Artificial Intelligence
• AIis a technology that allows machines to acquire
intelligent and inferential mechanisms like humans.
• This concept first appeared at the Dartmouth Conference
in 1956.
ANN & DLCourse objectives
Prerequisites/ Co- requisites:
• 21CS305PC – Introduction to Machine Learning Course
Course Objectives: The course will help to
• Explore the fundamentals of neural networks and characteristics of deep learning.
• Understand TensorFlow fundamentals and Familiarize students with common
functional modules in the Keras API.
• Acquire a robust theoretical and practical foundation in Neural Networks.
• Acquire knowledge about Convolutional Neural Networks (CNN) Architectures.
• Comprehend the principles of Recurrent Neural Networks (RNN).
8.
ANN & DLCourse outcomes
Course Outcomes: After learning the concepts of this course, the student is able to
•Comprehend the historical progression of deep learning, and its diverse
applications across industries.
•Gain proficiency in manipulating tensors, performing mathematical operations, and
other fundamental operations on Tensors.
•Develop ANN model for tabular data
•Develop image classification model using CNN.
•Implement Sequence learning with RNN.
9.
ANN & DLSyllabus
UNIT-I:
Introduction to Artificial Intelligence: Artificial Intelligence in Action, The History of Neural Networks, Deep Learning
Characteristics, Deep Learning Applications, Deep Learning Framework, Development Environment Installation.
Regression: Neuron Model, Optimization Method, Linear Model in Action
UNIT – II:
Introduction to Neural Networks: Definition, Inspiration from biological neural networks, Historical development,
Applications, Neural Network types.
TensorFlow: Data Types, Numerical Precision, Tensors to Be Optimized, Create Tensors, Typical Applications of
Tensors, Indexing and Slicing, Dimensional Transformation, Broadcasting, Mathematical Operations, Merge and Split,
Common Statistics, Tensor Comparison, Fill and Copy, Data Limiting, Advanced Operations, Load Classic Datasets.
Keras Advanced API: Common Functional Modules, Model Configuration, Training and Testing, Model Configuration,
Model Saving and Loading, Custom Network, Model Zoo, Metrics, Hands-On Accuracy Metric, Visualization.
10.
ANN & DLSyllabus…
UNIT-III:
Artificial Neural Networks: Perceptron, Fully Connected Layer, Neural Network, Activation function,
Design of Output Layer, Error Calculation, Types of Neural Networks, Hands-On of Automobile Fuel
Consumption Prediction.
Backward Propagation Algorithm: Derivatives and Gradients, Common Properties of Derivatives ,
Derivative of Activation Function, Gradient of Loss Function, Gradient of Fully Connected Layer, Chain
Rule, Back Propagation Algorithm, Hands-On Optimization of Himmelblau, Hands-On Back
Propagation Algorithm, Hands-On Handwritten Digital Image Recognition.
UNIT-IV:
Convolutional Neural Networks: Problems with Fully Connected, Convolutional Neural Network,
Various layers in Convolutional Neural Network, Classical Convolutional Network Architectures-
LeNet-5, AlexNet, VGG16, GooLeNet and ResNet18.
Overfitting: Model Capacity, Over fitting and Under fitting, Dataset Division, Model Design,
Regularization, Dropout, Data Augmentation, Hands-On Over fitting.
11.
ANN & DLSyllabus…
UNIT-V:
Recurrent Neural Network: Sequence Representation Method, Recurrent Neural Network,
Gradient Propagation, How to Use RNN Layers, Hands-On RNN Sentiment Classification,
Gradient Vanishing and Gradient Exploding, RNN Short-Term Memory, LSTM Principle,
How to Use the LSTM Layer, GRU, Hands-On LSTM/GRU Sentiment Classification.
TEXT BOOKS:
•Beginning Deep Learning with TensorFlow: Work with Keras, MNIST DataSets, and
Advanced Neural Networks by Liangqu Long, Xiangming Zeng, A Press, 2022.
•Deep Learning from the Basics, Koki Saitoh, Packt Publishing, 2021.
REFERENCE BOOKS:
•Deep Learning Methods and Applications by Li Deng, Dong Yu , Now Publishers Inc, 2014.
Artificial Intelligence
• AIis a technology that allows machines to acquire
intelligent and inferential mechanisms like humans.
• This concept first appeared at the Dartmouth Conference
in 1956.
16.
AI Stages
The FirstStage: Inference period
• People tried to develop intelligent systems where they
summarized and generalized some logical rules and
implemented them in the form of computer programs
• In the 1970s, scientists tried to implement AI through
knowledge database and reasoning.
• This stage is called the inference period
• One of the biggest difficulties of inference period was that
the process of human recognition of pictures and
understanding of languages cannot be replicated by
established rules.
17.
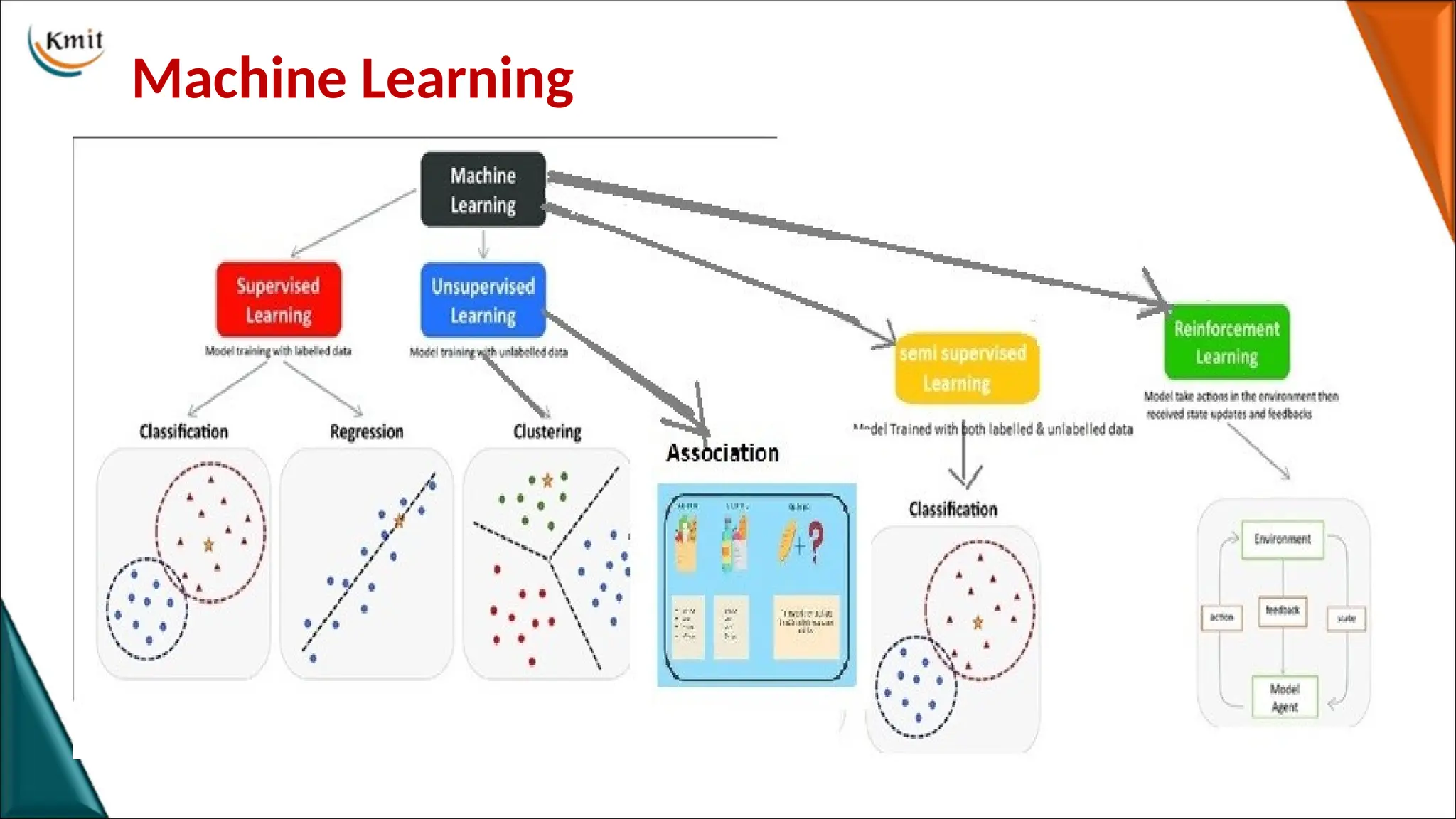
Second Stage: MachineLearning
• Machine automatically learn rules from
data, known as machine learning.
• ML became a popular subject in AI in the
1980s.
• In machine learning, there is a direction
to learn complex, abstract logic through
neural networks.
Third Stage: DeepNeural Network
• The third revival of AI was since 2012
when the applications of deep neural
network technology have made major
breakthroughs in fields like computer
vision, natural language processing (NLP)
and robotics.
The Advent ofNeural Network & Deep Learning
• Early neural networks were shallow due to the
limitation of computing power ,data volume and
network expressions.
• In later stages improvement of computing power
and the arrival of the big data and highly
parallelized graphics processing units (GPUs) and
made training of large-scale neural networks
possible.
• In 2006, Geoffrey Hinton first proposed the
concept of deep learning (which has learning
ability).
• Geoffrey Hinton is a British-Canadian cognitive
psychologist and computer scientist known as the
“godfather of AI.”
23.
The Advent ofNeural Network & Deep Learning..
• In 2012 Hinton and two of his graduate
students, Alex Krizhevsky and Ilya
Sutskever, developed an eight-layer
neural network program, which they
named AlexNet, to identify images .
• Alex Net achieved huge performance
improvements in the image recognition
competition. Since then, neural
network models with thousands of
layers have been developed
successively, showing strong learning
ability.
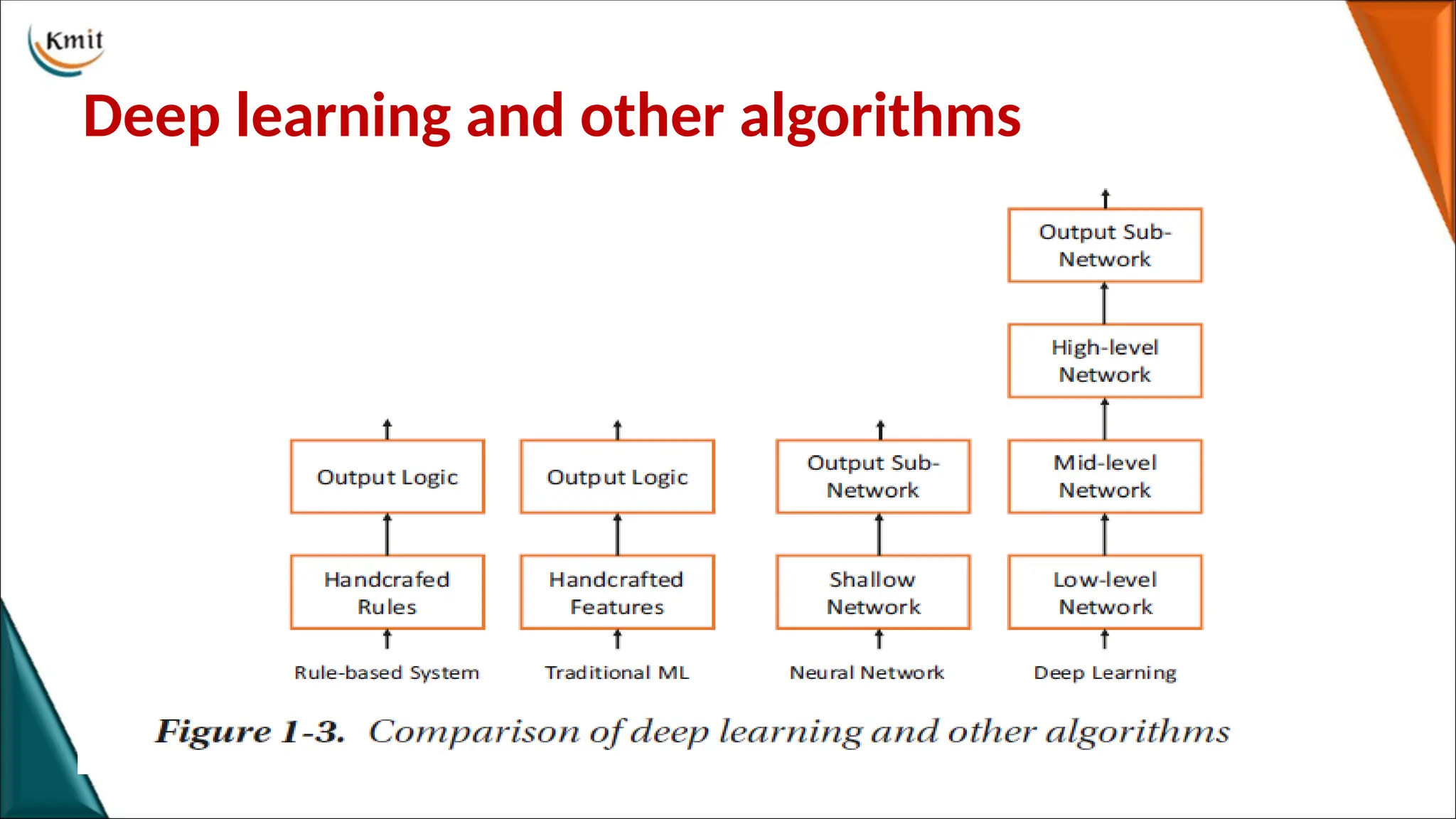
• The rule-basedsystems usually write explicit logic, which is generally designed for
specific tasks and is not suitable for other tasks.
• Traditional machine learning algorithms artificially design feature detection methods with
certain generality, such as SIFT and HOG features which are suitable for a certain type of
tasks and have certain generality. But the performance highly depends on how those
features are designed.
• The emergence of neural networks has made it possible for computers to design features
automatically through neural networks without human intervention.
• Shallow neural networks typically have limited feature extraction capability, while deep
neural networks are capable of extracting high-level, abstract features and have better
performance.
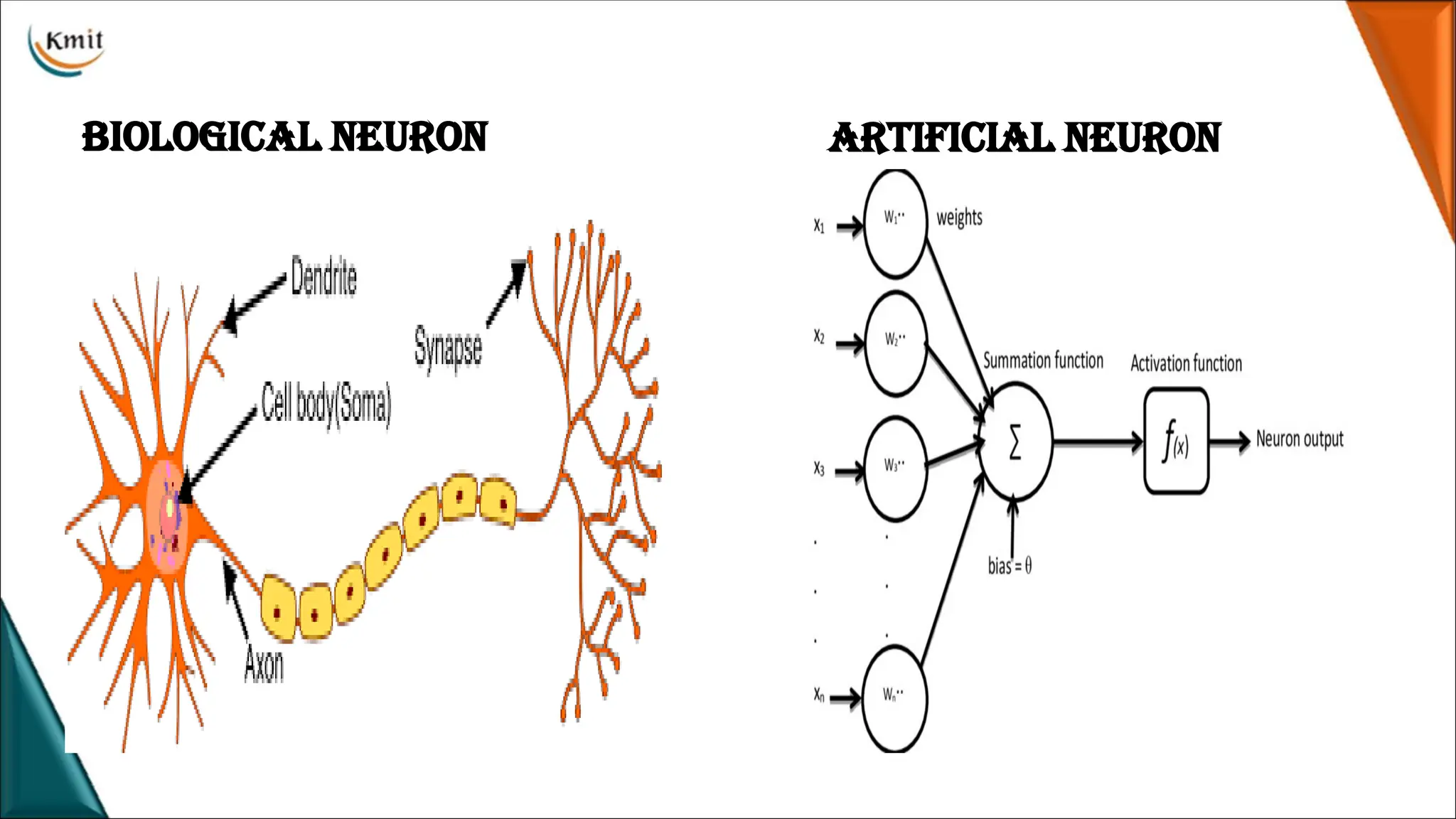
History of NeuralNetworks
Development of neural networks is divided into 2 stages, shallow neural network
stage and deep learning stage, with 2006 as the dividing point.
29.
History of NeuralNetworks….
The Shallow Neural Network :
• In 1943, psychologist Warren McCulloch and
logician Walter Pitts proposed the earliest
mathematical model of neurons based on
the structure of biological neurons, called
MP neuron model.
30.
Shallow Neural network….
•The MP model f (x) = h(g(x)),
where g(x) = Σi xi, xi {0, 1},
∈
• Activation function h(x) takes values from g(x) to predict output values as shown in
figure.
• If g(x) ≥ 0, h (x) provides output y as 1 ; if g(x) < 0, output is 0.
• The MP neuron models have no learning ability and
can only complete fixed logic judgments.
31.
History of NeuralNetworks….
• In 1958, American psychologist Frank Rosenblatt
proposed the first neuron model called as Perceptron
model which can automatically learn weights.
• The error between the output value O and the true value
y is used to adjust the weights of the neurons {w1,w2,
…,wn}.
• linear models such as perceptions cannot handle simple
linear inseparable problems such as XOR
DEEP LEARNING CHARACTERISTICS
DATAVOLUME
• The MNIST handwritten digital picture dataset contains a total of ten categories of
numbers from 0 to 9, with up to 7,000 pictures in each category
• With the rise of neural networks, especially deep learning networks, the number
of network layers is generally large, and the number of model parameters can
reach one million, ten million, or even one billion
• To prevent over fitting, the size of the training dataset is usually huge than r k
layers an model parameters are large.
• The popularity of modern social media also makes it possible to collect huge
amounts of data.
37.
COMPUTING POWER
• Thebasic theory of modern deep learning was proposed in the 1980s, but the real
potential of deep learning was not realized until the release of AlexNet based on
training on two GTX580 GPUs in 2012
• Deep learning relies heavily on parallel acceleration computing devices.
• Most of the current neural networks use parallel acceleration chips such as NVIDIA
GPU and Google TPU to train model parameters.
For example, the AlphaGo Zero program needs to be trained on 64 GPUs from scratch
for 40 days before surpassing all AlphaGo historical versions. At present, the deep
learning acceleration hardware devices that ordinary consumers can use are mainly
from NVIDIA GPU graphics cards.
38.
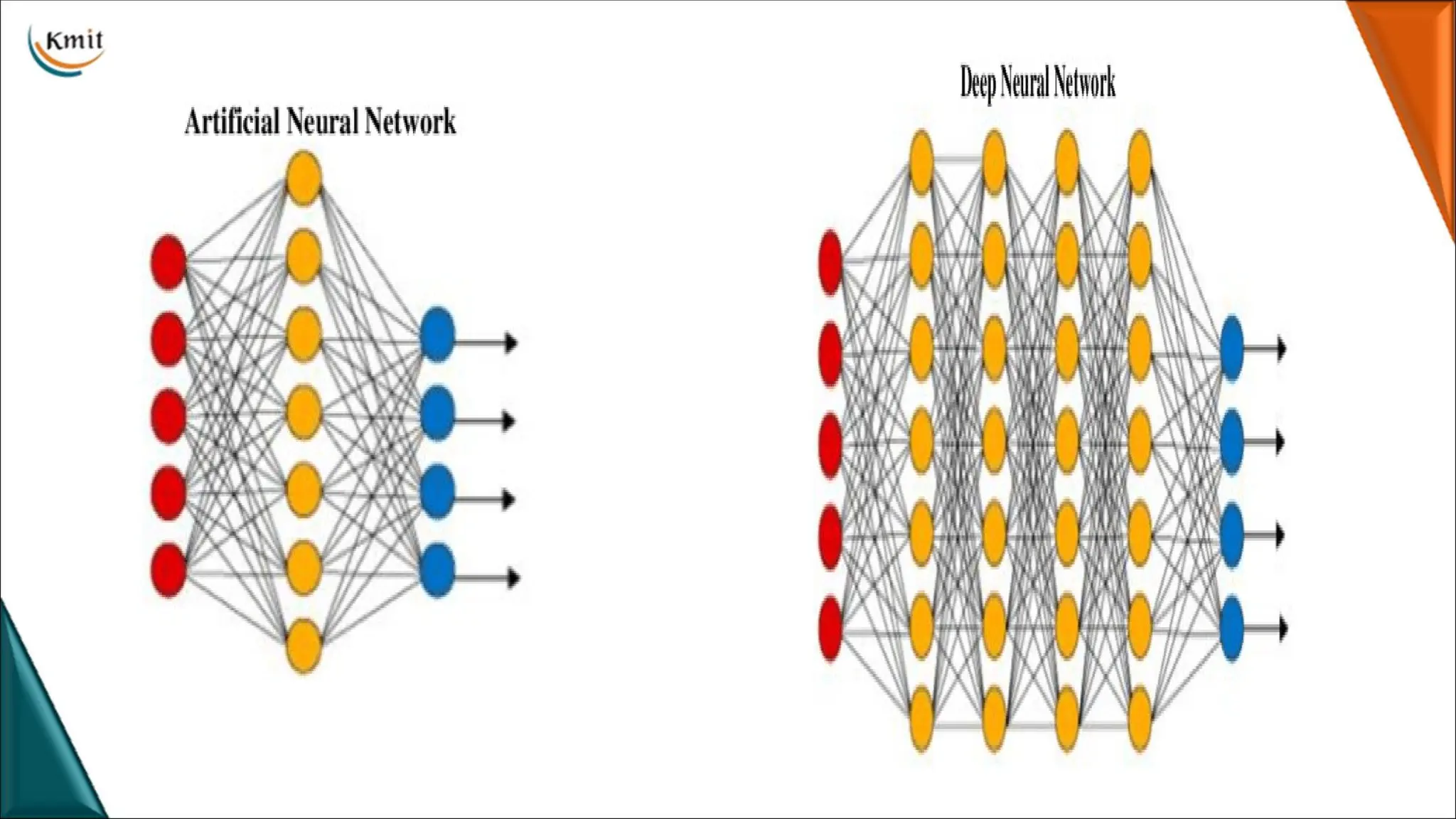
NETWORK SCALE
• Withthe development of deep learning and the improvement of computing
capabilities, models such as AlexNet (8 layers), VGG16 (16 layers), GoogleNet (22
layers), ResNet50 (50 layers), and DenseNet121 (121 layers) have been proposed
successively, while the size of inputting pictures has also gradually increased from
28×28 to 224×224 to 299×299 and even larger.
• The increase of network scale enhances the capacity of the neural networks i.e,
networks can learn more complex data and the model performance can be
improved accordingly.
• The increase of the network scale need more training data and computational
power to avoid over fitting.
40.
GENERAL INTELLIGENCE
• Designinga universal intelligent mechanism that can automatically learn and self-
adjust like the human brain has always been the common vision of human beings.
• Deep learning is one of the algorithms closest to general intelligence. In the
computer vision field, previous methods that need to design features for specific
tasks and add a priori assumptions have been abandoned by deep learning
algorithms.
• On the Atari game platform, the DQN algorithm designed by DeepMind can reach
human equivalent level in 49 games under the same algorithm, model structure,
and hyperparameter settings, showing a certain degree of general intelligence.
41.
DEEP LEARNING ANDITS APPLICATIONS
• Deep learning is a class of machine learning algorithms that uses multiple layers to
progressively extract higher-level features from the raw input.
Ex: In image processing, lower layers may identify edges, while higher layers may
identify the concepts relevant to a human such as digits or letters or faces, Scene,
Scenario.
• Deep learning algorithms have been widely used in our daily life, such as voice
assistants in mobile phones, intelligent assisted driving in cars, and face payments.
Mainstream applications of deep learning
• Computer vision
• Natural language processing
• Reinforcement learning.
43.
DEEP LEARNING APPLICATIONS
Computervision:
• In Computer Vision Image classification is a common classification.
• Image recognition is one of the earliest successful applications of deep learning.
Classic neural network models include VGG series, Inception series, and ResNet
series
44.
Computer vision…….
Object detectionrefers to the automatic
detection of the approximate location of
common objects in a picture by an
algorithm.
• It is usually represented by a
bounding box and classifies the
category information of objects in the
bounding box, as shown in Figure.
• Common object detection algorithms
are RCNN, Fast RCNN, Faster RCNN,
Mask RCNN,SSD, and YOLO series.
Figure: Object detection example
45.
Computer vision…….
Semantic segmentationis an algorithm to
automatically segment and identify the
content in a picture.
• We can understand semantic
segmentation as the classification of
each pixel and analyze the category
information of each pixel, as shown in
Figure.
• Common semantic segmentation
models include FCN, U-net, SegNet,
and DeepLab series.
Figure: Semantic segmentation example
46.
Computer vision…….
• VideoUnderstanding: As deep learning
achieves better results on 2D picture–
related tasks.
• 3D video understanding tasks with
temporal dimension information (the
third dimension is sequence of frames)
are receiving more and more attention.
• Common video understanding tasks
include video classification, behavior
detection, and video subject extraction.
Common models are C3D, TSN, DOVF,
and TS_LSTM.
47.
Computer vision…….
• Imagegeneration learns the distribution of
real pictures and samples from the learned
distribution to obtain highly realistic
generated pictures.
• At present, common image generation
models include VAE series and GAN series.
• GAN series of algorithms have made great
progress in recent years.
• GAN model has reached a level where it is
difficult to distinguish the authenticity with
the naked eye. GAN model generated picture
48.
Natural Language Processing
Naturallanguage processing (NLP) is a machine learning
technology that gives computers the ability to interpret,
manipulate, and comprehend human language.
1.Machine Translation
2.Chatbots
49.
Natural Language Processing….
MachineTranslation:
• In November 2016, Google launched the Google Neural
Machine Translation (GNMT) system based on the
Seq2Seq model. the direct translation technology from
source language to target language was realized with
50–90% improvement on multiple tasks.
• Commonly used machine translation models are
Seq2Seq, BERT, GPT, and GPT-2.
50.
Natural Language Processing….
Chatbotis also a mainstream task of natural language
processing.
• Machines automatically learn to talk to humans,
provide satisfactory automatic responses to simple
human demands, and improve customer service
efficiency and service quality.
• Chatbot is often used in consulting systems,
entertainment systems, and smart homes.
51.
Reinforcement Learning
• Reinforcementlearning is based on
rewarding desired behaviors and/or
punishing undesired ones.
• The agent learns that what actions lead to
positive feedback /rewards and what
actions lead to negative feedback/ penalty.
• Since there is no labeled data, so the agent
is bound to learn by its experience only.
• RL solves a specific type of problem where
decision making is sequential, and the goal
is long-term, such as games, robotics, etc.
52.
Reinforcement Learning…
Virtual Games:
•Commonly used reinforcement learning algorithms are DQN, A3C,
A2C, and PPO.
• The intelligent programs developed by OpenAI and DeepMind
have also defeated professional teams under restriction rules.
Robotics:
In the real environment, the control of robots has also made some
progress.
Ex: UC Berkeley Lab has made a lot of progress in the areas of
imitation learning, meta learning, and few-shot learning in the field of
robotics.
• Boston Dynamics has made gratifying achievements in robot
applications.
• The robots it manufactures perform well on tasks such as complex
terrain walking and multi-agent collaboration
53.
Reinforcement Learning…
• Autonomousdriving is considered as an
application direction of reinforcement
learning.
• Many companies have invested a lot of
resources in autonomous driving, such as
Baidu, Uber, and Google.
• Apollo from Baidu has begun trial
operations in Beijing, Xiong’an,
Wuhan,and other places.
54.
Deep Learning Frameworks
Theanois one of the earliest deep learning
frameworks.Developed by Yoshua Bengio and Ian
Goodfellow.
• Theano is a Python-based computing library
for positioning low-level operations.
• Theano supports both GPU and CPU
operations.
• Due to Theano’s low development efficiency,
long model compilation time,and developers
switching to TensorFlow
• Theano has now stopped maintenance.
55.
Deep Learning Frameworks
Scikit-learnis a complete computing library
for machine learning algorithms.
• Built-in support for common traditional
machine learning algorithms, and it has
rich documentation and examples
• Scikitlearn is not specifically designed for
neural networks.
• It does not support GPU acceleration, and
the implementation of neural network–
related layers is also lacking
57.
CLASSIFICATION
• Consider handwrittendigital picture recognition as shown below
• A picture contains h rows and w columns with h×w pixel values. Generally, pixel values are
integers ranging from 0 to 255 to express color intensity information. For example, 0
represents the lowest intensity, and 255 indicates the highest intensity.
• If it is a color picture, each pixel contains the intensity information of the three channels R, G,
and B, which, respectively, represent the color intensity of colors red, green, and blue
58.
• Each pixelof a color picture is
represented by a one-dimensional vector
with three elements, which represent
the intensity of R, G, and B colors.
• As a result, a color image is saved as a
tensor with dimension [h, w, 3], while a
gray scale picture only needs a two-
dimensional matrix with shape [h, w] or
a three-dimensional tensor with shape
[h, w, 1] to represent its information.
• The matrix content of a picture for
number 8. It can be seen that the black
pixels in the picture are represented by
0 and the gray scale information is
represented by 0–255.
• The whiter pixels in the picture
correspond to the larger values in the
matrix.
59.
• Steps todownload, manage, and load the MNIST dataset
60.
NOTE:
• We usea matrix of shape [h, w] to represent a picture.
• For multiple pictures, we can add one more dimension in front and use a tensor of
shape [b,h, w] to represent them.
• Here b represents the batch size.
• Color pictures can be represented by a tensor with the shape of [b, h, w, c],
where c represents the number of channels, which is 3 for color pictures.
61.
CLASSIFICATION- BUILDING AMODEL
• Consider ‘x’ as the the input. If it is single input scalar then the model can be
expressed as y=xw+b.
• For multi input single output model structure expression becomes
Where
63.
Consider two sampleswith din = 3 and dout = 2.
Above equation is expanded as follows:
where superscripts like (1) and (2) represent the sample index and subscripts such as 1 and 2
indicate the elements of a certain sample vector.
The corresponding model structure is shown below
64.
• A grayscaleimage is stored using a matrix with shape [h, w], and b pictures are stored using a tensor
with shape [b, h, w].
• However, our model can only accept vectors, so we need to flatten the [h, w] matrix into a vector of
length [h ⋅ w], as shown in Figure below, where the length of the input features din = h ⋅ w.
65.
• The outputactually can be set to a set of vectors with length dout, where dout is the same as
the number of categories.
• For example, if the output belongs to the first category, then the corresponding index is set
to 1, and the other positions are set to 0.
Figure: One Hot Encoding
66.
ERROR CALCULATION
• Forclassification problems, our goal is to maximize a certain performance metric,
such as accuracy.
• But when accuracy is used as a loss function, it is in fact indifferentiable. As a result,
the gradient descent algorithm cannot be used to optimize the model parameters.
• For the error calculation of a classification problem, it is more common to use the
cross entropy loss function instead of the mean squared error loss function
introduced in the regression problem.
67.
MAJOR ISSUES inHandwritten digital picture recognition problems are:
1. A linear model is not enough because:
– It is one of the simplest models in machine learning.
– It has only a few parameters
– It can only express linear relationships.
• The perception and decision-making of complex brains are far more complex than a linear
model.
2. Complexity:
• It is the model ability to approximate complex distributions.
• The preceding solution only uses a one-layer neural network model composed of a small
number of neurons.
• Compared with the 100 billion neuron interconnection structure in the human brain, its
generalization ability is obviously weaker.
68.
Example of modelcomplexity and data distribution:
• The distribution of sampling points with observation errors is plotted. The actual
distribution may be a quadratic parabolic model.
• If you use a linear model to fit the data, it is difficult to learn a good model.
• If you use a suitable polynomial function model to learn, such as a quadratic
polynomial, you can learn a suitable model.
• But when the model is too complex, such as a ten-degree polynomial, it is likely to
overfit and hurt the generalization ability of the model
69.
NON LINEAR MODEL
•Since a linear model is not feasible, we can embed a nonlinear function in the linear
model and convert it to a nonlinear model.
• Nonlinear function can be called as the activation function, which is represented
by σ:
o= σ(Wx+b)
70.
Activation Function:
• Activationfunctions introduce non-linearities into the network, allowing it to learn
complex patterns in the data.
• Common activation functions are ReLU, Sigmoid, Tanh etc.
71.
• The ReLUfunction only retains the positive part of function y = x and sets the
negative part to be zeros.
• It has a unilateral suppression characteristic. Although simple, the ReLU function
has excellent nonlinear characteristics, easy gradient calculation, and stable
training process.
• It is one of the most widely used activation functions for deep learning models.
• convert the model to a nonlinear model by embedding the ReLU function:
o = ReLU( Wx+ b )
72.
Model Complexity:
• Toincrease the model complexity, we can repeatedly stack multiple transformations
such as:
In the preceding equations, we take:
• the output value h1 of the first-layer neuron as the input of the second-layer
neuron .
• Then take the output h2 of the second-layer neuron as the input of the third-layer
neuron.
• The output of the last-layer neuron is the model output.
73.
• The layerwhere the input node x is located the
input layer.
• The output of each nonlinear module hi along
with its parameters Wi and bi is called a
network layer.
• In particular, the layer in the middle of the
network is called the hidden layer, and the last
layer is called the output layer.
• This network structure formed by the
connection of a large number of neurons is
called a neural network.
• The number of nodes in each layer and the
number of layers determine the complexity of
the neural network.
74.
OPTIMISATION METHOD:CLASSIFICATION
• Optimizationmethods similar to regression can also be used to solve classification
problems.
• For a network model with single layer :
• Derive the partial derivative expression of and then calculate the
gradient for each step and update the parameters w and b using the gradient descent
algorithm.
• As complex nonlinear functions are embedded, the number of network layers and the
length of data features also increase.
• The model becomes very complicated, and it is difficult to manually derive the
gradient expressions.
75.
• Once thenetwork structure changes, the model function and corresponding
gradient expressions also change. Therefore, it is not feasible to rely on the manual
calculation of the gradient.
• Solution to this problem is deep learning frameworks.
• With the help of auto differentiation technology, deep learning frameworks can
build the neural network’s computational graph during the calculation of each
layer’s output corresponding loss function and then automatically calculate the
gradient of any parameter θ.
• The gradient will automatically be calculated and updated, which is very convenient
and efficient to use.





















































![• Each pixel of a color picture is
represented by a one-dimensional vector
with three elements, which represent
the intensity of R, G, and B colors.
• As a result, a color image is saved as a
tensor with dimension [h, w, 3], while a
gray scale picture only needs a two-
dimensional matrix with shape [h, w] or
a three-dimensional tensor with shape
[h, w, 1] to represent its information.
• The matrix content of a picture for
number 8. It can be seen that the black
pixels in the picture are represented by
0 and the gray scale information is
represented by 0–255.
• The whiter pixels in the picture
correspond to the larger values in the
matrix.](https://image.slidesharecdn.com/anndlunit1anil13-250919131103-142d4688/75/ANN-DL-UNIT-1-ANIL-13-10-24-pptxjjjjjjjjj-58-2048.jpg)

![NOTE:
• We use a matrix of shape [h, w] to represent a picture.
• For multiple pictures, we can add one more dimension in front and use a tensor of
shape [b,h, w] to represent them.
• Here b represents the batch size.
• Color pictures can be represented by a tensor with the shape of [b, h, w, c],
where c represents the number of channels, which is 3 for color pictures.](https://image.slidesharecdn.com/anndlunit1anil13-250919131103-142d4688/75/ANN-DL-UNIT-1-ANIL-13-10-24-pptxjjjjjjjjj-60-2048.jpg)



![• A grayscale image is stored using a matrix with shape [h, w], and b pictures are stored using a tensor
with shape [b, h, w].
• However, our model can only accept vectors, so we need to flatten the [h, w] matrix into a vector of
length [h ⋅ w], as shown in Figure below, where the length of the input features din = h ⋅ w.](https://image.slidesharecdn.com/anndlunit1anil13-250919131103-142d4688/75/ANN-DL-UNIT-1-ANIL-13-10-24-pptxjjjjjjjjj-64-2048.jpg)


































































![Pollution.ppt [Autosaved].ppt yogesh kumbhar](https://cdn.slidesharecdn.com/ss_thumbnails/pollution-251205194856-d30cfee8-thumbnail.jpg?width=640&height=640&fit=bounds)





