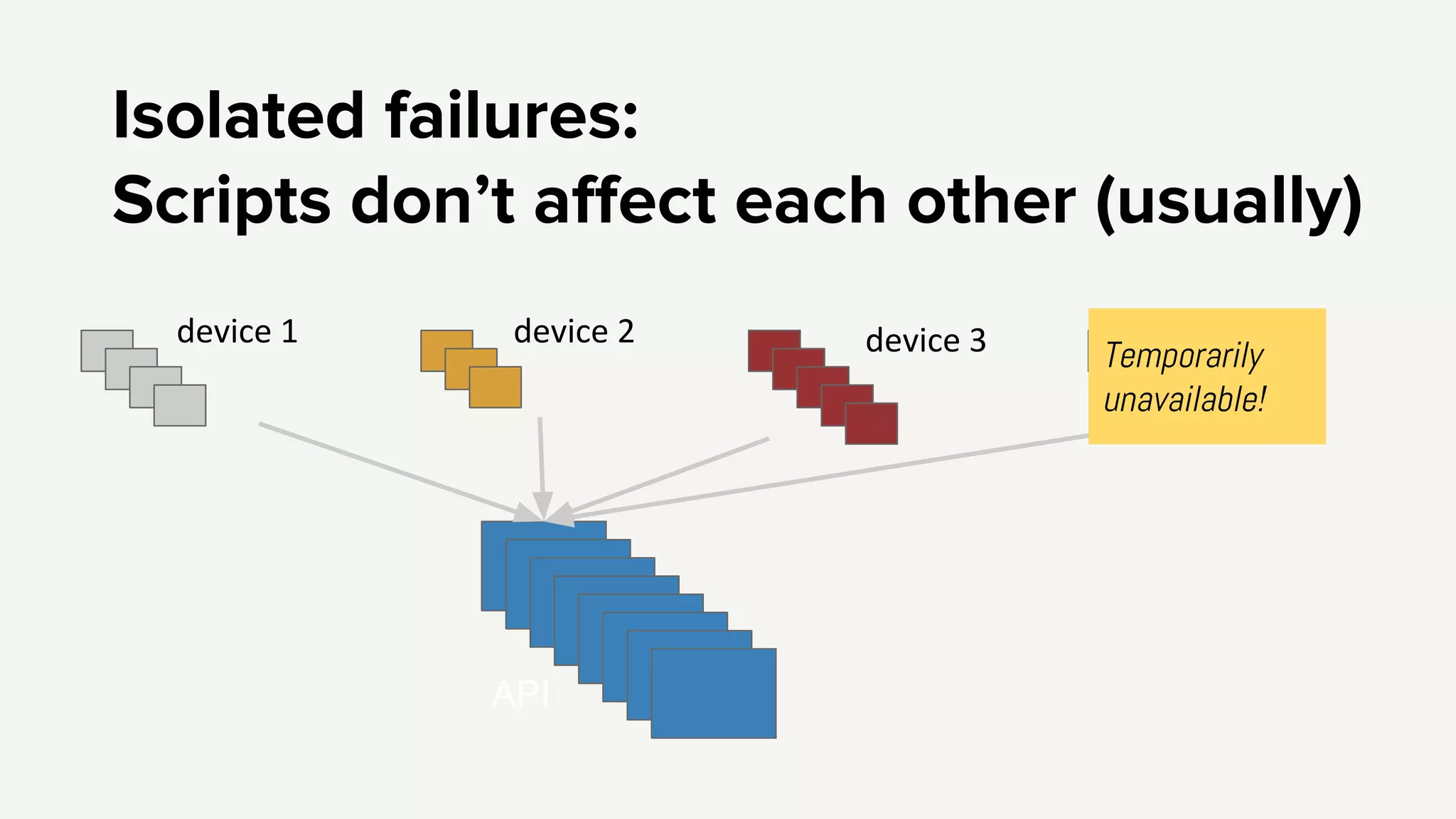
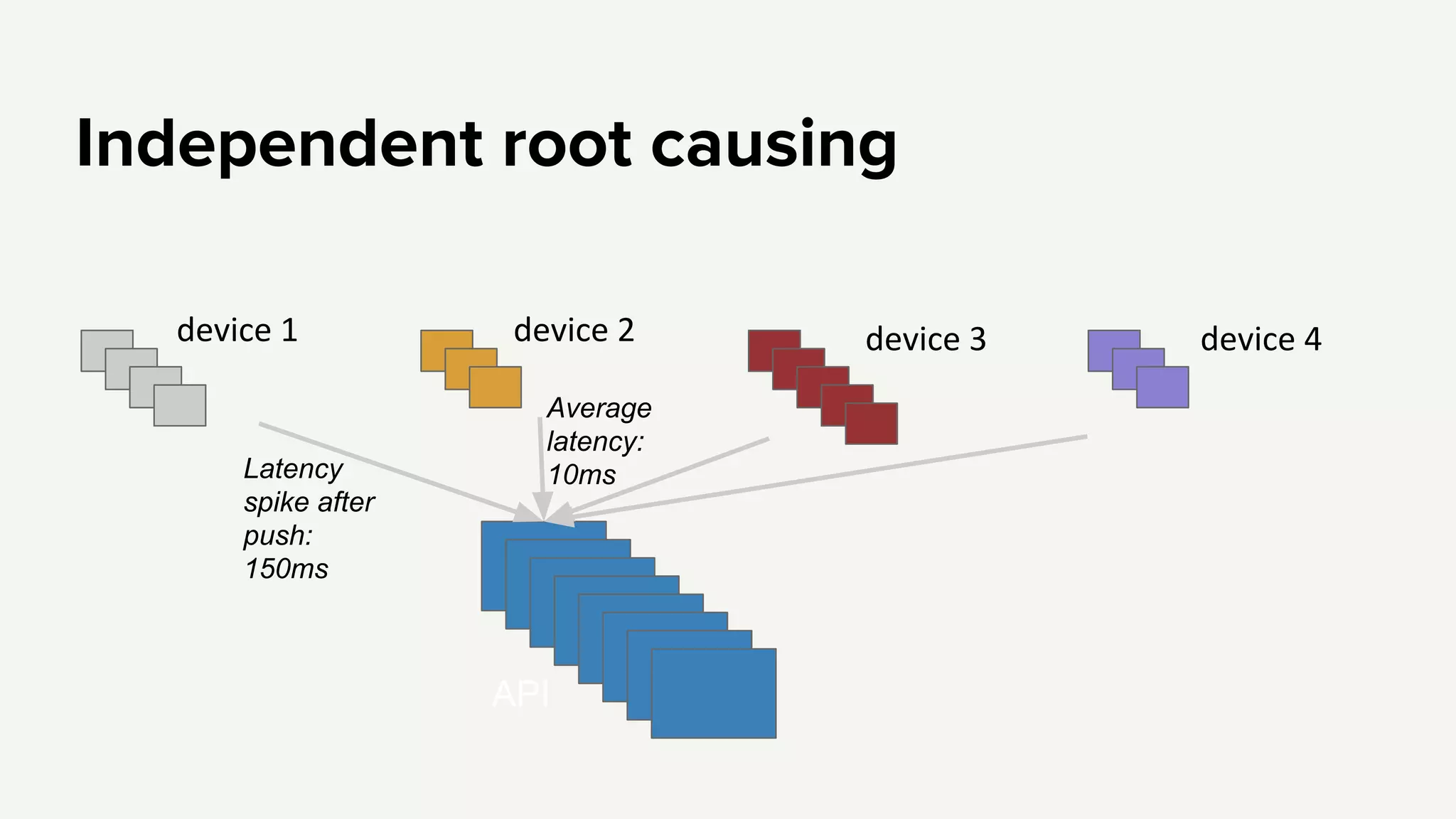
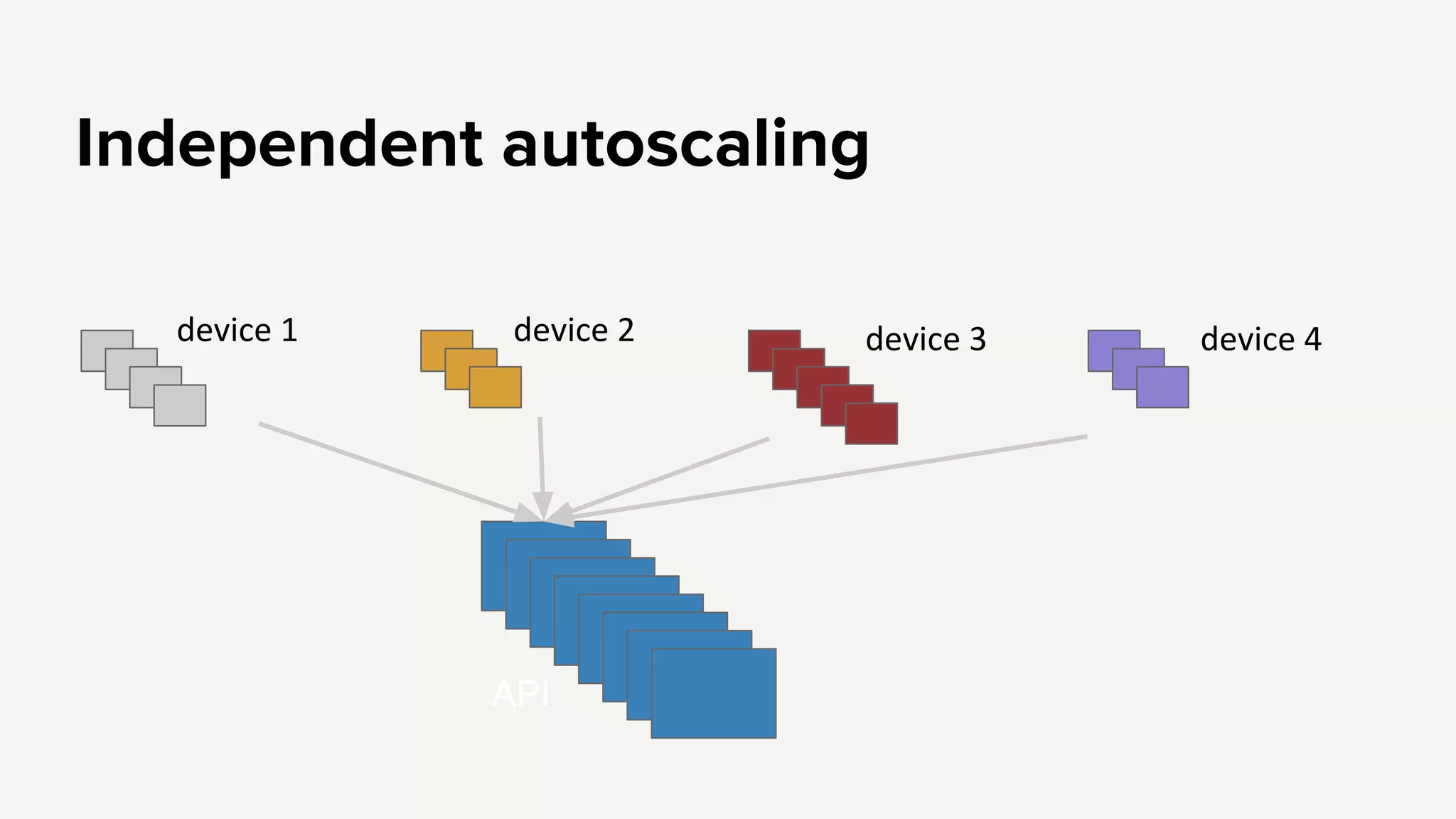
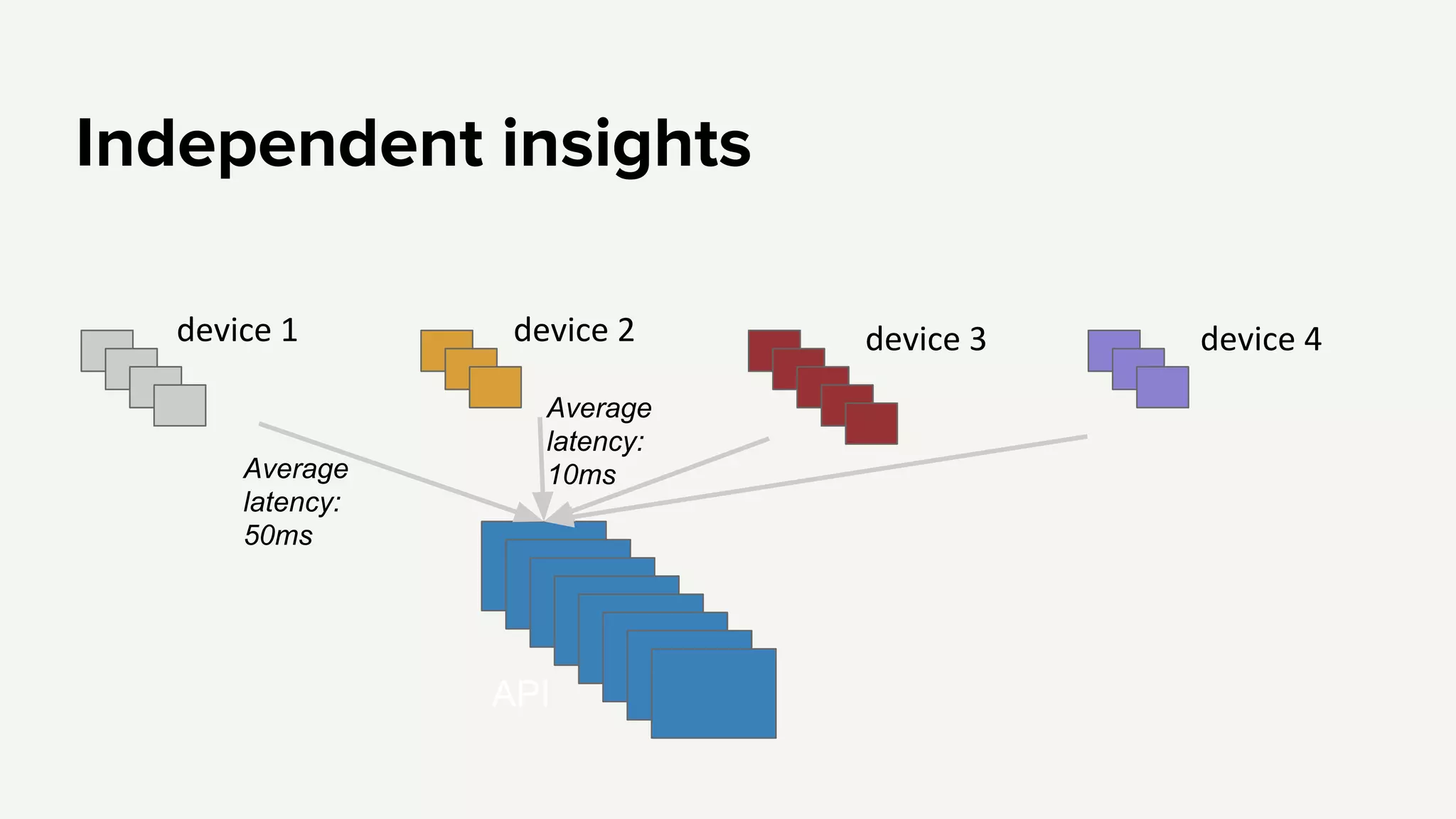
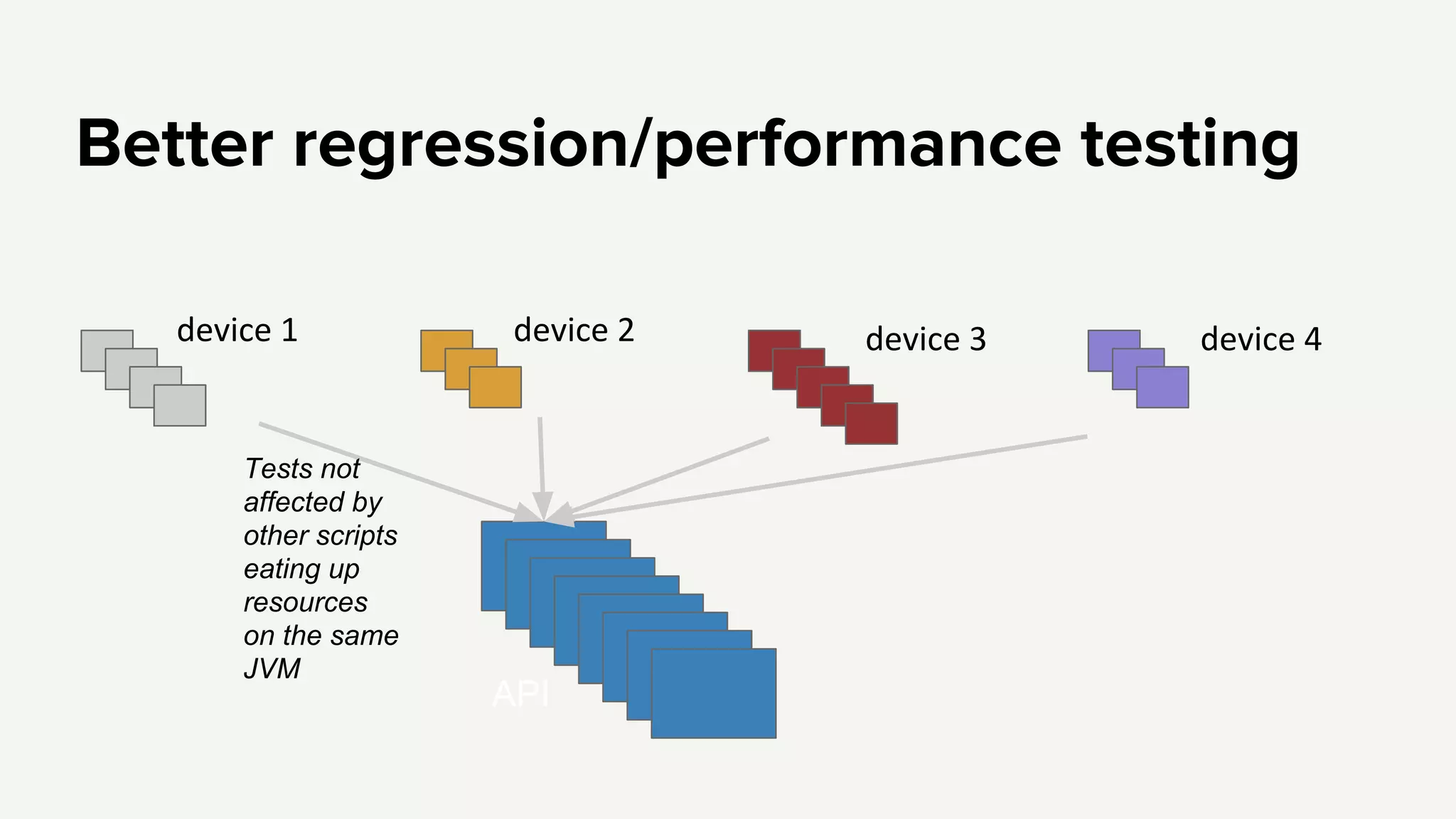
Emphasis on independent failures, monitoring performance metrics, and ensuring better regression testing to enhance API reliability.
Reflection on the increasing complexity of Netflix’s API and the emphasis on simplifying the service architecture.








![[CEDEC 2021] 運用中タイトルでも怖くない! 『メルクストーリア』におけるハイパフォーマンス・ローコストなリアルタイム通信技術の導入事例](https://cdn.slidesharecdn.com/ss_thumbnails/cedec2021-210825103749-thumbnail.jpg?width=640&height=640&fit=bounds)































































