Download to read offline


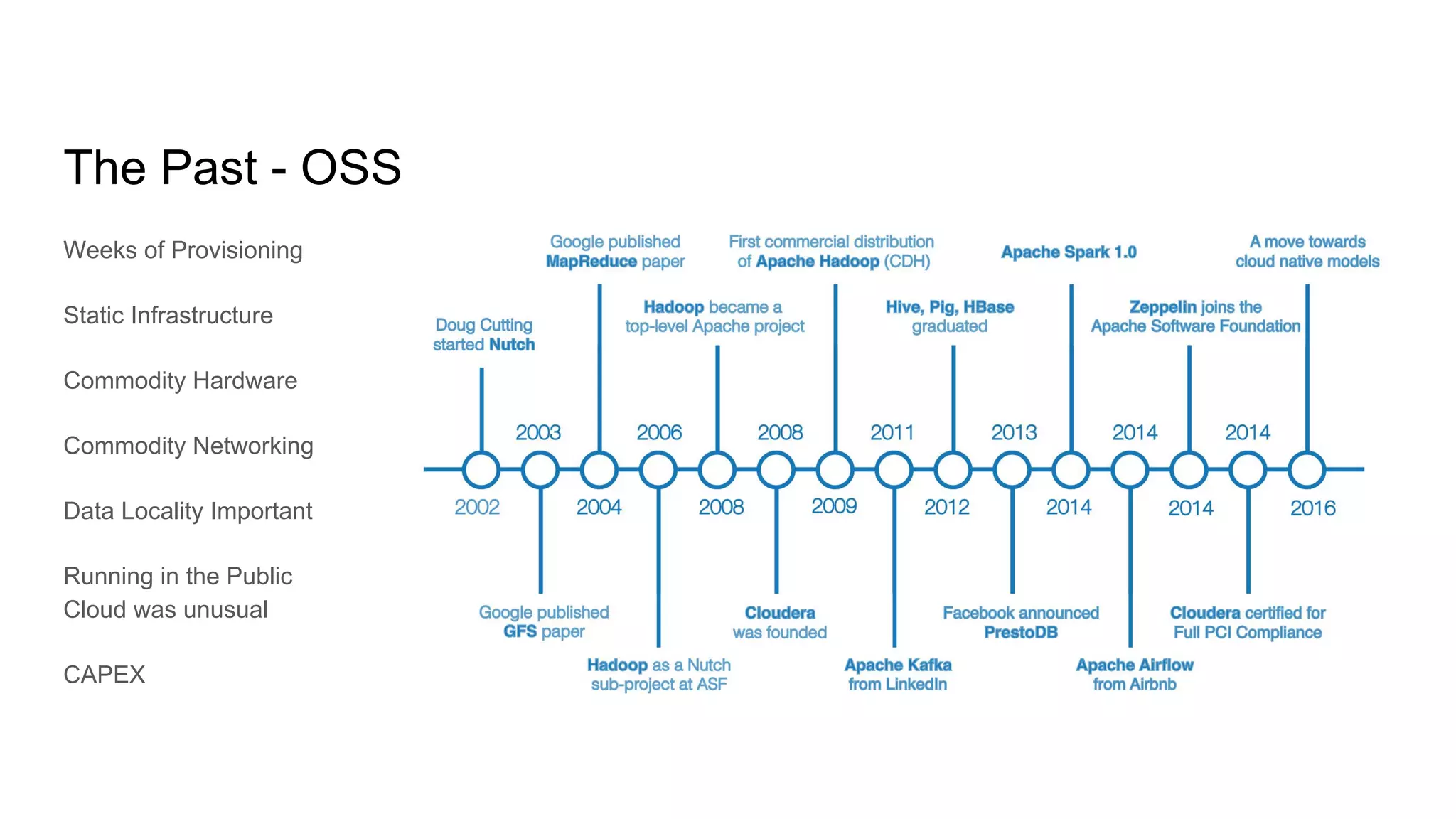
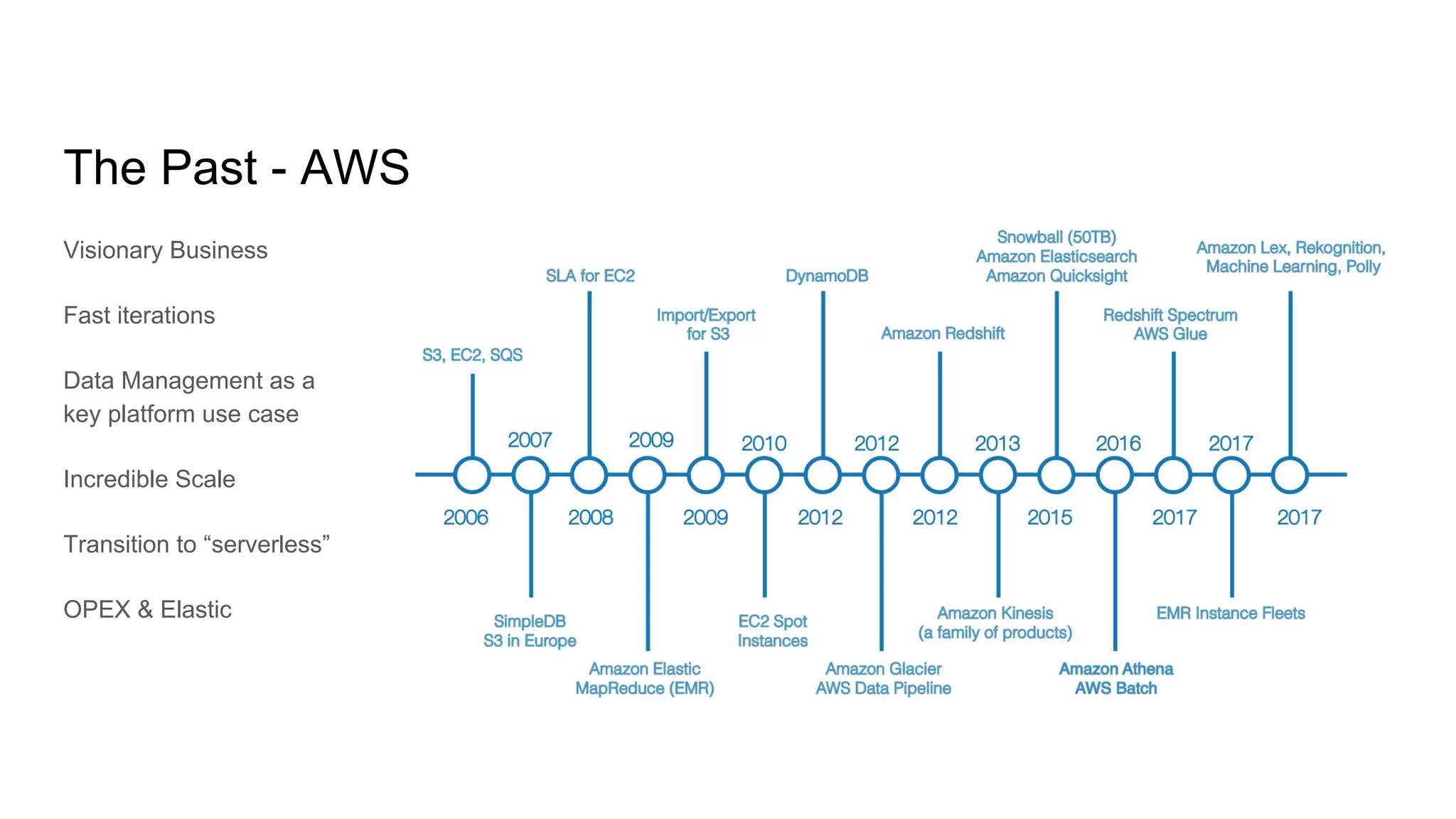
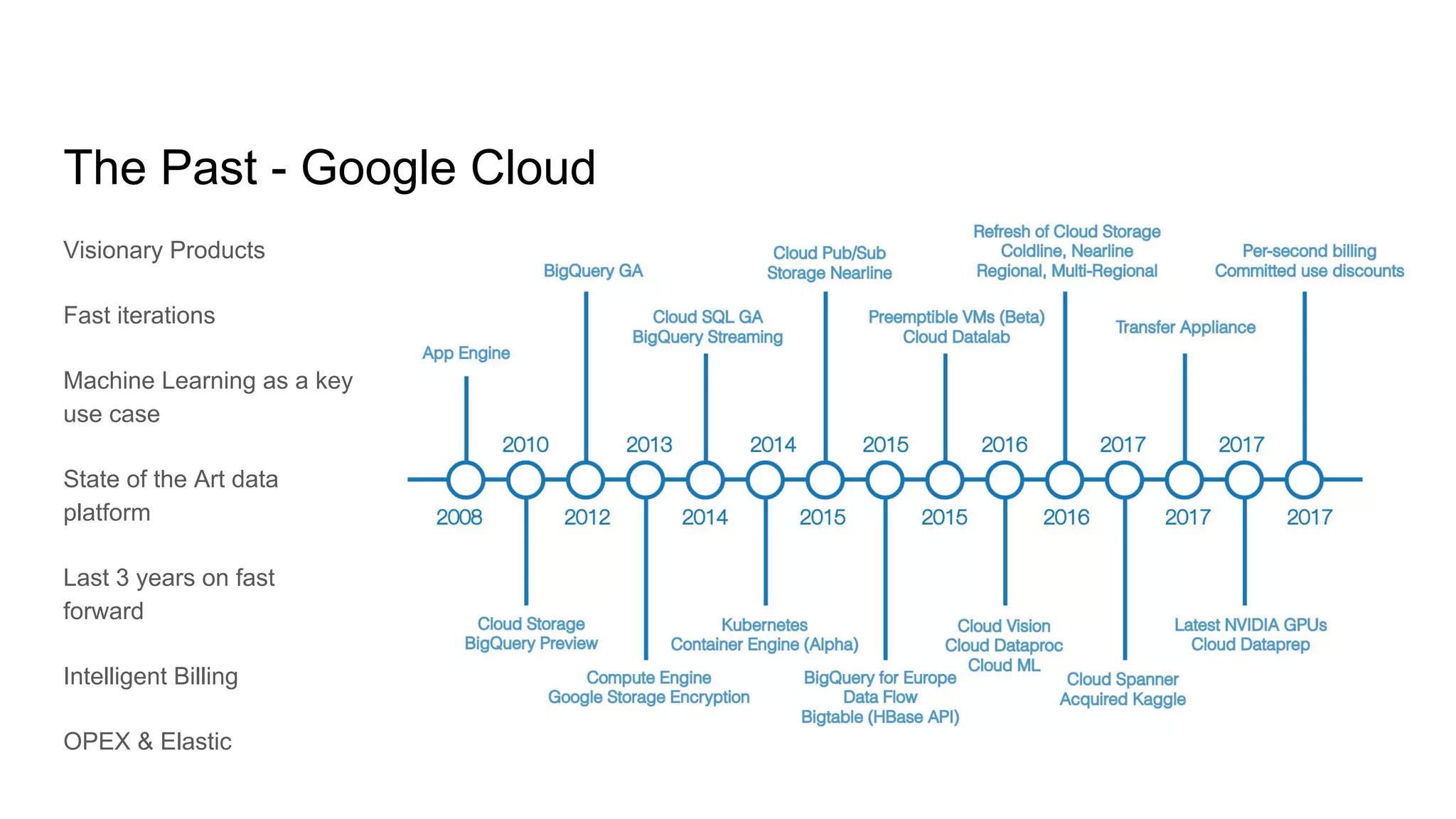




The document discusses the evolving landscape of data engineering, outlining past developments, current patterns, and future aspirations within the field. It highlights trends in cloud computing, such as serverless architectures and the importance of data locality, while also addressing the challenges of scaling and cost in data workloads. The author's wish list for the future includes advancements in data cataloging, monitoring systems, and intelligent data infrastructure solutions.























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)