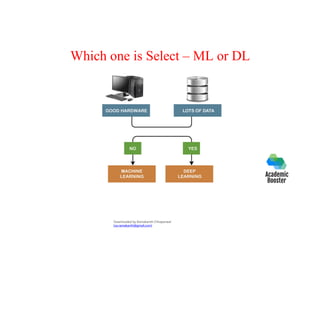
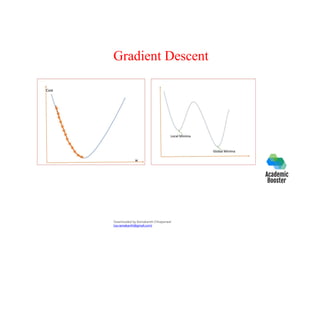
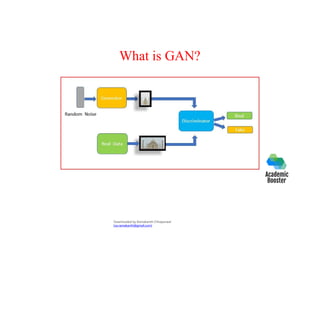
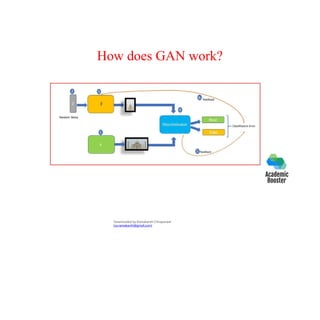
The document provides an overview of deep learning, its distinction from traditional machine learning, and its various models such as shallow and deep neural networks. It also discusses crucial concepts like logistic regression, gradient descent, and regularization techniques, alongside practical applications and hardware/software requirements for implementing deep learning effectively. Additionally, it highlights the importance of data quality and characteristics in training deep learning models.